聚类:一种无监督学习,是先不知道类别,自动将相似的对象归到同一簇中
根据欧式距离选择较近的几个点判断类别
欧式距离计算公式
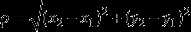
其中K是事先给定的,这个K值的选定是非常难以估计的,事先并不知道给定的数据集应该分为多少个类别才算合适(ISODATA算法通过类的自动合并和分裂,得到较为合理的类型数目K)
K-Means算法需要用初始随机种子点,这个随机种子点很重要,不同的随机种子点会得到完全不同的效果(K-Means++算法可以用来解决这个问题,可以有效的选择初始点)
n_clustercluster_std半监督学习,用小的数据训练,来预测较大的数据
import sklearn.datasets as dataset
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x_train,target = dataset.make_blobs(n_samples=200,centers=3)
kmn = KMeans(n_clusters=3)
kmn.fit(x_train)
y_new = kmn.predict(x_train)
centers = kmn.cluster_centers_
plt.figure(figsize=(16,9))
plt.subplot(221)
plt.scatter(x_train[:,0],x_train[:,1],c=y_new) #预测分类
plt.scatter(centers[:,0],centers[:,1],c='r',s=100,alpha=0.6)
plt.subplot(222)
plt.scatter(x_train[:,0],x_train[:,1],c=target)
plt.savefig('k.png')原文:https://www.cnblogs.com/focusTech/p/12340069.html