日期:2020.02.01
博客期:140
星期六
今天问了一下老师,好像是之前数据爬取的内容就不对,不应该爬取标签,我仔细想了一下,也确实不是,所以今天我们来爬取IT新闻里的高频词!
我大致分了下面几个步骤
1、选择想要爬取的网站
之前那个网站有标签,所以我按照那个爬的,实际上没有必要,随便一个IT新闻网站都可以爬的!而且上一次的爬取网站有很大的问题就是它不能加载太多数据,加载个200次,就基本卡死了!所以我们尽量要找到一个有页数下表的列表类型的网页,要不然就是有“下一页”或“下一篇新闻”类似的链接的网页。
下面是提供参考的网站:
(1)、IT之家(大概可以爬到700条数据,数据大致横跨7天,推荐每周爬取一次,并进行汇总查重,其中有非信息类新闻夹杂)
(2)、博客园(推荐,大概可以一次爬3000条数据,数据大致横跨2个月零4天,推荐隔2个月爬一次,其中有少量非信息类新闻夹杂,且单项数据的文字数目较少)
(3)、DoNews(这个是针对互联网的)
(4)、ZOL中关村在线(这个只有一页,数据横跨两周,推荐隔13天爬)
(5)、IT界(可以直接一次爬取14969项新闻,其中有少量非信息类新闻夹杂,仅提供一次性爬取,最早数据日期为2012-04-23)
(6)、51CTO(上次推荐的网站,有标签标记和关键索引)
(7)、走廊网(和上面一样是滚动式网站,一样的弊病,还有这个网站分类有IT类,但是内容不完全是IT相关的)
(8)、说IT资讯网(数据都是老数据了,2011年还行,我们要的是热词,不推荐)
国外IT新闻网站推荐博客地址:https://www.cr173.com/html/5311_1.html
2、开始针对于网站进行爬取(目标:获得文字内容)
让我想想爬哪个网站好... ...
3、利用 Python 的 开源 jieba 组件进行中文词频统计
jieba组件下载地址:https://pypi.org/project/jieba/
我的下载方法:(确保电脑处于联机状态——就是你联网了,你也可以参照上述官网下载地址的下载方法)
(1)打开PyCharm
(2)在非菜单栏、非窗口、非代码演示部分鼠标右击,并选中"Open in Terminal"
(3) 输入命令(因你运行的 Python 环境而异)
easy_install jieba 无限制
pip install jieba Python 2
pip3 install jieba Python 3
(4)等待其下载完成,如图: 
使用方法参照以下博客(本期博客非针对jieba,不再过多赘述):
小注:
其实我们对 jieba 组件的使用还有一些问题的,不过我们只要高频词,使用那三种模式应该无所谓了(还是推荐精准模式)
4、制作词语筛选部分,并进行封装,并将统计结果记录
测试文件

《2019年OPPO开放平台年度总结》正式发布 近日,OPPO开放平台通过官微平台发布了《2019年OPPO开放平台年度总结》。 这份年度总结对OPPO智能服务新生态的用户属性、用户偏好、市场增长,以及OPPO开放平台的技术能力和服务能力进行了详细的介绍,帮助开发者及合作伙伴挖掘数据背后的衍生价值,携手共创更优质的用户体验。 ColorOS全球月活超3.2亿,以优质年轻群体为主 根据《2019年OPPO开放平台年度总结》显示,目前ColorOS全球月活跃用户数已超过3.2亿,覆盖国家和地区超过140个。而在国内用户中,25岁~34岁的优质年轻群体占比更是高达63%,24岁以下用户占比为21%,足见OPPO手机设备深受年轻群体所喜爱。 正因如此,OPPO无论是硬件端的产品创新,还是软件端的“黑科技”研发,也都始终迎合年轻群体偏好。如在2019年10月上市的OPPO Reno Ace,其配置为骁龙855 Plus、65W超级闪充、90Hz电竞屏、最高12GB+256GB存储组合,2999元起的高性价比优势,让其开售5分钟销售额破亿,斩获全平台手机单品销量&销售额双冠军。 此外,该产品搭载OPPO“五大系统能力开放引擎”之一的Hyper Boost,并与游戏厂商深度合作,更充分地发挥了硬件性能。OPPO Reno Ace高性价比的产品配置以及“黑科技”加持,让年轻消费者直呼“这很Ace!”。 OPPO开放平台携手合作伙伴共建智能服务新生态,打造优质用户体验 产品受到用户喜爱,同样也离不开智能服务新生态的建设。OPPO开放平台为了给用户带来更优质的产品体验,将其技术能力深度赋能给合作伙伴,携手合作伙伴合作共赢。 根据《2019年OPPO开放平台年度总结》显示,在OPPO开放平台的应用分发情况分析中,视频播放类、教育学习类、实用工具类APP是最受用户青睐的应用类别。 时代大环境下,OPPO积极建设视频功能迎合用户需求,OPPO短视频业务月活跃用户已突破6000万,每日人均使用时长超过50分钟,为优质的视频内容分发和应用分发,提供了可以结合用户手机操作偏好的又一大渠道。 在短视频类目的软件能力建设方面,OPPO也始终走在创新前沿。当抖音、快手等热门短视频类APP接入“五大系统能力开放引擎”之一的CameraUnit,调用OPPO手机核心功能“超级防抖”,就能够让用户直接拍摄出稳定、清晰的视频。 深度挖掘数据的衍生价值,OPPO早已不再是一家纯粹的手机公司 硬件产品受到年轻用户喜爱,软件能力不断创新,也让OPPO的业务线早已不再局限于手机制造。当前,OPPO已经建设了更为完善的开放生态,除了技术能力加持赋能合作伙伴,依托自身市场优势,也为应用、游戏、快应用、小游戏等产品分发推广和联运提供了更为广阔的发展空间,为各链端合作伙伴提供全方位的服务。 根据《2019年OPPO开放平台年度总结》显示,以OPPO软件商店和游戏中心的全球月活跃用户数已超过3亿,全球日分发次数也超过7.8亿次。同时,OPPO开放平台还在积极扩展自身的业务服务范围,并不断创新服务形式。以应用分发业务为例,通过数据赋能、活动赋能、素材A/B test、活动组建化赋能等形式,帮助开发者实现更加高效的APP运营。 除此之外,OPPO还在科技的各个领域积极探索。例如,在2019年12月19日的2019 OPPO开发者大会上发布IoT“启能行动”,将帮助更多品牌厂商快速实现产品的智能化。 此外,2020年OPPO将继续投入价值10亿资源,为应用、服务、内容、出海领域的优秀合作伙伴,提供开发、流量、营销推广等一系列的资源支持,全方位助力合作伙伴的业务发展;OPPO荣获中文机器阅读理解挑战赛DuReader 2019年度冠军,AI领域再次取得新突破…… 由此可见,通过对多维度技术的持续、广泛的布局,OPPO早已不再是一家纯粹的手机公司。据OPPO创始人陈明永介绍,OPPO未来三年将投入500亿研发预算,持续关注5G、人工智能、AR、大数据等前沿技术,并着力构建底层硬件核心技术以及软件工程和系统能力。 OPPO开放平台作为B端业务的主要窗口,这份《2019年OPPO开放平台年度总结》的公布既能让行业窥见到OPPO综合能力的一方天地,也将吸引更多合作伙伴加入OPPO开放平台,合作共创新未来。 查看完整年度总结,请关注OPPO开放平台官方微信公众号“OPPO开发者”或微博“OPPO开放平台”。
标准规范类
1 # 新闻段落高频词分析器 2 import jieba 3 import jieba.analyse 4 5 6 class ToolToMakeHighWords: 7 test_str = "" 8 9 # 初始化 10 def __init__(self,test_str): 11 self.test_str = str(test_str) 12 pass 13 14 def buildWithFile(self,filePath,type): 15 file = open(filePath, encoding=type) 16 self.test_str = file.read() 17 18 def buildWithStr(self,test_str): 19 self.test_str = test_str 20 pass 21 22 # 统计词 23 def getWords(self,isSimple,isAll): 24 if(isSimple): 25 words = jieba.lcut_for_search(self.test_str) 26 return words 27 else: 28 # True - 全模式 , False - 精准模式 29 words = jieba.cut(self.test_str, cut_all=isAll) 30 return words 31 32 # 统计词频并排序 33 def getHighWords(self,words): 34 data = {} 35 for charas in words: 36 if len(charas) < 2: 37 continue 38 if charas in data: 39 data[charas] += 1 40 else: 41 data[charas] = 1 42 43 data = sorted(data.items(), key=lambda x: x[1], reverse=True) # 排序 44 45 return data 46 47 # 以频率要求数目为依据进行筛选 48 def selectObjGroup(self,num): 49 a = jieba.analyse.extract_tags(self.test_str, topK=num, withWeight=True, allowPOS=()) 50 return a 51 52 def selectWordGroup(self,num): 53 b = jieba.analyse.extract_tags(self.test_str, topK=num, allowPOS=()) 54 return b 55 56 57 def main(): 58 file = open(‘../testFile/rc/ad.txt‘, encoding="utf-8") 59 file_context = file.read() 60 ttmhw = ToolToMakeHighWords(file_context) 61 li = ttmhw.selectWordGroup(2) 62 print(li) 63 64 main()
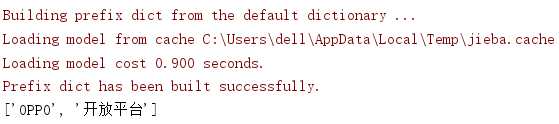
测试截图
原文:https://www.cnblogs.com/onepersonwholive/p/12248077.html
