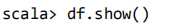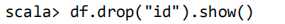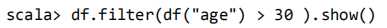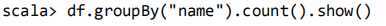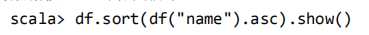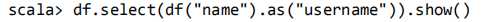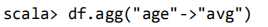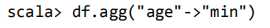[首页]
[文章]
[教程]
首页
Web开发
Windows开发
编程语言
数据库技术
移动平台
系统服务
微信
设计
布布扣
其他
数据分析
首页
>
其他
> 详细
spark实验五
时间:
2020-02-14 09:44:46
阅读:
95
评论:
0
收藏:
0
[点我收藏+]
1.Spark SQL 基本操作
将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并保存命名为 employee.json。
{ "id":1 ,"name":" Ella","age":36 }
{ "id":2,"name":"Bob","age":29 }
{ "id":3 ,"name":"Jack","age":29 }
{ "id":4 ,"name":"Jim","age":28 }
{ "id":5 ,"name":"Damon" }
{ "id":5 ,"name":"Damon" }
首先为
employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
创建 DataFrame
查询 DataFrame 的所有数据:
查询所有数据,并去除重复的数据:
查询所有数据,打印时去除 id 字段:
筛选 age>20 的记录:
将数据按 name 分组:
将数据按 name 升序排列:
取出前 3 行数据:
查询所有记录的 name 列,并为其取别名为 username:
查询年龄 age 的平均值:
查询年龄 age 的最小值:
spark实验五
原文:https://www.cnblogs.com/muailiulan/p/12306249.html
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年09月23日 (328)
2021年09月24日 (313)
2021年09月17日 (191)
2021年09月15日 (369)
2021年09月16日 (411)
2021年09月13日 (439)
2021年09月11日 (398)
2021年09月12日 (393)
2021年09月10日 (160)
2021年09月08日 (222)
最新文章
更多>
2021/09/28 scripts
2022-05-27
vue自定义全局指令v-emoji限制input输入表情和特殊字符
2022-05-27
9.26学习总结
2022-05-27
vim操作
2022-05-27
深入理解计算机基础 第三章
2022-05-27
C++ string 作为形参与引用传递(转)
2022-05-27
python 加解密
2022-05-27
JavaScript-对象数组里根据id获取name,对象可能有children属性
2022-05-27
SQL语句——保持现有内容在后面增加内容
2022-05-27
virsh命令文档
2022-05-27
教程昨日排行
更多>
1.
list.reverse()
2.
Django Admin 管理工具
3.
AppML 案例模型
4.
HTML 标签列表(功能排序)
5.
HTML 颜色名
6.
HTML 语言代码
7.
jQuery 事件
8.
jEasyUI 创建分割按钮
9.
jEasyUI 创建复杂布局
10.
jEasyUI 创建简单窗口
友情链接
汇智网
PHP教程
插件网
关于我们
-
联系我们
-
留言反馈
- 联系我们:wmxa8@hotmail.com
© 2014
bubuko.com
版权所有
打开技术之扣,分享程序人生!