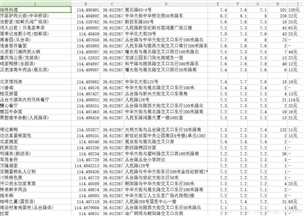
从大众点评网上爬取泉州美食html页面数据,包括‘店名‘, ‘点评数‘, ‘花费‘, ‘菜系‘, ‘地点‘, ‘口味‘, ‘环境‘, ‘服务‘等分析。
import requests
from bs4 import BeautifulSoup
url = ‘http://www.dianping.com/quanzhou/ch10‘
def getHTMLText(url,timeout=30):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ‘产生异常‘
html = getHTMLText(url)
soup=BeautifulSoup(html,‘html.parser‘)
print(soup.prettify())

#导入库
import requests
from bs4 import BeautifulSoup
import csv
import os
# 链接url
def gethtml(num):
try:
number = num + 1
print(‘{:<2d}{:<}{:<}‘.format(number,‘页‘,‘:‘))#打印正在爬取的页数
url = ‘https://www.dianping.com/quanzhou/ch0‘ + str(num)
r = requests.get(url)
r.raise_for_status()
r.encoding = ‘utf-8‘#转码
return r.text
except Exception as e:
print(e)
return ‘‘
# 爬取数据
def findhtml(text, ul):
soup = BeautifulSoup(text, ‘lxml‘)
links = soup.find_all(‘li‘, class_=‘‘)
for link in links:
ui = []
if link.h4 != None:#爬取店铺名
ui.append(link.h4.string)
print(‘{:^50s}‘.format(link.h4.string))#打印店铺名
a1 = link.find(‘a‘, class_=‘review-num‘)#爬取点评数
if a1:
ui.append(a1.b.string)
else:
ui.append(‘ ‘)
a2 = link.find(‘a‘, class_=‘mean-price‘)#爬取花费
try:
if a2:
ui.append(a2.b.string)
else:
ui.append(‘ ‘)
except:
ui.append(‘‘)
a3 = link.find(‘a‘, {‘data-midas-extends‘: ‘module=5_ad_kwcat‘})#爬取菜系
if a3:
ui.append(a3.string)
else:
ui.append(‘ ‘)
a4 = link.find(‘a‘, {‘data-midas-extends‘: ‘module=5_ad_kwregion‘})#爬取口味,环境,服务
span1 = link.find(‘span‘, {‘class‘: ‘addr‘})
if a4 and span1:
ui.append(a4.string + ‘ ‘ + span1.string)
elif a4 == None and span1 != None:
ui.append(span1.string)
elif a4 != None and span1 == None:
ui.append(a4.string)
else:
ui.append(‘ ‘)
try:
spans = link.find(‘span‘, class_=‘comment-list‘)
spanss = spans.contents
ui.append(spanss[1].b.string)
ui.append(spanss[3].b.string)
ui.append(spanss[5].b.string)
except:
ui.append(‘‘)
ui.append(‘‘)
ui.append(‘‘)
ul.append(ui)
# 保存数据,路径D盘
def savehtml(uls):
path = ‘D://数据‘
if not os.path.exists(path):
os.makedirs(path)
with open(os.path.join(path, ‘大众点评南京美食.csv‘),‘w+‘) as f:
writer = csv.writer(f)
writer.writerow([‘店名‘, ‘点评数‘, ‘菜系‘, ‘地点‘, ‘口味‘, ‘环境‘, ‘服务‘,‘人流量‘,‘人均花费‘])
for i in range(len(uls)):
try:
if uls[i]:
writer.writerow(
[uls[i][0], uls[i][1], uls[i][2], uls[i][3], uls[i][4], uls[i][5], uls[i][6], uls[i][7]])#写入csv文件
except:
continue
# main()
def main(i):
ulist = []
it = int(i)
for number in range(it):
html = gethtml(number)
findhtml(html, ulist)
savehtml(ulist)
yeshu = input(‘输入要查询的总页数(1~50):‘)
main(yeshu)
#导入数据集
import pandas as pd
data=pd.DataFrame(pd.read_excel(‘D://数据.xls‘))
#获取目标信息
def getData(titleList,nameList,numList,html):
#创建BeautifulSoup对象
soup = BeautifulSoup(html,"html.parser")
#获取标题信息
for a in soup.find_all("a",{"class":"title"}):
#将标题信息存在列表中
titleList.append(a.string)
for i in soup.find_all("i",{"class":"acnick"}):
nameList.append(i.string)
for i in soup.find_all("i",{"class":"js-num"}):
List.append(i.string)
数据.drop(‘点评数‘,axis=1,inplace=True) #删除无效列点评数
数据.head()#显示前五行
数据.drop(‘点赞数‘,axis=1,inplace=True) #删除无效列点赞数
数据.head()#显示前五行
数据.describe()
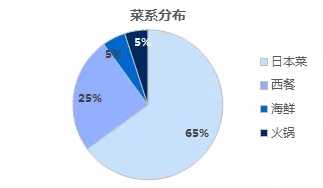
#饼图 import matplotlib.pyplot as plt Labels = [‘日本菜‘, ‘西餐‘, ‘海鲜‘, ‘火锅‘] Data = [356,92,45,14,121,194] #绘制饼图 plt.pie(Data ,labels=Type, autopct=‘%1.1f%%‘) plt.axis(aspect=‘equal‘) #将横、纵坐标轴标准化处理,设置显示图像为正圆 plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] #设置字体样式 plt.title(‘菜系分布‘) plt.show()
import requests
from bs4 import BeautifulSoup
import os
url = "http://www.dianping.com/quanzhou/ch10"
html = getHTMLText(url) #获取html页面代码
filelist = [] #存储文件名
getFile(html,filelist)
urllist = []
getURL(html,urllist)
def getHTMLText(url): #请求url链接
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
def getFile(html,filelist): #获取文件名
soup = BeautifulSoup(html,"html.parser")
for p in soup.find_all("p"): #遍历所有属性为p的p标签
for a in p.find_all("a"): #遍历p标签中的a标签
return urllist
def dataStore(file,name): #数据存储
try:
os.mkdir("D:\数据表")
except:
""
try:
with open("D:\\数据表\\{}.xls".format(name),"wb") as fp:#创建文件存储爬取到的数据
fp.write(file.content)
print("下载成功")
except:
"存储失败"
for i in range(0,len(urllist)):
#将目标信息存储在本地
file=requests.get(urllist[i])
dataStore(file,filelist[i])
原文:https://www.cnblogs.com/tuying/p/12098791.html