上一次学的spark的transform操作里面,有一些函数的描述是“参数是函数”,而向函数传递这个作为参数的函数的用法一般有两种
匿名函数,可以减少代码量。匿名函数的定义 => 左边是参数,参数可以省略参数类型,右边是函数体部分,之前的例子里面其实用到过很多次
比如说下面这个例子
val nums = sc.parallelize(List(1,2,39,53,80))
// 把每一个数字都加1
nums.map(x => x+1).collect()
// 筛选大于50的数字
nums.filter(x => x>50).collect()
// 筛选出奇数
nums.filter(x => x%2 != 0).collect()下面这个例子,这个方法是所在的类的静态方法,从而不声明这个类的实例就能使用这个方法
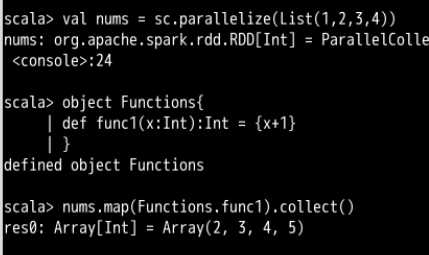
这个方法一样是把每个元素的值都加一,作为map的参数来使用,由map函数“惰性执行”
下面这个是一个例子,输出了一个出乎我们意料的结果
val data = Array(1,2,3,4,5)
var counter = 0
var rdd = sc.parallelize(data)
rdd.foreach(x => counter+=x)
println("Counter value:" + counter)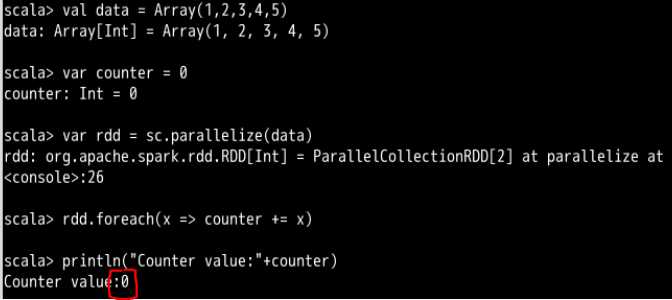
这个例子里面,counter+=x这句明显是有对counter的值的修改的,而最后的结果显示counter的value是0
对于这种现象的原因的解释是
因为在执行过程中,Spark 会将 RDD 拆分为多个 task 并分发给不同的执行器操作,而分发到每个执行器的 counter 是经过复制的,执行器彼此之间是不能相互访问的,这就会导致执行器在执行 foreach 方法的时候只能修改自身的值,驱动程序中的 counter 值没有被修改,最终输出的 counter 值依然是 0。执行器要在 RDD 上进行计算时必须对执行器节点可见的变量和方法就称为闭包,在这里就是 foreach() 方法。
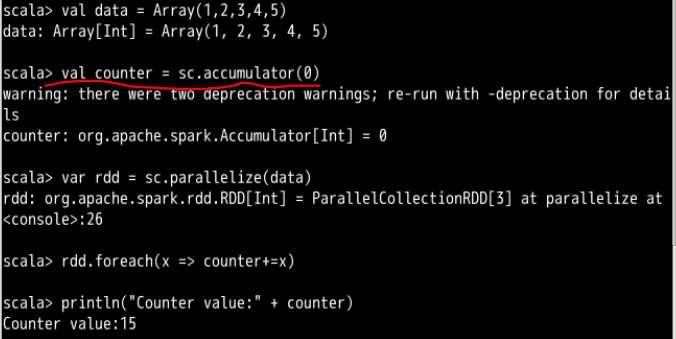
用共享全局变量可以解决这个问题
比如刚才报错的那个例子,像这样使用共享全局变量的累加器
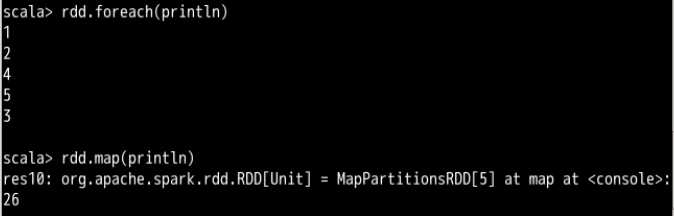
一个比较常见的习惯是使用 rdd.foreach(println)或rdd.map(println)来打印 RDD 的元素。这在单台机器上运行是能够成功打印出结果的。但是考虑到我们上面关于闭包的问题,如果把这句代码放在集群模式下运行,执行器输出写入的是执行器的 stdout,而不是驱动程序的 stdout。那么要想在驱动程序中打印元素,应该怎么办呢?如果数据量不多的话可以使用 collect() 方法,也就是 rdd.collect().foreach(println);如果数据量很大的话可以使用 take() 方法,也就是 rdd.take(num).foreach(println)。
当传递给 Spark 的函数在集群中各个节点运行时,函数所用的变量在每个节点上都是独立的副本,变量被复制到所有节点上,并且相互独立,更新后也不会传递给驱动程序(主节点?)。Spark 为了能够让多个节点之间共享变量,提供了两种方法:广播变量和累加器
广播变量可以在每个机器上缓存一个只读的变量,可以通过sc.broadcast(v)方法创建。广播变量能够更高效的进行数据集的分配

累加器在理解变量作用范围的那个例子里面是使用过的,用来解决那个最后counter的value是0的那个例子
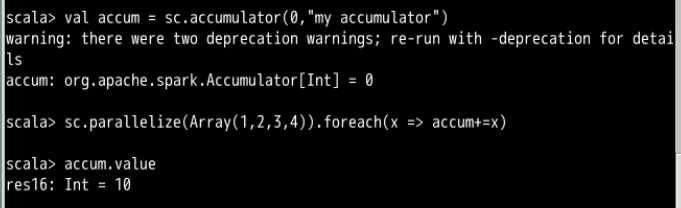
嗯,基本和刚才的那个例子一样。
大部分 Spark 操作支持含任意类型对象的 RDD ,少数特殊操作仅仅在键值(key-value)对的 RDD 可用。最常见的是分布式 "shuffle" 操作,例如根据一个 key 对一组数据进行分组和聚合。PairRDDFunctions 类中提供了键值对操作,它自动包装元组的 RDD
常用的map()方法就可以把一个普通的RDD转化为一个键值对RDD,这里是依据每一条的第一个单词作为键值的,后面参数函数的参数列表的第二个参数x,是用来生成键值对的后半部分的值的,如果没有这个",x",那么结果里面的元素就会变成每个字符串的第一个单词
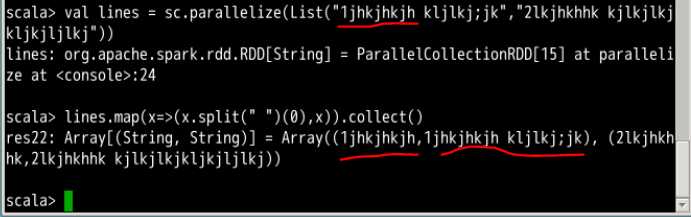
加不加参数函数的第二参数x的对比

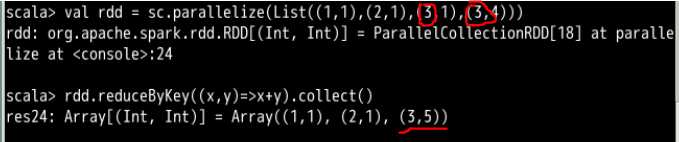
这个函数的参数是函数,可以用来合并相同的键值,其实就是按照相同的键值对rdd里面的键值对搞reduce
这个例子里面,因为list里面的元素是一个个键值对,最开始通过list生成的rdd就是一个键值对rdd
然后按照参数函数,也就是做加法,来对相同键值的键值对进行合并
这个函数用来对具有相同键值的值进行分组,效果如图

这个函数的参数是函数,作用是给键值对RDD的每个键对应的值应用参数函数的那个函数

这个函数的参数是函数,作用是,对键值对 RDD 中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录,通常用于符号化
比如说下面这句代码,1这个键对应的值是1,值1到4有1、2、3、4四种,最后1为键的键值对就有四个
(2,1) (3,1) 同理,后面的(3,4),因为4到4只有4一个数,最后就不新生成键值对,还是那个(3,4)
效果在代码下面的截图里面
rdd.flatMapValues(x=>(x to 4)).collect()
这个函数,会返回一个只包含所有键的RDD,重复的键会合并为一个
比如:
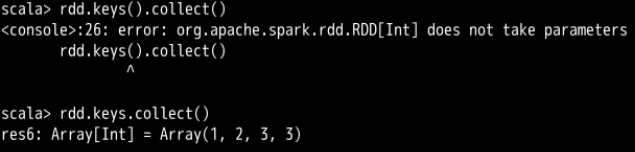
昂对,这个没有括号,这个keys类似于java对象的属性了
这个就和上面那个keys相对应了,就是返回一个新的rdd里面包含原来rdd每个键值对的值

这个函数会返回一个RDD其内容按照原RDD键值对的键来排序

教程的原话对这个函数的描述是这样的:
combineByKey() 是键值对 RDD 中较为核心的高级函数,很多其它聚合函数都是在这个之上实现的,通过使用 combineByKey() 函数,我们能够更加清楚的明白 spark 底层如何进行分布式计算。其中这 3 个参数分别对应着聚合操作的 3 个步骤。
combineByKey() 会遍历分区的所有元素,在这个过程中只会出现两种情况:一种是该元素对应的键没有遇到过;另外一种是该元素对应的键和之前的某一个元素的键是相同的。
如果是新的元素,combineByKey() 会使用 createCombiner() 函数来创建该键对应累加器的初始值。注意,是在每一个分区中第一次出现新键的时候创建,而不是在整个 RDD 中。
在当前分区中,如果遇到该键是已经存在的键,那么就调用 mergeValue() 方法将该键对应累加器的当前值与这个新的值合并。
由于有多个分区,每个分区都是独立处理的,所以最后需要调用 mergeCombiners() 方法将各个分区的结果合并。
教程里面的代码是这样的:
val input = sc.parallelize(Seq(("t1", 1), ("t1", 2), ("t1", 3), ("t2", 2), ("t2", 5)))
val result = input.combineByKey(
// 分区内遇到新键时,创建 (累加值,出现次数) 的键值对
(v) => (v, 1),
// 分区内遇到已经创建过相应累加器的旧键,就更新对应累加器
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
// 多个分区遇到同一个键的累加器,就更新主累加器
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
// 求平均值
).map{ case (key, value) => (key, value._1 / value._2.toFloat) }
// 输出结果
result.collectAsMap().foreach(println(_))这里面(v)=>(v,1)的情况是遇到一个之前没有遇到过的键,而这里的v不代表这个键而是这个键后面的值。也就是说,如果遇到了一个新的键,会为这个键的值创建一个键值对(v,1),代表这个键的值出现了一次。
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),这一行是在遇到之前有过的键的情况下,用当前累加器acc和这个键对应的值v生成一个键值对,用这个键值对,更新累加器。更新累加器的方法是,用原累加器的第一个元素加上新的值,后面累加器第二个用来记录次数的那个加一。
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)指明了不同分区的累加器的合并方法,就是两个累加器元素各自相加,形成一个新的累加器。
最后遍历结束之后,(key,value)这个键值对里面的value已经不是原来value那个数字了,value里面装的是一个键值对:(累加值,出现次数),而且遍历结束之后就已经没有重复的键了。
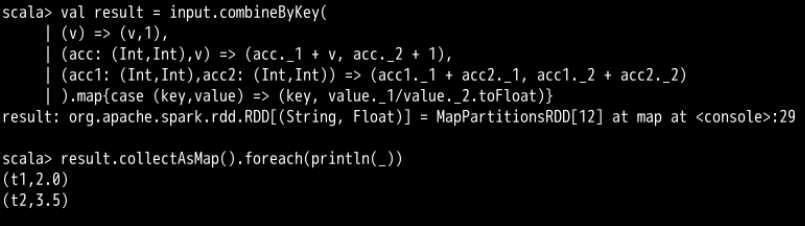
但是这个case还没太弄清楚,因为我scala基础的确不牢,……,而且下面如果不加case报的错误是这样的。
说它期望你输的是一个能够接受两元组的单参数函数,所以,就需要加case?
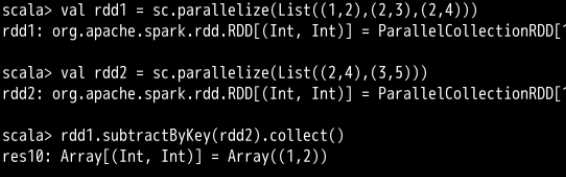
删掉 RDD1 中键与 RDD2 的键相同的元素,因为是以RDD1为基础的,所以RDD2里面的额外元素就不会出现了
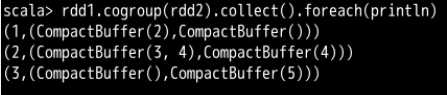
将两个 RDD 中拥有相同键的数据分组到一起。
对每个键对应的元素分别计数

返回给定键对应的所有值
如图按照给定的键2进行查找,得到键2对应的值3和4,打包进同一个数组里

将结果以映射表的形式返回,方便查询。

但是4个键值对只生成了3条映射
有些函数只能用于特定类型的 RDD 上,比如 mean()、sum() 只能用于数值 RDD,而 reduceByKey()、groupByKey() 只能用于键值对 RDD。在 Scala 中这些函数都没有定义在标准的 RDD 类中,如果想要使用这些附加函数,我们必须确保获得了正确的专用 RDD 类。
在 Scala 中可以通过隐式转换将 RDD 转为有特定函数的 RDD ,也就是记得加上 import org.apache.spark.SparkContext._。
spark RDD 具有惰性求值的特性,而在实际的数据处理过程中,我们通常会接触到 TB 级别的数据量,并且会重复调用同一组数据,为了节省计算资源,我们可以选择把会频繁使用到的中间数据缓存或持久化到内存或是磁盘中,方便下一次调用。
首先,我们需要引入相关的模块:import org.apache.spark.storage._
我们可以对 RDD 使用 cache() 方法进行缓存,这里的缓存相当于对 RDD 执行默认存储等级(MEMORY_ONLY)的持久化操作,也就是在集群相关节点的内存中进行缓存。
如果不需要缓存的数据了,可以执行 rdd.unpersist()清除缓存
val rdd = sc.textFile("/etc/protocols")
rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
rdd.cache() //这里还没有执行缓存
rdd.take(10) // 遇到执行操作开始真正计算RDD并缓存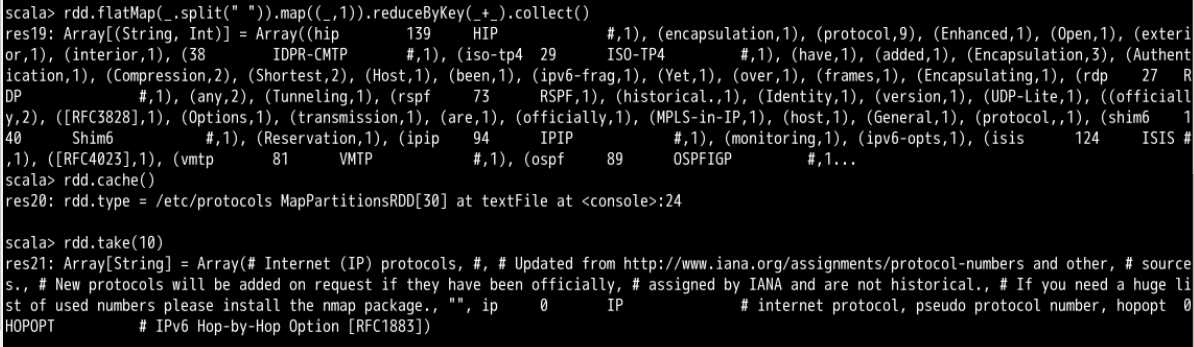
我们可以使用 persist() 函数来进行持久化,一般默认的存储空间还是在内存中,如果内存不够就会写入磁盘中。persist 持久化分为不同的等级,还可以在存储等级的末尾加上_2用于把持久化的数据存为 2 份,避免数据丢失。
下面的列表列出了不同的持久化等级:
| 级别 | 使用的空间 | 是否在内存中 | 是否在磁盘上 |
|---|---|---|---|
| MEMORY_ONLY | 高 | 是 | 否 |
| MEMORY_ONLY_SER | 低 | 是 | 否 |
| MEMORY_AND_DISK | 高 | 部分 | 部分 |
| MEMORY_AND_DISK_SER | 低 | 部分 | 部分 |
| DISK_ONLY | 低 | 否 | 是 |
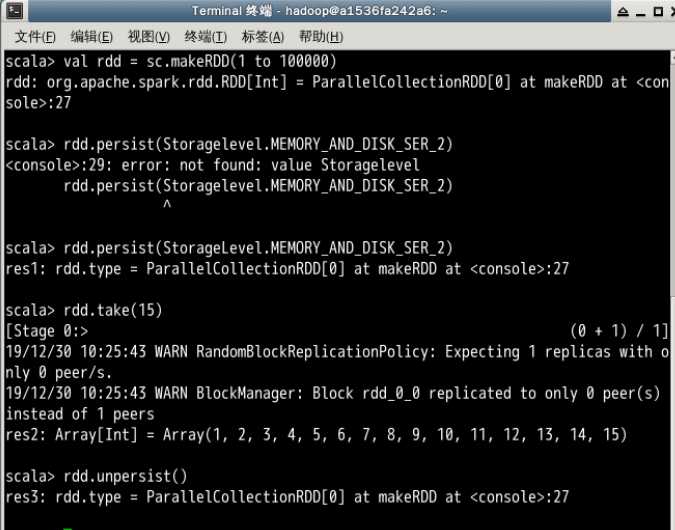
原文:https://www.cnblogs.com/ltl0501/p/12118715.html