今天首先简单的学习了一下xpath,网上有许多介绍xpath的,我就不细说了,因为xpath又可以引出来诸如节点等一大堆属性,我就用口语描述一下它的用法。它可以通过HTML的标签在HTML中搜索出想要的内容。例子如下,首先看到腾讯新闻的主页,右键检查,出现开发者选项,Ctrl+F调出xpath搜索框
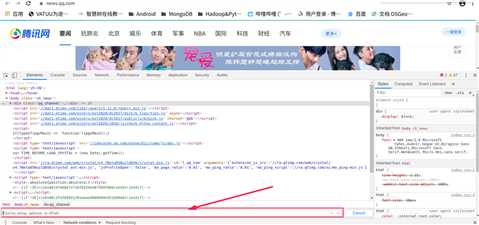
xpath使用方法如下:
/[标签] 表示从根节点(最开始)寻找,在这个例子中,只能找到 /HTML ,其他的都找不到
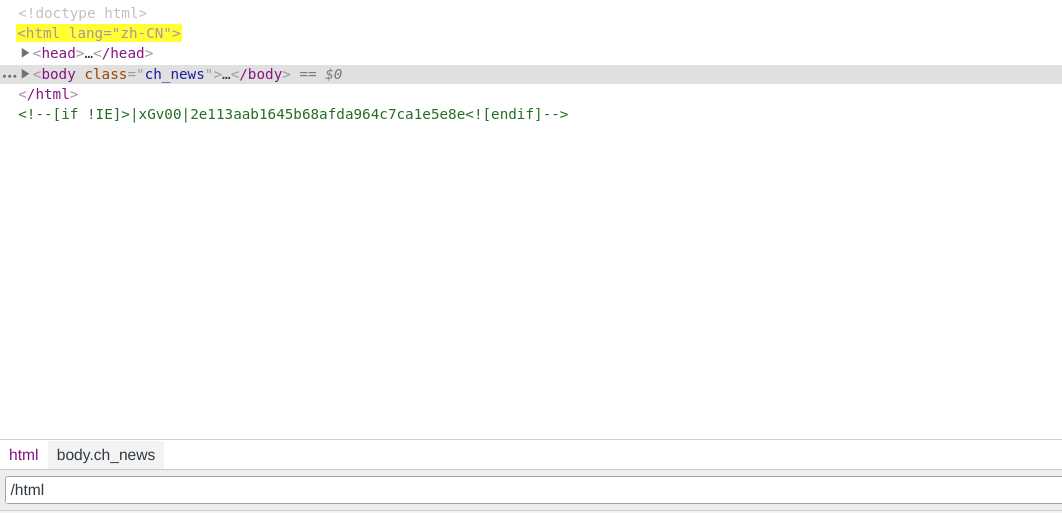

//[标签] 则是从整个文档匹配,这也是最常用到的标签,它会从整个文档找能够匹配的标签

如上图,div一共可以找到129个
[@(class/id/...)=""] 则是根据属性限制寻找的范围,中括号直接写在标签后面
以上就是三条最基本的规则,有了这三条规则,就可以写出绝大部分xpath了。举例,我要得到下面的链接:
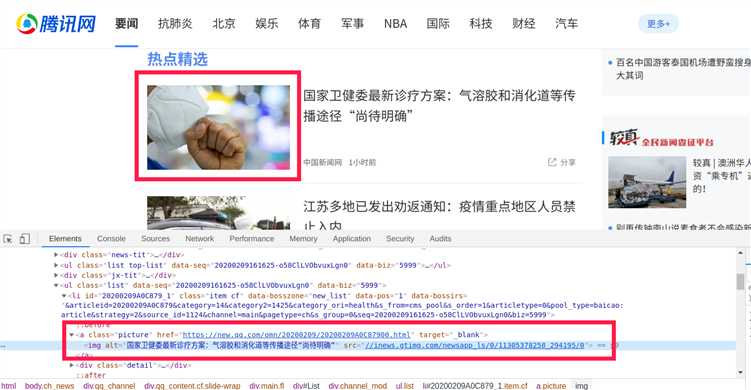
//a[@class="picture"]/@href 就得到相应的链接了,这句话的意思是从非根节点选取class属性为picture的href属性。

至于为什么有3个,那当然是因为不止一个链接有相同的标签属性。
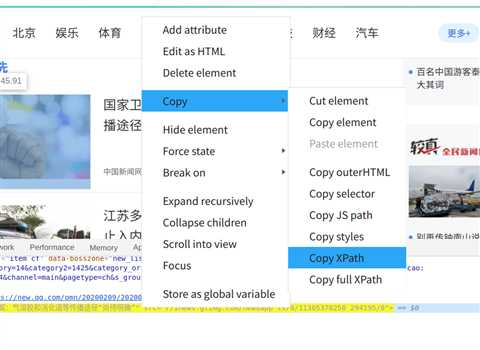
除此之外,如果自己不想写的话,右键浮在想得到xpath的标签上,右击选取copy,选择xpath即可得到xpath,但我认为这样的xpath没有通用性,所以还是自己写比较好。
继续学习scrapy框架,看了几个简单的教程例子后准备动手写一个。我的目标是爬取卫健委的疫情数据。创建项目,设置Setting,爬取源码,然后得到一大堆js……没错,这个网页使用js动态加载的,并非静态网页,而很不巧的是,scrapy没法爬取动态加载网页的网页数据,所以只好找了一个静态网页练习了一下。正在寻找scrapy爬取动态网页的方法。似乎scrapy-splash可以,正在实验中。
原文:https://www.cnblogs.com/YXSZ/p/12287347.html