今天又碰到了难缠的python编码问题,首先主要还是linux操作系统中的编码问题。
vim中的set encoding,set fileencoding, set fileencodings 各种设置了还是无法打出中文,还是出现乱码?
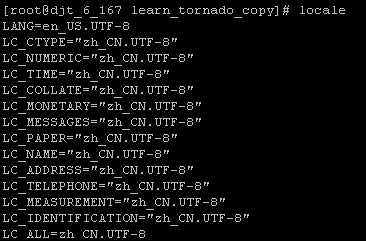
这时就要考虑linux系统编码的问题,利用locale命令查看一下linux系统的编码。LC_ALL的设置会覆盖所偶LC_*的设定,直接忽略LANG。如果未设置LC_ALL,则LC_*按照LANG的值来设定。
注意LC_ALL设置中文编码后linux系统才可能支持中文~,如果这个地方忽略。vim中怎样设置都无效。
enc(encoding):vim的内部编码
fenc(fileencoding):vim解析出来的当前文件编码
fencs(fileencodings):vim解析文件时猜测的编码格式顺序列表
这些其实不需要测试,用于查看编码比较重要。
抓取网页注意编码的检查,百度图片的编码采用utf8,而搜狗图片的编码采用gb2312。其中url参数也有讲究,
百度的url参数中的中文采用utf8编码。搜狗图片的url参数需要转码。这些细节在抓取网页中都需要考虑到。
|
1 |
http://pic.sogou.com/pics?query=%B6%AB%DD%B8%BB%C6%BD%AD%CC%AB%D7%D3%BE%C6%B5%EA%C3%C0%C5%AE |
|
1 |
http://image.baidu.com/i?ie=utf-8&word=东莞黄江太子酒店美女 |
原文:http://www.cnblogs.com/weixliu/p/3552807.html