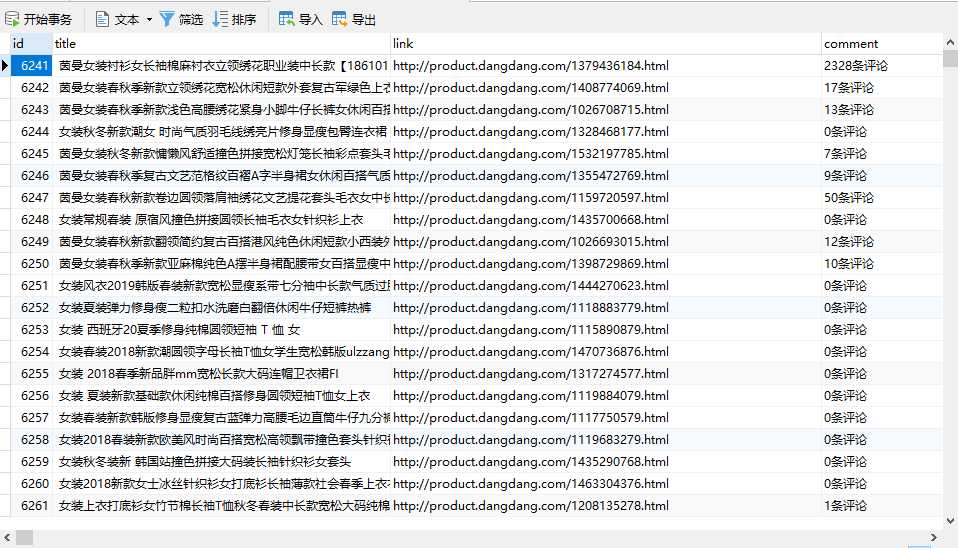
学了使用scarpy框架进行爬虫,爬取了某网站的部分信息。
部分代码:

# -*- coding: utf-8 -*- import scrapy from dangdang01.items import Dangdang01Item from scrapy.http import Request class DdSpider(scrapy.Spider): name = ‘dd‘ allowed_domains = [‘dangdang.com‘] start_urls = [‘http://search.dangdang.com/?key=%C5%AE%D7%B0&act=input&page_index=1‘] def parse(self, response): item = Dangdang01Item() item["title"] = response.xpath("//a[@name=‘itemlist-title‘]/@title").extract() item["link"] = response.xpath("//a[@name=‘itemlist-title‘]/@href").extract() item["comment"] = response.xpath("//a[@name=‘itemlist-review‘]/text()").extract() yield item for i in range(2,81): url = ‘http://search.dangdang.com/?key=%C5%AE%D7%B0&act=input&page_index=‘+str(i) yield Request(url,callback=self.parse)
原文:https://www.cnblogs.com/baimafeima/p/12271212.html
