一、什么是验证码?
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写。 是一种用来区分用户是计算机还是人的公共全自动程序。
二、验证码的作用
验证码是一种人机识别手段,最终目的是区分正常用户和机器的操作。 可以防止:恶意破解密码、注册、刷票、论坛灌水,防止黑客对用户的密码进行暴力破解。 一般是提出一个问题,这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答这个的问题,所以回答出问题的用户就可以被认为是人类。
三、验证码类别
验证码自面世以来就一直在更新,迭代。
图形验证码:这类验证码大多是计算机随机产生一个字符串,在把字符串增加噪点、干扰线、变形、重叠、不同颜色、扭曲组成一张图片来增加识别难度。
滑动验证码:也叫行为验证码,比较流行的一种验证码,通过用户的操作行为来完成验证,其中最出名的就是极验。 滑动验证码的原理就是使用机器学习中的深度学习技术,根据一些特征来区分是否为正常用户。通过记录用户的滑动速度,还有每一小段时间的瞬时速度,用户鼠标点击情况,以及滑动后的匹配程度来识别。而且,不是说滑动到正确位置就是验证通过,而是根据特征识别来区分是否为真用户,滑到正确位置只是一个必要条件。
点触验证码:点击类验证码都是给出一张包含文字的图片,通过文字提醒用户点击图中相同字的位置进行验证。
四、爬虫之对验证码的处理
目前,图形验证码和点触验证码基本可以通过打码平台(超级鹰、打码兔等)进行破解,而滑动验证码相对比较难以一破解,如果缺口图与周围的颜色对比度比较明显,则可以通过灰度化、二值化和简单的算法算出滑动的距离,而如果对比度比较差(爱奇艺滑动验证码),则难度比较大。
对验证码进行灰度化、二值化的处理,一般使用python的pillow库比较好
1、Pillow库
PIL库:PIL (Python Image Library) 已经算是 Python 处理图片的标准库了,兼具强大的功能和简洁的 API. 但是PIL库的更新非常缓慢, 并且它只支持到python2.7,不支持python3
Pillow库:由于PIL库更新太慢了,于是于是一群志愿者在PIL库的基础上创建了一个新的分支版本,命名为Pillow. Pillow目前最新支持到python3.6,它的维护和开发十分活跃,兼容PIL库的绝大多数语法,并且增加了许多新的特性,推荐直接使用Pillow
注意点:Pillow和PIL不能共存在一个环境中,如果你之前安装了PIL的话,需要删除掉才能在安装Pillow 由于是继承自PIL的分支, 所以Pillow库的导入是这样的 Import PIL
2、PIL中所涉及的基本概念:通道(bands)、尺寸(size)、坐标系统(coordinate system)
尺寸:图片尺寸(size)指的是图片的宽度和高度 通过size属性可以获取图片的尺寸,它的返回值是一个元祖,元祖里面有两个值,分别是水平和垂直方向上的像素个数
通道:每张图片都是由一个或者多个数据通道构成,如果这些通道具有相同的维数和深度,PIL允许将这些通道进行叠加 以RGB图像为例,每张图片都是由三个数据通道叠加构成,分别为R 、G 、B。 PNG图像打开为有RGBA四个通道,A代表透明度 对于灰度图像(没有色彩的图片, RGB色彩分量全部相等),只有一个通道。 灰度指的是黑白图像中点的颜色深度,范围一般是0到255, 白色为255,黑色为0
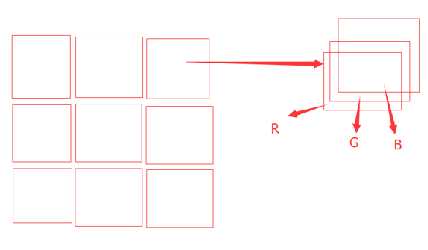
坐标系统(coordinate system):PIL使用笛卡尔像素坐标系统,图像的左上角为左边的原点(0,0),这就意味着,x轴的数值是从左到右增长的,y轴的数值是从上到下增长的。 在我们处理图像的时候,常常需要去表示一个矩形的图像区域。Pillow中很多方法都需要传入一个表示矩形区域的元祖 这个元祖包含四个值,分别表示矩形四条边距离x轴或者y轴的距离。顺序是(左,顶,右,底) 例如,一个800x600的像素图像表示为(0, 0, 800, 600)

3、PIL操作图像
Image是Pillow中最为重要的类,实现了Pillow中大部分的功能,
创建这个类的实例主要有三个方式:
1.从文件中加载图像
2.创建一个新的图像
3.处理其他的图像获得
安装pillow库:pip install pillow -i http://pypi.douban.com/simple
对于一张图片的通道数量和名称,可以通过方法getbands()来获取。方法getbands()是PIL中Image子模块的方法,它会返回一个字符串组成的元祖,元祖中包括了每一个通道的名称。
from PIL import Image
im = Image.open(‘test.jpg’)
print(im.getbands())
输出: (’R’, ‘G’, ‘B’)
4、简单验证码处理
灰度化:
像素点是最小的图片单元,一张图片由很多像素点构成,一个像素点的颜色是由RGB三个值来表现的,所以一个像素点对应三个颜色向量矩阵,我们对图像的处理就是对这个像素点的操作。
图片的灰度化,就是让像素点矩阵中的每一个像素点满足 R=G=B,此时这个值叫做灰度值,白色为0,黑色为255
灰度转化一般公式为: R=G=B = 处理前的 RX0.3 + GX0.59 + B*0.11
from PIL import Image img = Image.open("test.png") img = img.convert("L")
二值化:
图像的二值化,就是将图像的像素点矩阵中的每个像素点的灰度值设置为0(黑色)或255(白色),从而实现二值化,将整个图像呈现出明显的只有黑和白的视觉效果。 二值化原理是利用设定的一个阈值来判断图像像素是0还是255, 一般小于阈值的像素点变为0, 大于的变成255 这个临界灰度值就被称为阈值,阈值的设置很重要,阈值过大或过小都会对图片造成损坏 选择阈值的原则是:既要尽可能保存图片信息,又要尽可能减少背景和噪声的干扰
常用阈值选择的方法是:
灰度平局值法: 取127 (0~255的中数, (0+255)/2 = 127)
from PIL import Image img = Image.open("test.png") img = img.convert("L") w, h = img.size iarray = img.load() average = 127 for i in range(h): for j in range(w): if iarray[j, i] > average: iarray[j, i] = 255 else: iarray[j, i] = 0
平均值法: 计算像素点矩阵中的所有像素点的灰度值的平均值avg
from PIL import Image img = Image.open("test.png") img = img.convert("L") w, h = img.size iarray = img.load() average = 0 s = 0 for i in range(h): for j in range(w): s += iarray[j, i] average = int(s / (w * h)) for i in range(h): for j in range(w): if iarray[j, i] > average: iarray[j, i] = 255 else: iarray[j, i] = 0
迭代法: 选择一个近似阈值作为估计值的初始值,然后进行分割图像,根据产生的子图像的特征来选取新的阈值,在利用新的阈值分割图像,经过多次循环,使得错误分割的图像像素点降到最小。
降噪:经过了二值化处理,整个图片像素就被分为了两个值0和255, 如果一个像素点是图片或者干扰因素的一部分,那么她的灰度值一定是0(黑色),如果一个点是背景,其灰度值应该是255,白色 所以对于孤立的噪点,他的周围应该都是白色,或者大多数点都是白色的,所以在判断的时候条件应该放宽,一个点是黑色并且相邻的点为白色的点的个数大于一个固定的值,那么这个点就是噪点。 我们根据一个点A的RGB值,与周围的8个点的RBG值比较,设定一个值N(0 <N <8),当A的RGB值与周围8个点的RGB相等或者小于N时,此点为噪点
from PIL import Image import pytesseract import tesserocr def gray(image): new_image = Image.new("RGB", image.size, "red") narray = new_image.load() iarray = image.load() w, h = new_image.size for i in range(h): for j in range(w): v = int(0.3*iarray[j, i][0] + 0.59*iarray[j, i][1] + 0.11*iarray[j, i][2]) narray[j, i] = (v, v, v) return new_image pytesseract.pytesseract.tesseract_cmd = "D:\\Tesseract-OCR\\tesseract.exe" image = Image.open(r"E:\vscode\Python\homework.png") # 灰度化 image = image.convert("L") # image = gray(image) # 二值化 w, h = image.size iarray = image.load() # 域值 avg = 127 s = 0 for i in range(h): for j in range(w): s += iarray[j ,i] avg = s / (w * h) print(avg) avg = 137 for i in range(h): for j in range(w): if iarray[j, i] > avg: iarray[j, i] = 255 else: iarray[j, i] = 0 for i in range(4): # 降噪率 # 降噪 for i in range(h): for j in range(w): count = 0 # 图片边缘处理 if i == 0 or i == (h - 1) or j == 0 or j == (w - 1): iarray[j, i] == 255 continue # 仅处理黑点 if iarray[j, i] > 200: continue if iarray[j-1, i-1] > 200: count += 1 if iarray[j-1, i] > 200: count += 1 if iarray[j-1, i+1] > 200: count += 1 if iarray[j, i-1] > 200: count += 1 if iarray[j, i+1] > 200: count += 1 if iarray[j+1, i-1] > 200: count += 1 if iarray[j+1, i] > 200: count += 1 if iarray[j+1, i+1] > 200: count += 1 if count > 4: iarray[j ,i] = 255 res = pytesseract.image_to_string(image) print(res) image.show()
5、识别
OCR (Optical Character Recognition)光学字符识别, 指的是对文本资料的图像文件进行分析识别处理,获取文集及版面信息的过程 Tesseract-OCR是一个开源的字符识别引擎,我们可以用他来识别一些简单的验证码。 Windows安装: 安装文件在 Linux安装: sudo apt-get install tesseract-ocr sudo apt-get install libtesseract-dev Mac安装: brew install tesseract Pytesser3是一个在Python内使用Tesseract-Ocr的库,安装非常简单: pip install Pytesseract 然后需要进行配置, 将pytesseract包下面__init__文件内tesseract_exe_name的值设置为为你的tesseract.exe的路径,或者在代码中指定
代码同上,但由于识别度不高,使用打码平台更可靠一些。
原文:https://www.cnblogs.com/loveprogramme/p/12209277.html