XPath介绍
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。 --------------------W3School
1. XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
2. XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值。
3. XPath 于 1999 年 11 月 16 日 成为 W3C 标准。XPath 被设计为供 XSLT、XPointer 以及其他 XML 解析软件使用。
XPath 术语
1. 在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
2. 基本值(或称原子值,Atomic value)是无父或无子的节点。
3. 项目(Item)是基本值或者节点。
XPath 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。


谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。


XPath
XPath 是一门在 XML 文档中查找信息的语言。XPath 用来在 XML 文档中对元素和属性进行遍历。
优点:
1) 可在XML中查找信息
2) 支持HTML的查找
3) 通过元素和属性进行导航
由于XPath属于lxml库模块,所以首先要安装库lxml
基础语法
选取节点
常用的表达式

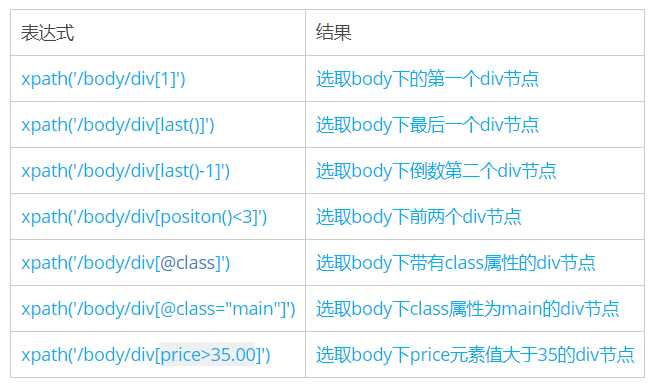
二、谓语
谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点
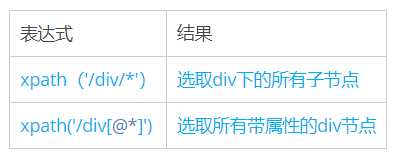
三、通配符
Xpath通过通配符来选取未知的XML元素
四、取多个路径
使用“|”运算符可以选取多个路径

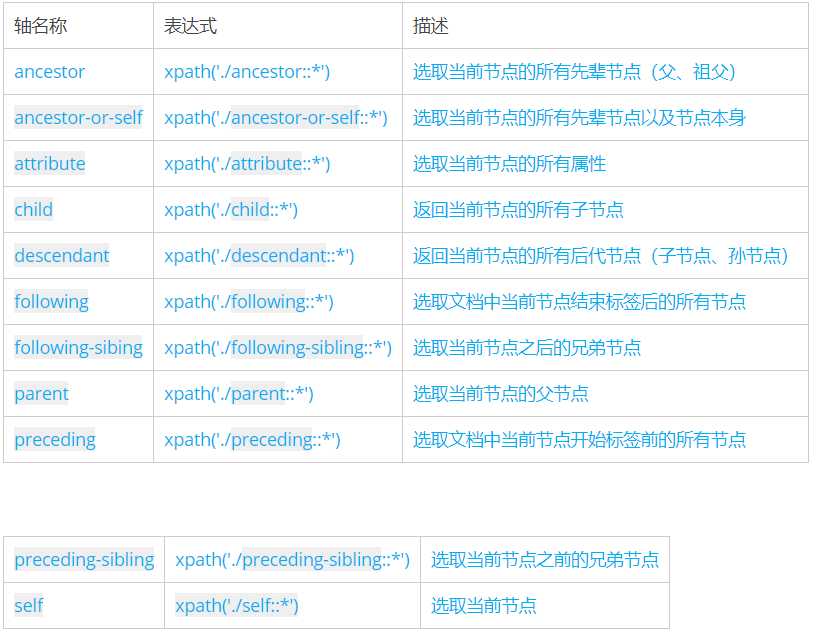
五、Xpath轴
轴可以定义相对于当前节点的节点集
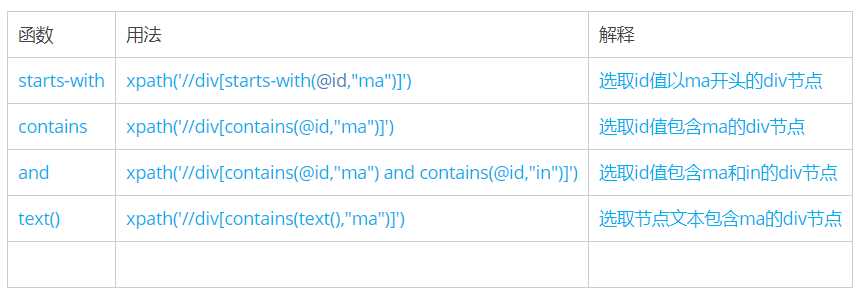
六、功能函数
使用功能函数能够更好的进行模糊搜索
代码实例
import requests
from lxml import etree
baidu=requests.get(‘http://www.baidu.com‘) #请求百度页面
baidu.encoding=baidu.apparent_encoding #页面编码
tree=etree.HTML(baidu.text) #参数只能是str格式的
a_list=tree.xpath(‘//*[@id="u1"]/a‘) #获取的结果为列表形式,故需取其中一个
for a in a_list:
print(a.text,a.xpath(‘./@href‘)[0]) #遍历获取每个a标签的文本及超链接地址
一、简介
Xpath是一门在XML文档中查找信息的语言。Xpath可用来在XML文档中对元素和属性进行遍历。Xpath是W3C XSLT标准的主要元素,并且XQuery和XPointer都构建于XPath表达之上。
二、安装
三、XPath语法
节点关系
(1)父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
(2)子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
(3)同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
(4)先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
(5)后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|
| nodename |
选取此节点的所有子节点。 |
| / |
从根节点选取。 |
| // |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . |
选取当前节点。 |
| .. |
选取当前节点的父节点。 |
| @ |
选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|
| bookstore |
选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book |
选取属于 bookstore 的子元素的所有 book 元素。 |
| //book |
选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book |
选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang |
选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| /bookstore/book[1] |
选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] |
选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] |
选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] |
选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] |
选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] |
选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title |
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|
| * |
匹配任何元素节点。 |
| @* |
匹配任何属性节点。 |
| node() |
匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|
| /bookstore/* |
选取 bookstore 元素的所有子元素。 |
| //* |
选取文档中的所有元素。 |
| //title[@*] |
选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|
| //book/title | //book/price |
选取 book 元素的所有 title 和 price 元素。 |
| //title | //price |
选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price |
选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|
| | |
计算两个节点集 |
//book | //cd |
返回所有拥有 book 和 cd 元素的节点集 |
| + |
加法 |
6 + 4 |
10 |
| – |
减法 |
6 – 4 |
2 |
| * |
乘法 |
6 * 4 |
24 |
| div |
除法 |
8 div 4 |
2 |
| = |
等于 |
price=9.80 |
如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != |
不等于 |
price!=9.80 |
如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < |
小于 |
price<9.80 |
如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= |
小于或等于 |
price<=9.80 |
如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > |
大于 |
price>9.80 |
如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= |
大于或等于 |
price>=9.80 |
如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or |
或 |
price=9.80 or price=9.70 |
如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and |
与 |
price>9.00 and price<9.90 |
如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod |
计算除法的余数 |
5 mod 2 |
1 |
四、lxml用法
from lxml import etree
text = ‘‘‘
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
‘‘‘
html = etree.HTML(text)
result = etree.tostring(html)
print(result)
首先我们使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
其中,这里体现了 lxml 的一个非常实用的功能就是自动修正 html 代码,大家应该注意到了,最后一个 li 标签,其实我把尾标签删掉了,是不闭合的。不过,lxml 因为继承了 libxml2 的特性,具有自动修正 HTML 代码的功能。
所以输出结果是这样的
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
不仅补全了 li 标签,还添加了 body,html 标签。
文件读取
除了直接读取字符串,还支持从文件读取内容。比如我们新建一个文件叫做 hello.html,内容为
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
利用 parse 方法来读取文件。
from lxml import etree
html = etree.parse(‘hello.html‘)
result = etree.tostring(html, pretty_print=True)
print(result)
同样可以得到相同的结果。
XPath实例测试
依然以上一段程序为例
(1)获取所有的 <li> 标签
from lxml import etree
html = etree.parse(‘hello.html‘)
print type(html)
result = html.xpath(‘//li‘)
print result
print len(result)
print type(result)
print type(result[0])
运行结果
<type ‘lxml.etree._ElementTree‘>
[<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>]
5
<type ‘list‘>
<type ‘lxml.etree._Element‘>
可见,etree.parse 的类型是 ElementTree,通过调用 xpath 以后,得到了一个列表,包含了 5 个 <li> 元素,每个元素都是 Element 类型
(2)获取 <li> 标签的所有 class
result = html.xpath(‘//li/@class‘)
print result
运行结果
[‘item-0‘, ‘item-1‘, ‘item-inactive‘, ‘item-1‘, ‘item-0‘]
(3)获取 <li> 标签下 href 为 link1.html 的 <a> 标签
result = html.xpath(‘//li/a[@href="link1.html"]‘)
print result
运行结果
[<Element a at 0x10ffaae18>]
(4)获取 <li> 标签下的所有 <span> 标签
注意这么写是不对的
result = html.xpath(‘//li/span‘)
因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath(‘//li//span‘)
print result
运行结果
[<Element span at 0x10d698e18>]
(5)获取 <li> 标签下的所有 class,不包括 <li>
result = html.xpath(‘//li/a//@class‘)
print result
运行结果
(6)获取最后一个 <li> 的 <a> 的 href
result = html.xpath(‘//li[last()]/a/@href‘)
print result
运行结果
(7)获取倒数第二个元素的内容
result = html.xpath(‘//li[last()-1]/a‘)
print result[0].text
运行结果
(8)获取 class 为 bold 的标签名
result = html.xpath(‘//*[@class="bold"]‘)
print result[0].tag
运行结果
也可以利用 text 方法来获取元素的内容。
转载自:https://cuiqingcai.com/2621.html
知识储备:
/ 直系标签
// 后代标签
extract()
extract_first()
一、简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
参照
二、安装
三、使用
1、导入
2、基本使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from lxml import etree
wb_data =
html = etree.HTML(wb_data)
print(html)
result = etree.tostring(html)
print(result.decode("utf-8"))
|
从下面的结果来看,我们打印机html其实就是一个python对象,etree.tostring(html)则是不全里html的基本写法,补全了缺胳膊少腿的标签。
1 2 3 4 5 6 7 8 9 10 11 | <Element html at 0x39e58f0>
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
|
3、获取某个标签的内容(基本使用),注意,获取a标签的所有内容,a后面就不用再加正斜杠,否则报错。
写法一
1 2 3 4 5 6 7 8 9 10 11 12 13 | html = etree.HTML(wb_data)
html_data = html.xpath(‘/html/body/div/ul/li/a‘)
print(html)
for i in html_data:
print(i.text)
<Element html at 0x12fe4b8>
first item
second item
third item
fourth item
fifth item
|
写法二(直接在需要查找内容的标签后面加一个/text()就行)
1 2 3 4 5 6 7 8 9 10 11 12 | html = etree.HTML(wb_data)
html_data = html.xpath(‘/html/body/div/ul/li/a/text()‘)
print(html)
for i in html_data:
print(i)
<Element html at 0x138e4b8>
first item
second item
third item
fourth item
fifth item
|
4、打开读取html文件
1 2 3 4 5 6 | html = etree.parse(‘test.html‘)
html_data = html.xpath(‘//*‘)<br>
print(html_data)
for i in html_data:
print(i.text)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | html = etree.parse(‘test.html‘)
html_data = etree.tostring(html,pretty_print=True)
res = html_data.decode(‘utf-8‘)
print(res)
打印:
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
|
5、打印指定路径下a标签的属性(可以通过遍历拿到某个属性的值,查找标签的内容)
1 2 3 4 5 6 7 8 9 10 11 | html = etree.HTML(wb_data)
html_data = html.xpath(‘/html/body/div/ul/li/a/@href‘)
for i in html_data:
print(i)
打印:
link1.html
link2.html
link3.html
link4.html
link5.html
|
6、我们知道我们使用xpath拿到得都是一个个的ElementTree对象,所以如果需要查找内容的话,还需要遍历拿到数据的列表。
查到绝对路径下a标签属性等于link2.html的内容。
1 2 3 4 5 6 7 8 9 | html = etree.HTML(wb_data)
html_data = html.xpath(‘/html/body/div/ul/li/a[@href="link2.html"]/text()‘)
print(html_data)
for i in html_data:
print(i)
打印:
[‘second item‘]
second item
|
7、上面我们找到全部都是绝对路径(每一个都是从根开始查找),下面我们查找相对路径,例如,查找所有li标签下的a标签内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 | html = etree.HTML(wb_data)
html_data = html.xpath(‘//li/a/text()‘)
print(html_data)
for i in html_data:
print(i)
打印:
[‘first item‘, ‘second item‘, ‘third item‘, ‘fourth item‘, ‘fifth item‘]
first item
second item
third item
fourth item
fifth item
|
8、上面我们使用绝对路径,查找了所有a标签的属性等于href属性值,利用的是/---绝对路径,下面我们使用相对路径,查找一下l相对路径下li标签下的a标签下的href属性的值,注意,a标签后面需要双//。
1 2 3 4 5 6 7 8 9 10 11 12 13 | html = etree.HTML(wb_data)
html_data = html.xpath(‘//li/a//@href‘)
print(html_data)
for i in html_data:
print(i)
打印:
[‘link1.html‘, ‘link2.html‘, ‘link3.html‘, ‘link4.html‘, ‘link5.html‘]
link1.html
link2.html
link3.html
link4.html
link5.html
|
9、相对路径下跟绝对路径下查特定属性的方法类似,也可以说相同。
1 2 3 4 5 6 7 8 9 | html = etree.HTML(wb_data)
html_data = html.xpath(‘//li/a[@href="link2.html"]‘)
print(html_data)
for i in html_data:
print(i.text)
打印:
[<Element a at 0x216e468>]
second item
|
10、查找最后一个li标签里的a标签的href属性
1 2 3 4 5 6 7 8 9 | html = etree.HTML(wb_data)
html_data = html.xpath(‘//li[last()]/a/text()‘)
print(html_data)
for i in html_data:
print(i)
打印:
[‘fifth item‘]
fifth item
|
11、查找倒数第二个li标签里的a标签的href属性
1 2 3 4 5 6 7 8 9 | html = etree.HTML(wb_data)
html_data = html.xpath(‘//li[last()-1]/a/text()‘)
print(html_data)
for i in html_data:
print(i)
打印:
[‘fourth item‘]
fourth item
|
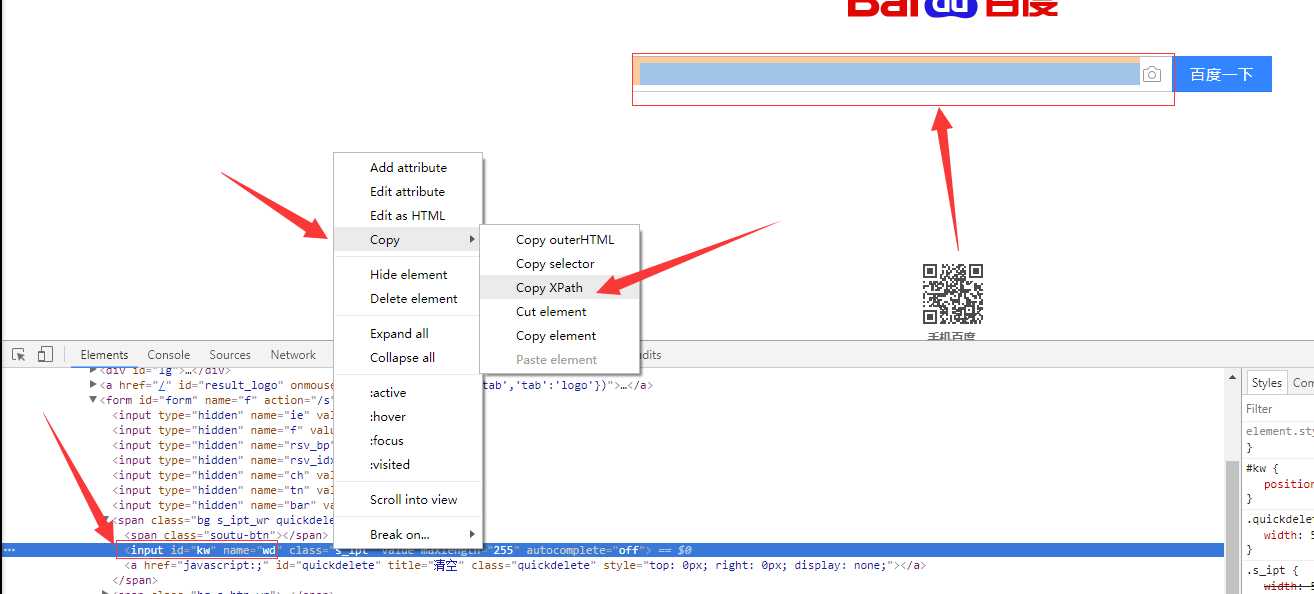
12、如果在提取某个页面的某个标签的xpath路径的话,可以如下图:
//*[@id="kw"]
解释:使用相对路径查找所有的标签,属性id等于kw的标签。


#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.selector import Selector, HtmlXPathSelector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
<li class="item-"><a id=‘i1‘ href="link.html">first item</a></li>
<li class="item-0"><a id=‘i2‘ href="llink.html">first item</a></li>
<li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li>
</ul>
<div><a href="llink2.html">second item</a></div>
</body>
</html>
"""
response = HtmlResponse(url=‘http://example.com‘, body=html,encoding=‘utf-8‘)
# hxs = HtmlXPathSelector(response)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[2]‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[@id]‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[@id="i1"]‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[@href="link.html"][@id="i1"]‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[contains(@href, "link")]‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[starts-with(@href, "link")]‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[re:test(@id, "i\d+")]‘)
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[re:test(@id, "i\d+")]/text()‘).extract()
# print(hxs)
# hxs = Selector(response=response).xpath(‘//a[re:test(@id, "i\d+")]/@href‘).extract()
# print(hxs)
# hxs = Selector(response=response).xpath(‘/html/body/ul/li/a/@href‘).extract()
# print(hxs)
# hxs = Selector(response=response).xpath(‘//body/ul/li/a/@href‘).extract_first()
# print(hxs)
# ul_list = Selector(response=response).xpath(‘//body/ul/li‘)
# for item in ul_list:
# v = item.xpath(‘./a/span‘)
# # 或
# # v = item.xpath(‘a/span‘)
# # 或
# # v = item.xpath(‘*/a/span‘)
# print(v)
常用
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。
XPath 是 W3C 标准,XPath 于 1999 年 11 月 16 日 成为 W3C 标准。XPath 被设计为供 XSLT、XPointer 以及其他 XML 解析软件使用。
在XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。
XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
一、选取节点
常用的路径表达式:
|
表达式
|
描述
|
实例
|
|
|
nodename
|
选取nodename节点的所有子节点
|
xpath(‘//div’)
|
选取了div节点的所有子节点
|
|
/
|
从根节点选取
|
xpath(‘/div’)
|
从根节点上选取div节点
|
|
//
|
选取所有的当前节点,不考虑他们的位置
|
xpath(‘//div’)
|
选取所有的div节点
|
|
.
|
选取当前节点
|
xpath(‘./div’)
|
选取当前节点下的div节点
|
|
..
|
选取当前节点的父节点
|
xpath(‘..’)
|
回到上一个节点
|
|
@
|
选取属性
|
xpath(’//@calss’)
|
选取所有的class属性
|
二、谓词:被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点
|
表达式
|
结果
|
|
xpath(‘/body/div[1]’)
|
选取body下的第一个div节点
|
|
xpath(‘/body/div[last()]’)
|
选取body下最后一个div节点
|
|
xpath(‘/body/div[last()-1]’)
|
选取body下倒数第二个div节点
|
|
xpath(‘/body/div[positon()<3]’)
|
选取body下前两个div节点
|
|
xpath(‘/body/div[@class]’)
|
选取body下带有class属性的div节点
|
|
xpath(‘/body/div[@class=”main”]’)
|
选取body下class属性为main的div节点
|
|
xpath(‘/body/div[price>35.00]’)
|
选取body下price元素值大于35的div节点
|
三、通配符:Xpath通过通配符来选取未知的XML元素
|
表达式
|
结果
|
|
xpath(’/div/*’)
|
选取div下的所有子节点
|
|
xpath(‘/div[@*]’)
|
选取所有带属性的div节点
|
四、取多个路径:使用“ | 运算符可以选取多个路径
|
表达式
|
结果
|
|
xpath(‘//div|//table’)
|
选取所有的div和table节点
|
五、Xpath轴:轴可以定义相对于当前节点的节点集
|
轴名称
|
表达式
|
描述
|
|
ancestor
|
xpath(‘./ancestor::*’)
|
选取当前节点的所有先辈节点(父、祖父)
|
|
ancestor-or-self
|
xpath(‘./ancestor-or-self::*’)
|
选取当前节点的所有先辈节点以及节点本身
|
|
attribute
|
xpath(‘./attribute::*’)
|
选取当前节点的所有属性
|
|
child
|
xpath(‘./child::*’)
|
返回当前节点的所有子节点
|
|
descendant
|
xpath(‘./descendant::*’)
|
返回当前节点的所有后代节点(子节点、孙节点)
|
|
following
|
xpath(‘./following::*’)
|
选取文档中当前节点结束标签后的所有节点
|
|
following-sibing
|
xpath(‘./following-sibing::*’)
|
选取当前节点之后的兄弟节点
|
|
parent
|
xpath(‘./parent::*’)
|
选取当前节点的父节点
|
|
preceding
|
xpath(‘./preceding::*’)
|
选取文档中当前节点开始标签前的所有节点
|
|
preceding-sibling
|
xpath(‘./preceding-sibling::*’)
|
选取当前节点之前的兄弟节点
|
|
self
|
xpath(‘./self::*’)
|
选取当前节点
|
六、功能函数:使用功能函数能够更好的进行模糊搜索
|
函数
|
用法
|
解释
|
|
starts-with
|
xpath(‘//div[starts-with(@id,”ma”)]‘)
|
选取id值以ma开头的div节点
|
|
contains
|
xpath(‘//div[contains(@id,”ma”)]‘)
|
选取id值包含ma的div节点
|
|
and
|
xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘)
|
选取id值包含ma和in的div节点
|
|
text()
|
xpath(‘//div[contains(text(),”ma”)]‘)
|
选取节点文本包含ma的div节点
|
七、常用函数:
1、精确定位
(1)contains(str1,str2)用来判断str1是否包含str2
例1://*[contains(@class,‘c-summaryc-row ‘)]选择@class值中包含c-summary c-row的节点
例2://div[contains(.//text(),‘价格‘)]选择text()中包含价格的div节点
(2)position()选择当前的第几个节点
例1://*[@class=‘result‘][position()=1]选择@class=‘result‘的第一个节点
例2://*[@class=‘result‘][position()<=2]选择@class=‘result‘的前两个节点
(3)last()选择当前的倒数第几个节点
例1://*[@class=‘result‘][last()]选择@class=‘result‘的最后一个节点
例2://*[@class=‘result‘][last()-1]选择@class=‘result‘的倒数第二个节点
(4)following-sibling 选取当前节点之后的所有同级节点
例1://div[@class=‘result‘]/following-sibling::div选择@class=‘result‘的div节点后所有同级div节点找到多个节点时可通过position确定第几个如://div[@class=‘result‘]/following-sibling::div[position()=1]
(5)preceding-sibling 选取当前节点之前的所有同级节点
使用方法同following-sibling
2、过滤信息
(1)substring-before(str1,str2)用于返回字符串str1中位于第一个str2之前的部分
例子:substring-before(.//*[@class=‘c-more_link‘]/text(),‘条‘)
返回.//*[@class=‘c-more_link‘]/text()中第一个‘条‘前面的部分,如果不存在‘条‘,则返回空值
(2)substring-after(str1,str2)跟substring-before类似,返回字符串str1中位于第一个str2之后的部分
例1:substring-after(.//*[@class=‘c-more_link‘]/text(),‘条‘)
返回.//*[@class=‘c-more_link‘]/text()中第一个’条’后面的部分,如果不存在‘条‘,则返回空值
例2:substring-after(substring-before(.//*[@class=‘c-more_link‘]/text(),‘新闻‘),‘条‘)
返回.//*[@class=‘c-more_link‘]/text()中第一个‘新闻‘前面与第一个‘条‘后面之间的部分
(3)normalize-space()
用来将一个字符串的头部和尾部的空白字符删除,如果字符串中间含有多个连续的空白字符,将用一个空格来代替
例子:normalize-space(.//*[contains(@class,‘c-summaryc-row ‘)])
(4)translate(string,str1,str2)
假如string中的字符在str1中有出现,那么替换为str1对应str2的同一位置的字符,假如str2这个位置取不到字符则删除string的该字符
例子:translate(‘12:30‘,‘03‘,‘54‘)结果:‘12:45‘
3、拼接信息
(1)concat()函数用于串连多个字符串
例子:concat(‘http://baidu.com‘,.//*[@class=‘c-more_link‘]/@href)
Python爬虫-xpath
说明
关于Python爬虫请求数据方面的知识点基本讲完,但请求到数据之后呢?
当然是提取数据,抓出对我们有价值的内容是整个爬虫流程的关键步骤之一。现下流行方法有:xapth,BeautifulSoup,正则,PyQuery。如无意外,我会一一笔记下来。今天说说我的最爱吧。
——xpath
再说明
一般情况下,我们爬到的是整个静态网页页面,得到的是html源码,包含各种标签。但那些标签并非我们想要,如:
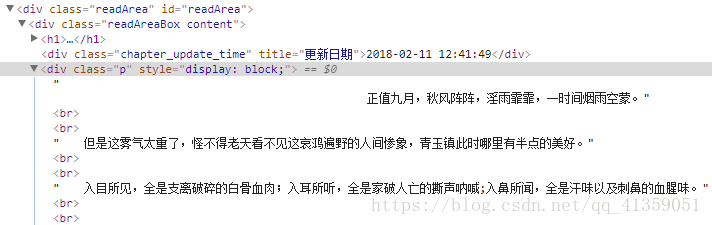
我们只需要里边的文字,这种时候就可以xpath了。如上所说,类似的解决方法包括正则以及BeautifulSoup,前者难度较大,后者广受追捧。从解析速度上说,正则最快,xpath次之,BeautifulSoup再次之;从上手难度来说,BeautifulSoup最易,xpath次之,正则再次之。综合考虑,我偏爱xpath。也有人推崇PyQurey,认为比起繁琐的“美丽汤”语法,它短小精悍,而且如果使用者是前端工程师,掌握起来不需要耗费任何学习成本。这大概因为PyQurey的语法源于JQurey吧。
插件推荐
基于chrome浏览器的插件,它可以让我们提前看到提取效果,使用快捷键ctrl+shift+x

语法讲述
只说常用的:
1. /从根节点开始
2. //从任意位置开始
可以这样理解两个的区别,前者从顶端开始,且前者的左右必须是紧邻的标签;后者任意位置开始,且左右间的标签允许存在间隔
3. div/p div标签下的p标签
4. 提取标签中某个属性的值 div/img/@某个属性
5. 确定带有a属性且值为b的div标签//div[@a="b"]
6. 如果需要取出标签中的文字//span/text()
7. 模糊查询 //div/a[contains(@某属性, "对应属性的部分值")]
8. 多个相同标签用索引方式定位,表示div下div下的第3个a标签 ://div/div/a[3]
举栗子
- 以腾讯社招为例
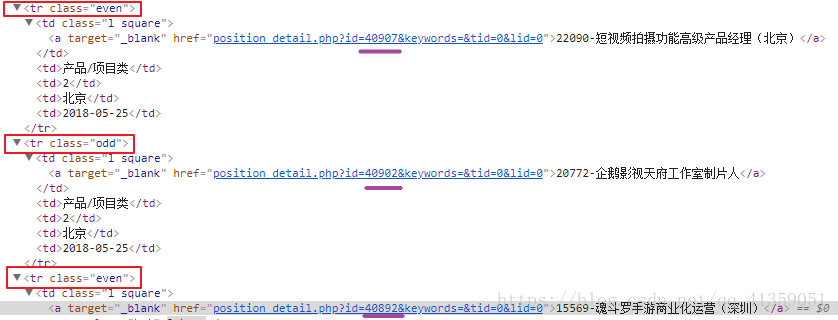
可以发现tr的class值不同,而属性href只有数字部分不同,此时想要获取a标签中的字符串两种方法
a) 模糊查询
//tbody/tr/td/a[contains(@href, "position")]

b) “|”或
//tbody/tr[@class="even"]//a | //tbody/tr[@class="odd"]//a

代码里使用
from lxml import etree
selector = etree.HTML(response.text)
result = selector.xpath("规则")
说明:返回的result是列表类型,如果没有提取到符合规则的信息会返回空列表
实战句子迷
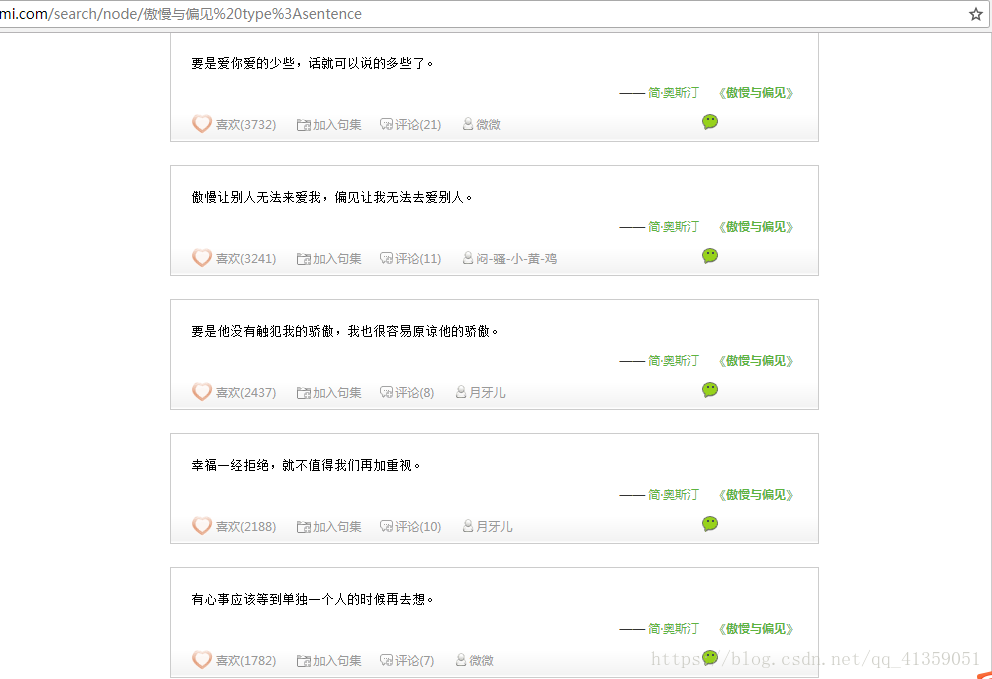
页面呈现如下,要求:获取每个句子,以及“喜欢”量,以及“评论”数
import requests
from lxml import etree
import json
url = "http://www.juzimi.com/search/node/%E5%82%B2%E6%85%A2%E4%B8%8E%E5%81%8F%E8%A7%81%20type%3Asentence"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Referer": "http://www.juzimi.com/search/node/%E5%82%B2%E6%85%A2%E4%B8%8E%E5%81%8F%E8%A7%81%20type%3Asentence",
}
def get_html(params):
"""
获取html页面
"""
try:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status()
print(response.url)
print(response.status_code)
except :
print("connection error")
return None
response.encoding = response.apparent_encoding
return response.text
def parse_html(html):
"""
处理html页面,提取需要数据
"""
data = {}
selector = etree.HTML(html)
ruler = ‘//div[@class="view-content"]/div[contains(@class, "views-row")]‘
roots = selector.xpath(ruler)
with open("sentence.txt", "a", encoding="utf-8") as ob:
for root in roots:
try:
data["sentence"] = root.xpath(‘./div/div[1]/a/text()‘)[0]
data["loved"] = root.xpath(‘./div/div[3]/a/text()‘)[0]
data["comment"] = root.xpath(‘./div/div[5]/a/text()‘)[0]
except IndexError:
continue
ob.write(json.dumps(data, ensure_ascii=False))
ob.write("\n")
def main():
for i in range(4):
if i:
params = {"page":i}
else:
params ={}
html = get_html(params)
if html:
parse_html(html)
print("结束")
if __name__ == "__main__":
main()
结果:
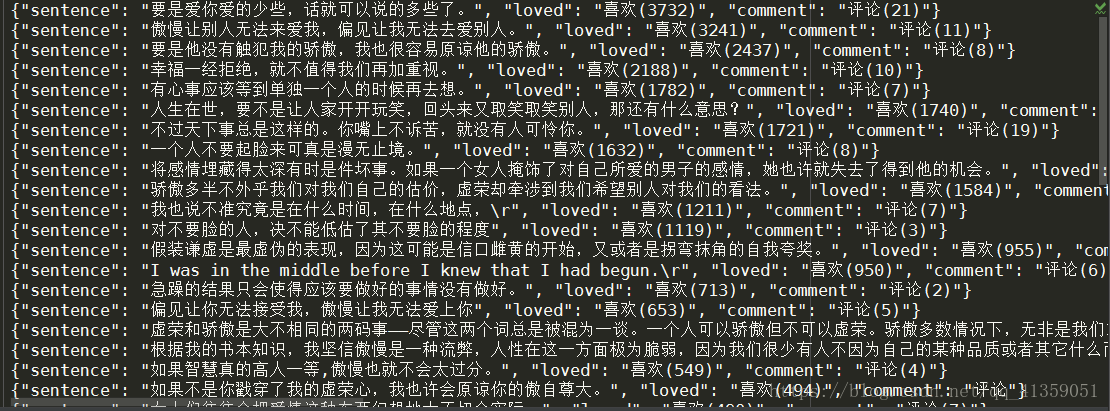
需要的总结:
原本没打算总结的。原本只是做一次用xpath提取数据的示范。以为像句子迷这样的小网站爬起来会很容易,确实是,却也不是。
网页静态呈现,需要的数据都可以通过xpath直接拿到。主要遇到的问题是该网站设置了重定向,就是说直接访问我设置的url地址时,会被重定向到另一个地址去。根据xpath没拿到返回值这一现象,我打印了实际请求地址,结果显示的确被重定向了。我当然第一反应关闭了 get请求中的重定向开关。这之后拿不到数据,状态码返回302。特地百度一下,302是暂时性重定向的意思,它的危害性比较大,主要是可能被黑客利用进行url劫持,也可能恶意刷网站排名,被建议尽量不用或少用。
正确处理方式:请求报文头中一定要加Referer值。老实说,之前也爬过一些大型网站,Referer值从来不带的,这次是长知识了。
