1. 搞懂关联规则中的几个重要概念:支持度、置信度、提升度;
2. Apriori 算法的工作原理;
3. 在实际工作中,我们该如何进行关联规则挖掘。
Apriori 算法的核心就是理解频繁项集和关联规则。在算法运算的过程中,还要重点掌握对
支持度、置信度和提升度的理解。
超市购物的例子,下面是几名客户购买的商品列表:
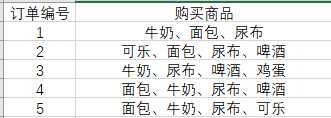
支持度是个百分比,它指的是某个商品组合出现的次数与总次数之间的比例。支持度越
高,代表这个组合出现的频率越大。
在这个例子中,我们能看到“牛奶”出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就
是 4/5=0.8。
同样“牛奶 + 面包”出现了 3 次,那么这 5 笔订单中“牛奶 + 面包”的支持度就是
3/5=0.6。
它指的就是当你购买了商品 A,会有多大的概率购买商品 B,在上面这个例子中:
置信度(牛奶→啤酒)=2/4=0.5,代表如果你购买了牛奶,有多大的概率会购买啤酒?
置信度(啤酒→牛奶)=2/3=0.67,代表如果你购买了啤酒,有多大的概率会购买牛奶?
我们能看到,在 4 次购买了牛奶的情况下,有 2 次购买了啤酒,所以置信度 (牛奶→啤酒)=0.5,
而在 3 次购买啤酒的情况下,有 2 次购买了牛奶,所以置信度(啤酒→牛奶)=0.67。
所以说置信度是个条件概念,就是说在 A 发生的情况下,B 发生的概率是多少。
我们在做商品推荐的时候,重点考虑的是提升度,因为提升度代表的是“商品 A 的出现,
对商品 B 的出现概率提升的”程度。
提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升。
所以提升度有三种可能:
1. 提升度 (A→B)>1:代表有提升;
2. 提升度 (A→B)=1:代表有没有提升,也没有下降;
3. 提升度 (A→B)<1:代表有下降。
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
就是支持度大于等于最小支持度 (Min Support) 阈值的项集
例如A与B出现的概率很高
data数据集是列表形式,里面每一个值可以是集合或者列表
k=1时,单个商品
例如啤酒
{1:{(‘啤酒‘,):3,(‘尿布’,):5}
2:{(‘啤酒’,‘尿布’):3,}
}
from efficient_apriori import apriori
# 设置数据集
data = [(‘牛奶‘,‘面包‘,‘尿布‘),
(‘可乐‘,‘面包‘, ‘尿布‘, ‘啤酒‘),
(‘牛奶‘,‘尿布‘, ‘啤酒‘, ‘鸡蛋‘),
(‘面包‘, ‘牛奶‘, ‘尿布‘, ‘啤酒‘),
(‘面包‘, ‘牛奶‘, ‘尿布‘, ‘可乐‘)]
# 挖掘频繁项集和频繁规则
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
print(itemsets)
print(rules)
data 是个 List 数组类型,其中每个值都可以是一个集合。实际上你
也可以把 data 数组中的每个值设置为 List 数组类型,比如:
data = [[‘牛奶‘,‘面包‘,‘尿布‘],
[‘可乐‘,‘面包‘, ‘尿布‘, ‘啤酒‘],
[‘牛奶‘,‘尿布‘, ‘啤酒‘, ‘鸡蛋‘],
[‘面包‘, ‘牛奶‘, ‘尿布‘, ‘啤酒‘],
[‘面包‘, ‘牛奶‘, ‘尿布‘, ‘可乐‘]]
# 挖掘频繁项集和关联规则
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
print(itemsets)
print(rules)
最小支持度和最小置信系数,这样我们可以找到支持度大于 50%,置信系数为 1 的频繁项集和关联规则。
你能看出来,宁浩导演喜欢用徐峥和黄渤,并且有徐峥的情况下,一般都会用黄渤。
Apriori原理为:如果某一项集是频繁的,则它的所有子集也是频繁的,反之,如果某一项集是非频繁的,则其所有超集也是非频繁的。
生成关联规则需要:频繁项集列表、包含频繁项集支持数据的字典、最小可信度。
用更高效的方法来进行挖掘频繁项集:使用FP-growth算法来高效发现频繁项集
互联网在处理庞大的用户数据时就是使用FP-growth算法,来发现频繁项集,找出经常一起出现的词对。
导演是如何选择演员的
https://movie.douban.com/
在豆瓣电影中输入导演名字
周星驰
采用Python,进行爬虫
1111
原文:https://www.cnblogs.com/foremostxl/p/12309809.html
