三、误差逆传播算法(BP)
3、固定增量与批量
固定增量: 逐样本,计算误差,更新权重
批量:所有训练数据,计算平均误差,更新权重。

4、权值的初始化
权值的初始值决定了搜索的七点,其值不能太大,如果权值太大,sigmoid函数的输入很大,输出接近0或1,这时梯度很小,学习速度很慢。如果权值很大(靠近1或-1),那么对于sigmoid函数的输入可能会靠近(1或-1),所以神经元的输出是0或1,这时sigmoid函数是饱和的,达到了最大值或最小值,这意味着梯度很小,学习速度很慢。
MLP算法默认权重使用很小的随机数来初始化。一个常用的技巧是将权值设置在如下的范围内(n是输入层的结点数):
![]()
5、输出层激活函数
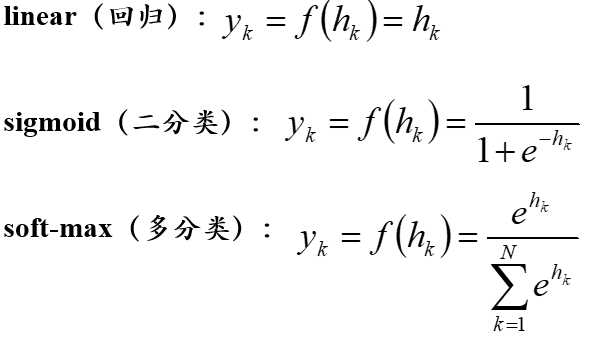
对于多分类问题,通常输出层神经元通常使用soft-max函数,输出层神经元的个数等于类别的个数,同时样本的输出要采用1 of N (1元热键编码方式)。

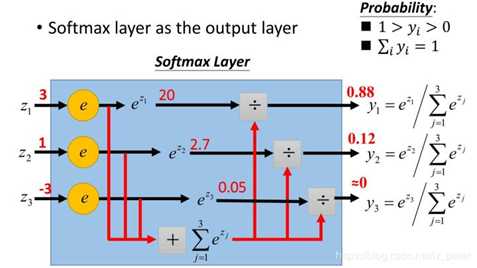
6、损失函数
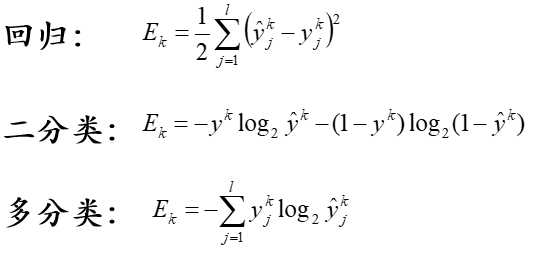
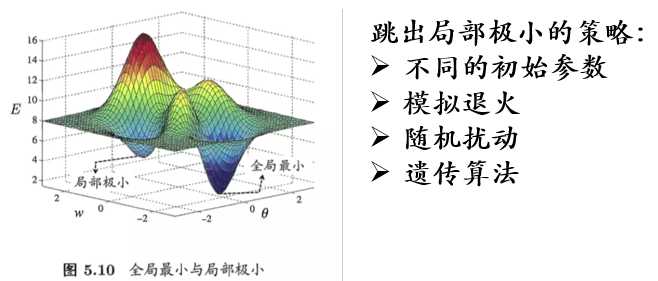
7、全局最小与局部最小
局部极小:邻域点误差函数值均不小于该点的函数值。
全局最小:参数空间内所有点的误差函数值均不小于该点的误差函数值。
参数空间内梯度为0的点对应局部极小点,可能存在多个局部极小点,但只会有一个全局最小点。也就说全局最小点一定是局部极小点,反之则不成立。
在梯度下降法中,当梯度等于0的时候,参数就不会发生改变,这个点对应的是局部极小点,因此利用梯度下降法只能找到一个局部极小点,如果损失函数是凸函数,那么只有一个局部极小点,局部极小点就是全局最小,如果损失函数不是凸函数,那么我们找到的就是局部极小点而不是全局最优,由于初始值不同,利用梯度下降法,可以找到不同的局部叫小店,我们可以比较这些局部最优,从而找出全局最优。
8、Keras
keras是一个高层神经网络API,完全由Python编写,使用keras,我们可以将精力放置再如何构建模型上。序贯模型(Sequential)是多个网络层的堆叠,是常见的一种模型。通过Keras构建神经网络模型的步骤如下:
(1)定义模型:创建一个序贯模型并添加配置层。
(2)编译模型:指定损失函数核优化器,并调用模型的compile函数,完成模型编译。
(3)训练模型:通过调用模型的fit函数来训练模型。
(4)执行预测:调用模型的evaluate或predict函数对新数据进行预测。
#创建一个序贯模型 model = Sequential() #Dense创建一个全连接层 model.add(Dense(12,input_dim=8,activation=‘relu‘)) model.add(Dense(8,activation=‘relu‘)) model.add(Dense(1,activation=‘sigmoid‘))
9、keras应用实例:
(1)利用keras构建MLP进行二分类:
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from keras.models import Sequential from keras.layers import Dense #读取数据 filename = ‘pima_data.csv‘ names = [‘preg‘,‘plas‘,‘blood‘,‘skin‘,‘insulin‘,‘bmi‘,‘pedi‘,‘age‘,‘class‘] data = pd.read_csv(filename,names=names) array = data.values X=array[:,:-1] Y=array[:,-1] test_size = 0.3 seed = 4 X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=test_size,random_state=seed) #构建神经网络模型 model = Sequential() model.add(Dense(12,input_dim=8,activation=‘relu‘)) model.add(Dense(8,activation=‘relu‘)) model.add(Dense(1,activation=‘sigmoid‘)) model.summary() model.compile(loss=‘binary_crossentropy‘,optimizer=‘adam‘,metrics=[‘accuracy‘]) model.fit(X_train,Y_train,epochs=20,batch_size=20,verbose=True) score=model.evaluate(X_test,Y_test,verbose=False) print(‘accuracy:%.2f%%‘ % (score[1]*100))
(2)keras构建MLP进行多分类任务:
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import OneHotEncoder from sklearn.datasets import load_iris #from sklearn.preprocessing import OneHotEncoder from keras.models import Sequential from keras.layers import Dense from keras.utils import np_utils #读取数据 dataset = load_iris() X=dataset.data Y=dataset.target Y=np_utils.to_categorical(Y) test_size = 0.3 seed = 4 X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=test_size,random_state=seed) #构建神经网络模型 model = Sequential() model.add(Dense(4,input_dim=4,activation=‘relu‘)) model.add(Dense(6,activation=‘relu‘)) model.add(Dense(3,activation=‘softmax‘)) model.summary() model.compile(loss=‘categorical_crossentropy‘,optimizer=‘adam‘,metrics=[‘accuracy‘]) history=model.fit(X_train,Y_train,epochs=150,batch_size=10,verbose=False) score=model.evaluate(X_test,Y_test) print(‘loss:%.2f,acc:%.2f%%‘ % (score[0],score[1]*100)) #模型训练过程可视化 print(history.history.keys()) plt.plot(history.history[‘acc‘]) plt.title(‘model accuracy‘) plt.xlabel(‘epoch‘) plt.ylabel(‘accuracy‘) plt.legend([‘train‘,‘validation‘],loc=‘upper left‘) plt.show() plt.plot(history.history[‘loss‘]) plt.title(‘model loss‘) plt.xlabel(‘epoch‘) plt.ylabel(‘loss‘) plt.legend([‘train‘,‘validation‘],loc=‘upper left‘) plt.show() from keras.models import model_from_json #将模型的结构存储再json文件中 model_json = model.to_json() with open(‘model.json‘,‘w‘) as file: file.write(model_json) model.save_weights(‘model.json.h5‘) #加载Json文件中模型 with open(‘model.json‘,‘r‘) as file: model_json = file.read() #加载模型 new_model = model_from_json(model_json) new_model.load_weights(‘model.json.h5‘) new_model.compile(loss=‘categorical_crossentropy‘,optimizer=‘adam‘,metrics=[‘accuracy‘]) score=new_model.evaluate(X_test,Y_test) print(‘loss:%.2f,acc:%.2f%%‘ % (score[0],score[1]*100))
(3)利用keras构建神经网络进行回归分析
from sklearn.model_selection import train_test_split from sklearn.datasets import load_boston from sklearn.preprocessing import StandardScaler from keras.models import Sequential,model_from_json from keras.layers import Dense #读取数据 dataset = load_boston() X=dataset.data Y=dataset.target scalar = StandardScaler() scalar.fit(X) scalar.transform(X) seed = 7 X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.3,random_state=seed) #构建神经网络模型 model = Sequential() model.add(Dense(13,input_dim=13,activation=‘relu‘)) model.add(Dense(1,activation=‘linear‘)) model.compile(loss=‘mean_squared_error‘,optimizer=‘adam‘) model.fit(X_train,Y_train,epochs=150,batch_size=10) score=model.evaluate(X_test,Y_test) print(score)
(4)手写数字识别-MLP
from keras.datasets import mnist import matplotlib.pyplot as plt from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense (X_train,y_train),(X_test,y_test)=mnist.load_data() #数据展示 plt.subplot(221) plt.imshow(X_train[0],cmap=plt.get_cmap(‘gray‘)) plt.subplot(222) plt.imshow(X_train[1],cmap=plt.get_cmap(‘gray‘)) plt.subplot(223) plt.imshow(X_train[2],cmap=plt.get_cmap(‘gray‘)) plt.subplot(224) plt.imshow(X_train[3],cmap=plt.get_cmap(‘gray‘)) plt.show() #将二维数据变为一维数据flatten扁平化 num_pixels = X_train.shape[1]*X_train.shape[2] X_train=X_train.reshape(-1,num_pixels).astype(‘float32‘) X_test = X_test.reshape(-1,num_pixels).astype(‘float32‘) #格式化数据0~1 X_train = X_train/255 X_test = X_test/255 #进行one-hot编码 y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) num_classes = y_test.shape[1] #构建模型 model = Sequential() model.add(Dense(784,input_dim=num_pixels,activation=‘relu‘)) model.add(Dense(num_classes,activation=‘softmax‘)) model.compile(loss=‘categorical_crossentropy‘,optimizer=‘adam‘,metrics=[‘accuracy‘]) model.fit(X_train,y_train,epochs=2,batch_size=200) scores = model.evaluate(X_test,y_test) print(‘acc:%.2f%%‘ % (scores[1]*100))
《机器学习(周志华)》笔记--神经网络(5)--误差逆传播算法(BP):固定增量与批量、权值的初始化、输出层激活函数、损失函数、全局最小与局部最小、Keras
原文:https://www.cnblogs.com/lsm-boke/p/12312030.html