版权声明:本文为CSDN博主「很吵请安青争」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/dpengwang/article/details/79060052
——————————————————————————
Namenode 管理着文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata),比如命名空间信息,块信息等。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
Namenode结构图抽象图如下:
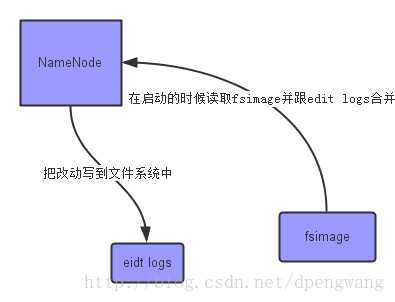
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
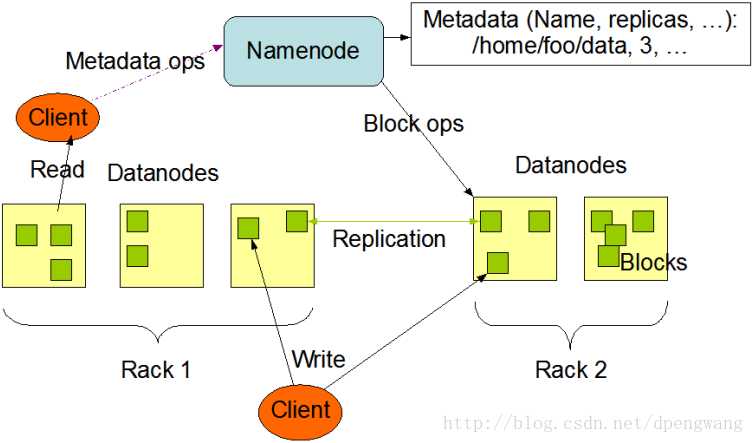
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
文件写入:
1) Client向NameNode发起文件写入的请求。
2) NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode的信息。
3) Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。
文件读取:
1) Client向NameNode发起读取文件的请求。
2) NameNode返回文件存储的DataNode信息。
3) Client读取文件信息。
HDFS作为分布式文件系统在数据管理方面可借鉴点:
文件块的放置:一个Block会有三份备份,一份在NameNode指定的DateNode上,一份放在与指定的DataNode不在同一台机器的DataNode上,一根在于指定的DataNode在同一Rack上的DataNode上。备份的目的是为了数据安全,采用这种方式是为了考虑到同一Rack失败的情况,以及不同数据拷贝带来的性能的问题。
————————————————
版权声明:本文为CSDN博主「很吵请安青争」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/dpengwang/article/details/79060052
原文:https://www.cnblogs.com/wenter2016/p/12132698.html