一、selenium简介
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
二、环境安装
- 下载安装selenium:pip install selenium
- 下载浏览器驱动程序:
- http://chromedriver.storage.googleapis.com/index.html
- 查看驱动和浏览器版本的映射关系:
- http://blog.csdn.net/huilan_same/article/details/51896672
三、简单使用/selenium测试
from selenium import webdriver
from time import sleep
# 后面是你的浏览器驱动位置,记得前面加r‘‘,‘r‘是防止字符转义的
driver = webdriver.Chrome(r‘驱动程序路径‘)
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text(‘设置‘)[0].click()
sleep(2)
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text(‘搜索设置‘)[0].click()
sleep(2)
# 选中每页显示50条
m = driver.find_element_by_id(‘nr‘)
sleep(2)
m.find_element_by_xpath(‘//*[@id="nr"]/option[3]‘).click()
m.find_element_by_xpath(‘.//option[3]‘).click()
sleep(2)
# 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2)
# 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to_alert().accept()
sleep(2)
# 找到百度的输入框,并输入 美女
driver.find_element_by_id(‘kw‘).send_keys(‘美女‘)
sleep(2)
# 点击搜索按钮
driver.find_element_by_id(‘su‘).click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text(‘美女_百度图片‘)[0].click()
sleep(3)
# 关闭浏览器
driver.quit()
四、创建浏览器对象(句柄)
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
from selenium import webdriver
browser = webdriver.Chrome() # 谷歌浏览器
browser = webdriver.Firefox() # 火狐浏览器
browser = webdriver.Edge() #IE 浏览器
browser = webdriver.PhantomJS() # 无可视化界面的浏览器(无头浏览器)
browser = webdriver.Safari() # 苹果macOS中浏览器
五、元素定位
webdriver 提供了一系列的元素定位方法,常用的有以下几种:
find_element_by_id() # 通过元素ID定位
find_element_by_name() # 通过元素Name定位
find_element_by_class_name() # 通过类名定位
find_element_by_tag_name() # 通过元素TagName定位
find_element_by_link_text() # 通过文本内容定位
find_element_by_partial_link_text()
find_element_by_xpath() # 通过Xpath语法定位
find_element_by_css_selector() # 通过选择器定位
注意
1、find_element_by_xxx找的是第一个符合条件的标签,find_elements_by_xxx找的是所有符合条件的标签。
2、根据ID、CSS选择器和XPath获取,它们返回的结果完全一致。
3、另外,Selenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。
六、节点交互
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮时用click()方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(‘https://www.taobao.com‘)
input = browser.find_element_by_id(‘q‘)
input.send_keys(‘MAC‘) # 输入框接收内容
time.sleep(1)
input.clear() # 清空输入框
input.send_keys(‘IPhone‘)
button = browser.find_element_by_class_name(‘btn-search‘)
button.click() # 点击按钮
browser.quit()
七、动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from selenium import webdriver
from selenium.webdriver import ActionChains
from time import sleep
# 创建一个浏览器对象
bro = webdriver.Chrome(executable_path="chromedriver.exe")
# 发起url请求
bro.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
# 定位的标签是存在于iframe的子页面中,如果直接使用find做定位,是定位不到的
# 定位iframe中标签操作
# 第一步:定位到iframe标签位置
bro.switch_to.frame("iframeResult")
# 第二步:通过ID定位到需要拖动的标签
target_ele = bro.find_element_by_id("draggable")
# 创建一个拖动对象
action = ActionChains(bro)
# 点击拖动对象并长按保持
action.click_and_hold(target_ele)
# 模拟拖动5次,每次拖动17个像素点
for i in range(5):
# 执行拖动动作
action.move_by_offset(17, 0).perform()
# 每拖动17像素暂停5秒
sleep(2)
# 释放拖动对象句柄
action.release()
sleep(
2)
# 关闭浏览器
bro.quit()
八、执行JavaScript
对于某些操作,Selenium API并没有提供。比如,下拉进度条,它可以直接模拟运行JavaScript,此时使用execute_script()方法即可实现,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.jd.com/‘)
# 滑动鼠标到下一屏
browser.execute_script(‘window.scrollTo(0, document.body.scrollHeight)‘) # 竖直滑动,scrollHeight一屏高度
browser.execute_script(‘alert("123")‘) # js代码,提示框
九、获取页面源码数据
通过page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取信息了。
from selenium import webdriver
from time import sleep
# 创建一个浏览器对象
bro = webdriver.Chrome(executable_path="chromedriver.exe")
# 发起url请求
bro.get("http://www.jd.com/")
# 获取网页源码
page_text = bro.page_source
with open("jd.html", "w", encoding="utf-8") as fp:
fp.write(page_text)
sleep(
2)
# 关闭浏览器
bro.quit()
十、前进和后退
#模拟浏览器的前进后退
import time
from selenium import webdriver
browser=webdriver.Chrome()
browser.get(‘https://www.baidu.com‘)
browser.get(‘https://www.taobao.com‘)
browser.get(‘http://www.sina.com.cn/‘)
browser.back() # 后退到前一个访问页面
time.sleep(10)
browser.forward() # 前进到前一个访问页面
browser.close()
十一、标签属性
from selenium import webdriver
# 创建chrome浏览器对象
bro = webdriver.Chrome(executable_path="chromedriver.exe")
# 获取点击按钮的title属性的值
next_page = bro.find_element_by_id("pageIto_next").get_attribute("title")
十二、窗口句柄切换
# 获取所有窗口句柄
all_h = dri.window_handles
print(all_h)
# 切换最后窗口句柄
dri.switch_to.window(all_h[-1])
# 切换第一个窗口句柄
dri.switch_to.window(all_h[0])
# 查看当前窗口句柄 print(dri.current_window_handle)
十三、Cookie处理
使用Selenium,还可以方便地对Cookies进行操作,例如获取、添加、删除Cookies等。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.zhihu.com/explore‘)
print(browser.get_cookies()) # 获取当前cookie信息
# 添加cookie信息
browser.add_cookie({‘name‘: ‘name‘, ‘domain‘: ‘www.zhihu.com‘, ‘value‘: ‘germey‘})
print(browser.get_cookies())
# 删除所有cookie信息
browser.delete_all_cookies()
print(browser.get_cookies())
十四、异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
try:
browser=webdriver.Chrome()
browser.get(‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘)
browser.switch_to.frame(‘iframssseResult‘)
except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
browser.close()
十五、selenium规避被检测识别
现在不少大网站有对selenium采取了监测机制。比如正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为
undefined。而使用selenium访问则该值为true。那么如何解决这个问题呢?
只需要设置Chromedriver的启动参数即可解决问题。在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为[‘enable-automation‘],完整代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option
= ChromeOptions()
option.add_experimental_option(‘excludeSwitches‘, [‘enable-automation‘])
driver = Chrome(options=option)
十六、项目实例(selenium站长素材高清图片下载)
from selenium import webdriver
from time import sleep
base_url
= "http://sc.chinaz.com/tupian/weimeiyijingtupian.html"
# 创建一个浏览器句柄对象
dri = webdriver.Chrome(executable_path="chromedriver.exe")
# 跳转到指定url
dri.get(base_url)
# 点击跳转图片详情页
dri.find_element_by_xpath(‘//*[@id="container"]/div[1]/p/a‘).click()
# 获取所有窗口句柄
all_h = dri.window_handles
print(all_h)
# 切换到新窗口句柄
dri.switch_to.window(all_h[1])
# 查看当前窗口句柄
print(dri.current_window_handle)
sleep(2)
# 点击下载图片(方式一)
# btn = dri.find_element_by_xpath(‘/html/body/div[7]/div[5]/div[1]/div[6]/div[2]/div[1]/div/div[3]/a[2]‘)
# btn.click()
# xpath获取所有满足条件的结果,返回一个复数形式(列表)方式二
# btn = dri.find_elements_by_xpath(‘/html/body/div[5]/div[5]/div[1]/div[6]/div[2]/div[1]/div/div[3]/a[1]‘)
# print(btn)
# 网速慢可能拿不到结果,可以做异常捕获
# btn[0].click()
# 通过文本信息定位(方式三)
dri.find_element_by_link_text("广东电信下载").click()
sleep(1)
# 退出浏览器
十七、项目实例(selenium药监局企业名称获取)
from selenium import webdriver
from time import sleep
import requests
# ajax请求post获取企业详细内容
detail_url = "http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList"
headers
= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3573.0 Safari/537.36"
}
# 创建chrome浏览器对象
bro = webdriver.Chrome(executable_path="chromedriver.exe")
# 请求url,请求药监局主页面
bro.get("http://125.35.6.84:81/xk/")
# 定义一个列表:存放所有企业名
title_list = []
# 获取当前页的所有公司的名字
def get_company_title(json_data):
data_list = json_data["list"]
for data in data_list:
title = data[‘EPS_NAME‘]
title_list.append(title)
</span><span style="color: #0000ff;">return</span><span style="color: #000000;"> title_list
# 初始psge=1 获取第一页内容
page = 1
# post请求参数
def get_data(page):
data = {
‘on‘: ‘true‘,
‘page‘: page,
‘pageSize‘: ‘15‘,
‘productName‘: ‘‘,
‘conditionType‘: ‘1‘,
‘applyname‘: ‘‘,
‘applysn‘: ‘‘,
}
</span><span style="color: #0000ff;">return</span><span style="color: #000000;"> data
# 请求首页信息
page_text = requests.post(url=detail_url, data=get_data(page), headers=headers).json()
# 首页的公司名字
get_company_title(page_text)
print("获取第1页数据!!!")
# 循环获取其他页信息
for page in range(10):
# 定位到点击下一页按钮
next_btn = bro.find_element_by_id("pageIto_next")
# 点击下一页
next_btn.click()
# 延时2秒
sleep(2)
# 获取点击按钮的title值
next_page = bro.find_element_by_id("pageIto_next").get_attribute("title")
page_text = requests.post(url=detail_url, data=get_data(next_page), headers=headers).json()
get_company_title(page_text)
print("获取第页数据!!!".format(next_page))
# 打印获取的所有企业名字信息
print(title_list)
sleep(2)
# 关闭浏览器
bro.quit()
十八、selenium模拟登录qq空间,爬取数据
import requests
from selenium import webdriver
from lxml import etree
import time
driver
= webdriver.Chrome(executable_path=‘/Users/bobo/Desktop/chromedriver‘)
driver.get(‘https://qzone.qq.com/‘)
#在web 应用中经常会遇到frame 嵌套页面的应用,使用WebDriver 每次只能在一个页面上识别元素,对于frame 嵌套内的页面上的元素,直接定位是定位是定位不到的。
这个时候就需要通过switch_to_frame()方法将当前定位的主体切换了frame 里。
driver.switch_to.frame(‘login_frame‘) #login_frame 是ID值
driver.find_element_by_id(‘switcher_plogin‘).click()
#driver.find_element_by_id(‘u‘).clear()
driver.find_element_by_id(‘u‘).send_keys(‘328410948‘) #这里填写你的QQ号
#driver.find_element_by_id(‘p‘).clear()
driver.find_element_by_id(‘p‘).send_keys(‘xxxxxx‘) #这里填写你的QQ密码
driver.find_element_by_id(‘login_button‘).click()
time.sleep(2)
driver.execute_script(‘window.scrollTo(0,document.body.scrollHeight)‘)
time.sleep(2)
driver.execute_script(‘window.scrollTo(0,document.body.scrollHeight)‘)
time.sleep(2)
driver.execute_script(‘window.scrollTo(0,document.body.scrollHeight)‘)
time.sleep(2)
page_text = driver.page_source
tree
= etree.HTML(page_text)
#执行解析操作
li_list = tree.xpath(‘//ul[@id="feed_friend_list"]/li‘)
for li in li_list:
text_list = li.xpath(‘.//div[@class="f-info"]//text()|.//div[@class="f-info qz_info_cut"]//text()‘)
text = ‘‘.join(text_list)
print(text+‘\n\n\n‘)
driver.close()
一、selenium简介
1、什么是selenium
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法执行javaScript代码的问题。
2、selenium的用途
(1)、selenium可以驱动浏览器自动执行自定义好的逻辑代码,也就是可以通过代码完全模拟成人类使用浏览器自动访问目标站点并操作,那我们也可以拿它来做爬虫。
(2)、selenium本质上是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等...进而拿到网页渲染之后的结果,可支持多种浏览器
3、selenium是优缺点
(1)优点
优点就是可以帮我们避开一系列复杂的通信流程,例如在我们之前学习的requests模块,那么requests模块在模拟请求的时候是不是需要把素有的通信流程都分析完成后才能通过请求,然后返回响应。假如目标站点有一系列复杂的通信流程,例如的登录时的滑动验证等...那么你使用requests模块的时候是不是就特别麻烦了。不过你也不需要担心,因为网站的反爬策略越高,那么用户的体验效果就越差,所以网站都需要在用户的淫威之下降低安全策略。
再看一点requests请求库能不能执行js?是不是不能呀!那么如果你的网站需要发送ajax请求,异步获取数据渲染到页面上,是不是就需要使用js发送请求了。那浏览器的特点是什么?是不是可以直接访问目标站点,然后获取对方的数据,从而渲染到页面上。那这些就是使用selenium的好处!
(2)缺点
使用selenium本质上是驱动浏览器对目标站点发送请求,那浏览器在访问目标站点的时候,是不是都需要把静态资源都加载完毕。html、css、js这些文件是不是都要等待它加载完成。是不是速度特别慢。那用它的坏处就是效率极低!所以我们一般用它来做登录验证。
二、selenium的安装
1、下载selenium模块:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
或者在pycharm中下载
2、安装浏览器驱动
(1)、Google浏览器驱动:https://sites.google.com/a/chromium.org/chromedriver/downloads
注:把下载好的chromedriver.exe放到python安装路径的scripts目录中即可,
(2)、firefox浏览器驱动:
selenium3默认支持的webdriver是Firfox,而Firefox需要安装geckodriver
下载链接:https://github.com/mozilla/geckodriver/releases
三、selenium的基本使用
from selenium import webdriver # 用来驱动浏览器的
from selenium.webdriver import ActionChains # 破解滑动验证码的时候用的 可以拖动图片
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC # 和下面WebDriverWait一起用的
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time
driver=webdriver.Chrome()
try:
wait=WebDriverWait(driver,10)
#1、访问百度
driver.get(‘https://www.baidu.com/‘)
#2、查找输入框
# input_tag = wait.until(
# # 调用EC的presence_of_element_located()
# EC.presence_of_element_located(
# # 此处可以写一个元组
# # 参数1: 查找属性的方式
# # 参数2: 属性的名字
# (By.ID, "kw")
# )
# )
input_tag=wait.until(EC.presence_of_element_located((By.ID,"kw")))
#3、在搜索框在输入要搜索的内容
input_tag.send_keys(‘秦时明月‘)
# 4、按键盘回车键
input_tag.send_keys(Keys.ENTER)
time.sleep(3)
finally:
driver.close()
四、 等待元素被加载
selenium只是模拟浏览器的行为,而浏览器解析页面是需要时间的(执行css,js),一些元素可能需要过一段时间才能加载出来,为了保证所有元素都能查到,必须等待。
1、等待的方式分两种:
(1)、隐式等待:在browser.get(‘xxx‘)前就设置,针对所有元素有效
1 from selenium import webdriver
2 from selenium.webdriver import ActionChains
3 from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
4 from selenium.webdriver.common.keys import Keys #键盘按键操作
5 from selenium.webdriver.support import expected_conditions as EC
6 from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
7
8 browser=webdriver.Chrome()
9
10 #隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
11 browser.implicitly_wait(10)
12
13 browser.get(‘https://www.baidu.com‘)
14
15
16 input_tag=browser.find_element_by_id(‘kw‘)
17 input_tag.send_keys(‘美女‘)
18 input_tag.send_keys(Keys.ENTER)
19
20 contents=browser.find_element_by_id(‘content_left‘) #没有等待环节而直接查找,找不到则会报错
21 print(contents)
22
23 browser.close()
(2)、显式等待:在browser.get(‘xxx‘)之后设置,只针对某个元素有效
1 from selenium import webdriver
2 from selenium.webdriver import ActionChains
3 from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
4 from selenium.webdriver.common.keys import Keys #键盘按键操作
5 from selenium.webdriver.support import expected_conditions as EC
6 from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
7
8 browser=webdriver.Chrome()
9 browser.get(‘https://www.baidu.com‘)
10
11
12 input_tag=browser.find_element_by_id(‘kw‘)
13 input_tag.send_keys(‘美女‘)
14 input_tag.send_keys(Keys.ENTER)
15
16
17 #显式等待:显式地等待某个元素被加载
18 wait=WebDriverWait(browser,10)
19 wait.until(EC.presence_of_element_located((By.ID,‘content_left‘)))
20
21 contents=browser.find_element(By.CSS_SELECTOR,‘#content_left‘)
22 print(contents)
23
24
25 browser.close()
五、 选择器
1、基本使用方法
1 from selenium import webdriver # 用来驱动浏览器的
2 import time
3
4 ‘‘‘
5 ===============所有方法===================
6 element是查找一个标签
7 elements是查找所有标签
8
9 1、find_element_by_link_text 通过链接文本去找
10 2、find_element_by_id 通过id去找
11 3、find_element_by_class_name
12 4、find_element_by_partial_link_text
13 5、find_element_by_name
14 6、find_element_by_css_selector
15 7、find_element_by_tag_name
16 ‘‘‘
17 # 获取驱动对象、
18 driver = webdriver.Chrome()
19
20 try:
21
22 # 往百度发送请求
23 driver.get(‘https://www.baidu.com/‘)
24 driver.implicitly_wait(10)
25
26 # 1、find_element_by_link_text 通过链接文本去找
27 # 根据登录
28 # send_tag = driver.find_element_by_link_text(‘登录‘)
29 # send_tag.click()
30
31 # 2、find_element_by_partial_link_text 通过局部文本查找a标签
32 login_button = driver.find_element_by_partial_link_text(‘登‘)
33 login_button.click()
34 time.sleep(1)
35
36 # 3、find_element_by_class_name 根据class属性名查找
37 login_tag = driver.find_element_by_class_name(‘tang-pass-footerBarULogin‘)
38 login_tag.click()
39 time.sleep(1)
40
41 # 4、find_element_by_name 根据name属性查找
42 username = driver.find_element_by_name(‘userName‘)
43 username.send_keys(‘15622792660‘)
44 time.sleep(1)
45
46 # 5、find_element_by_id 通过id属性名查找
47 password = driver.find_element_by_id(‘TANGRAM__PSP_10__password‘)
48 password.send_keys(‘*******‘)
49 time.sleep(1)
50
51 # 6、find_element_by_css_selector 根据属性选择器查找
52 # 根据id查找登录按钮
53 login_submit = driver.find_element_by_css_selector(‘#TANGRAM__PSP_10__submit‘)
54 # driver.find_element_by_css_selector(‘.pass-button-submit‘)
55 login_submit.click()
56
57 # 7、find_element_by_tag_name 根据标签名称查找标签
58 div = driver.find_element_by_tag_name(‘div‘)
59 print(div.tag_name)
60
61 time.sleep(10)
62
63 finally:
64 driver.close()
2、xpath操作
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行查找。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
注意: 下面列出了最有用的路径表达式
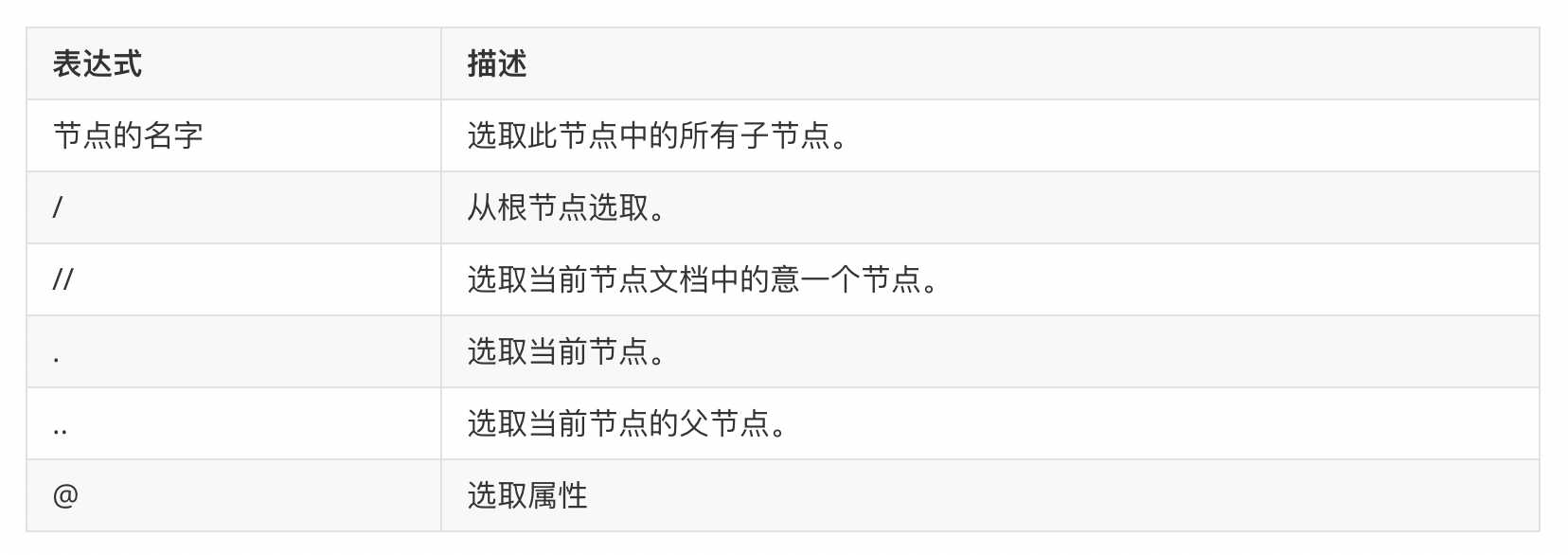
示例:
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果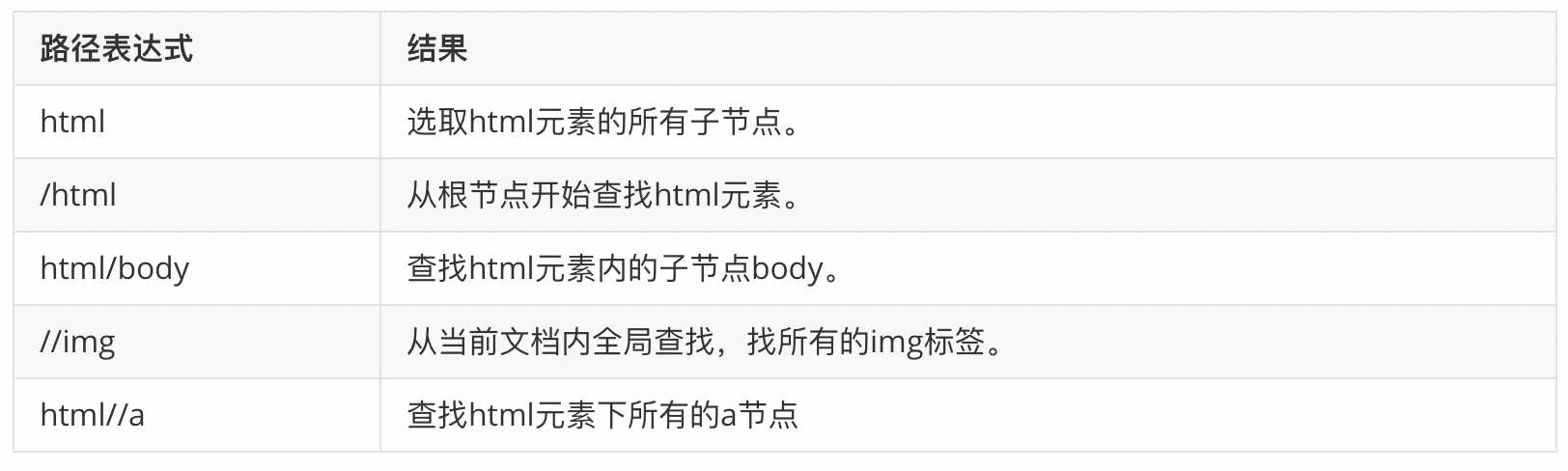
3. 获取标签属性(了解)
1 from selenium import webdriver
2
3 driver = webdriver.Chrome(r‘D:\BaiduNetdiskDownload\chromedriver_win32\chromedriver.exe‘)
4
5
6 try:
7 # 隐式等待: 写在get请求前
8 driver.implicitly_wait(5)
9
10 driver.get(‘https://doc.scrapy.org/en/latest/_static/selectors-sample1.html‘)
11
12 # 显式等待: 写在get请求后
13 # wait.until(...)
14
15 ‘‘‘
16
17 <html>
18 <head>
19 <base href=‘http://example.com/‘ />
20 <title>Example website</title>
21 </head>
22 <body>
23 <div id=‘images‘>
24 <a href=‘image1.html‘>Name: My image 1 <br /><img src=‘image1_thumb.jpg‘ /></a>
25 <a href=‘image2.html‘>Name: My image 2 <br /><img src=‘image2_thumb.jpg‘ /></a>
26 <a href=‘image3.html‘>Name: My image 3 <br /><img src=‘image3_thumb.jpg‘ /></a>
27 <a href=‘image4.html‘>Name: My image 4 <br /><img src=‘image4_thumb.jpg‘ /></a>
28 <a href=‘image5.html‘>Name: My image 5 <br /><img src=‘image5_thumb.jpg‘ /></a>
29 </div>
30 </body>
31 </html>
32 ‘‘‘
33 # 根据xpath语法查找元素
34 # / 从根节点开始找第一个
35 html = driver.find_element_by_xpath(‘/html‘)
36 # html = driver.find_element_by_xpath(‘/head‘) # 报错
37 print(html.tag_name)
38
39 # // 从根节点开始找任意一个节点
40 div = driver.find_element_by_xpath(‘//div‘)
41 print(div.tag_name)
42
43 # @
44 # 查找id为images的div节点
45 div = driver.find_element_by_xpath(‘//div[@id="images"]‘)
46 print(div.tag_name)
47 print(div.text)
48
49 # 找到第一个a节点
50 a = driver.find_element_by_xpath(‘//a‘)
51 print(a.tag_name)
52
53 # 找到所有a节点
54 a_s = driver.find_elements_by_xpath(‘//a‘)
55 print(a_s)
56
57 # 找到第一个a节点的href属性
58 # get_attribute:获取节点中某个属性
59 a = driver.find_element_by_xpath(‘//a‘).get_attribute(‘href‘)
60 print(a)
61
62 finally:
63 driver.close()
六、元素交互操作
1、点击、清除操作
1 from selenium import webdriver
2 from selenium.webdriver.common.keys import Keys
3 import time
4
5 driver = webdriver.Chrome(r‘D:\BaiduNetdiskDownload\chromedriver_win32\chromedriver.exe‘)
6
7 try:
8 driver.implicitly_wait(10)
9 # 1、往jd发送请求
10 driver.get(‘https://www.jd.com/‘)
11 # 找到输入框输入围城
12 input_tag = driver.find_element_by_id(‘key‘)
13 input_tag.send_keys(‘围城‘)
14 # 键盘回车
15 input_tag.send_keys(Keys.ENTER)
16 time.sleep(2)
17 # 找到输入框输入墨菲定律
18 input_tag = driver.find_element_by_id(‘key‘)
#清除输入框内原有的内容
19 input_tag.clear()
20 input_tag.send_keys(‘墨菲定律‘)
21 # 找到搜索按钮点击搜索
22 button = driver.find_element_by_class_name(‘button‘)
23 button.click()
24 time.sleep(10)
25
26 finally:
27 driver.close()
2、获取cookies (了解)
1 from selenium import webdriver
2 import time
3
4 driver = webdriver.Chrome(r‘D:\BaiduNetdiskDownload\chromedriver_win32\chromedriver.exe‘)
5
6 try:
7 driver.implicitly_wait(10)
8 driver.get(‘https://www.zhihu.com/explore‘)
9 print(driver.get_cookies())
10
11 time.sleep(10)
12 finally:
13 driver.close()
3、选项卡
1 选项卡管理:切换选项卡,有js的方式windows.open,有windows快捷键:
2 ctrl+t等,最通用的就是js的方式
3 import time
4 from selenium import webdriver
5
6 browser = webdriver.Chrome()
7 try:
8 browser.get(‘https://www.baidu.com‘)
9
10 # execute_script: 执行javascrpit代码
11 # 弹窗操作
12 # browser.execute_script(‘alert("tank")‘)
13 # 新建浏览器窗口
14 browser.execute_script(
15 ‘‘‘
16 window.open();
17 ‘‘‘
18 )
19 time.sleep(1)
20 print(browser.window_handles) # 获取所有的选项卡
21 # 切换到第二个窗口
22 # 新:
23 browser.switch_to.window(browser.window_handles[1])
24 # 旧:
25 # browser.switch_to_window(browser.window_handles[1])
26
27 # 第二个窗口往淘宝发送请求
28 browser.get(‘https://www.taobao.com‘)
29 time.sleep(5)
30
31 # 切换到第一个窗口
32 browser.switch_to_window(browser.window_handles[0])
33 browser.get(‘https://www.sina.com.cn‘)
34
35 time.sleep(10)
36 finally:
37 browser.close()
4、ActionChangs动作链
1 from selenium import webdriver
2 from selenium.webdriver import ActionChains
3 import time
4
5 driver = webdriver.Chrome()
6 driver.implicitly_wait(10)
7 driver.get(‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘)
8
9 try:
10
11 # driver.switch_to_frame(‘iframeResult‘)
12 # 切换到id为iframeResult的窗口内
13 driver.switch_to.frame(‘iframeResult‘)
14
15 # 源位置
16 draggable = driver.find_element_by_id(‘draggable‘)
17
18 # 目标位置
19 droppable = driver.find_element_by_id(‘droppable‘)
20
21 # 调用ActionChains,必须把驱动对象传进去
22 # 得到一个动作链对象,复制给一个变量
23 actions = ActionChains(driver)
24
25 # 方式一: 机器人
26 # 瞬间把源图片位置秒移到目标图片位置
27 # actions.drag_and_drop(draggable, droppable) # 编写一个行为
28 # actions.perform() # 执行编写好的行为
29
30
31 # 方式二: 模拟人的行为
32 source = draggable.location[‘x‘]
33 target = droppable.location[‘x‘]
34 print(source, target)
35
36 distance = target - source
37 print(distance)
38
39 # perform:每个动作都要调用perform执行
40
41 # 点击并摁住源图片
42 ActionChains(driver).click_and_hold(draggable).perform()
43
44 s = 0
45 while s < distance:
46 # 执行位移操作
47 ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform()
48 s += 2
49
50 # 释放动作链
51 ActionChains(driver).release().perform()
52
53 time.sleep(10)
54
55
56 finally:
57 driver.close()
5、前进、后退
1 from selenium import webdriver
2 import time
3
4 driver = webdriver.Chrome()
5
6 try:
7 driver.implicitly_wait(10)
8 driver.get(‘https://www.jd.com/‘)
9 driver.get(‘https://www.baidu.com/‘)
10 driver.get(‘https://www.cnblogs.com/‘)
11
12 time.sleep(2)
13
14 # 回退操作
15 driver.back()
16 time.sleep(1)
17 # 前进操作
18 driver.forward()
19 time.sleep(1)
20 driver.back()
21 time.sleep(10)
22
23 finally:
24 driver.close()
