Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
淘二淘大学生二手网站主页推荐商品的爬取
2.主题式网络爬虫爬取的内容与数据特征分析
爬取的内容:
标题、发布时间、价格、旧价格、浏览人数、想要人数、交易地址、卖家、交易方式
数据特征分析:
分析新旧价格的差异以及想要的人数。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
1、利用requests库中的get()进行网页请求,观察输出状态码特征
2、使用etree进行网页解析
3、通过循环结合xpath方法获取每个商品详细的地址信息
4、对详细地址信息的循环进行对页面中所要爬取的商品详细信息进行筛选
5、通过os和pandas将数据保持到csv中,以便后期进行数据分析和数据清洗
技术难点:
1、在对网页进行请求时,要加入user-Agent和cookie请求的头部信息,验证进入网页前的身份
2、注意利用DataFrame进行表格标题的设置
3、注意在对详情页面URL的循环时,利用的是获取到的详情页面地址。
4、每一个要获取的商品信息都各不相同
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
通过浏览器的开发者模式,进入到elements中,发现所有的商品都处于唯一的div[@class="list-body"]的ul下的li标签中。一条商品一个li标签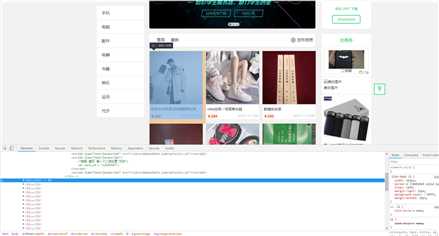
2.Htmls页面解析
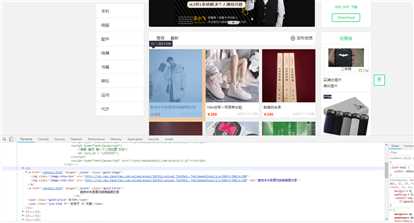
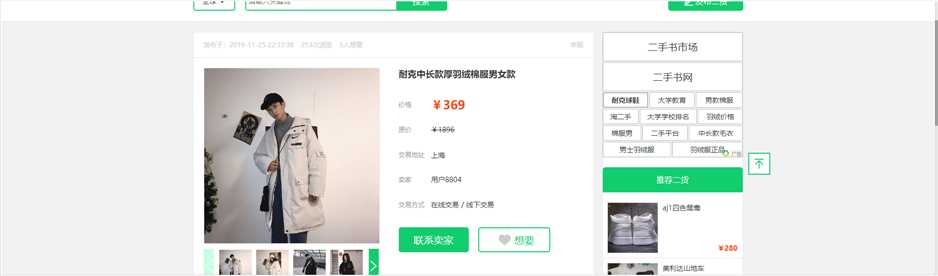
通过开发者模式,可以发现每一件商品的详细信息都处于一个a标签中,可以通过a标签进入到详细页面中。
3.节点(标签)查找方法与遍历方法
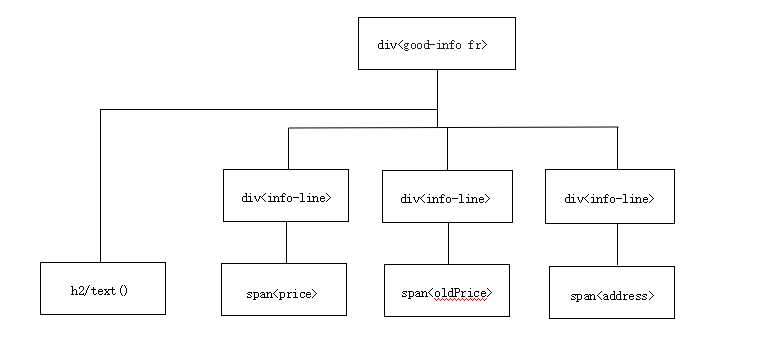
(必要时画出节点树结构)
节点(标签)的查找方法使用xpath方法,获取ul标签下的li标签,在进入里标签获取其名称价格、名称等。遍历方法则使用for的循环获取所有的URL,在依次获取所有的数据。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
2.对数据进行清洗和处理
1 #导入pandas并读取前5行 2 import pandas as pd 3 taoertao=pd.DataFrame(pd.read_csv(‘D:/python代码存放/TaoErTao.csv‘)) 4 taoertao.head()
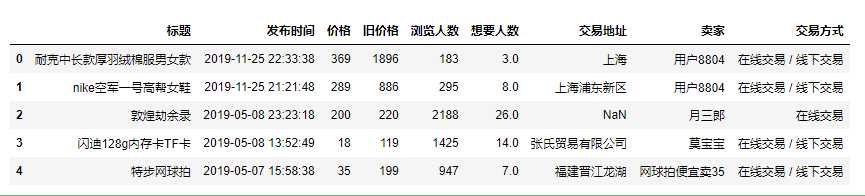
1 #重复值处理 2 taoertao.duplicated()

1 #重复值处理 2 taoertao=taoertao.drop_duplicates() 3 taoertao.duplicated()

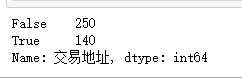
1 #获取交易地址的空值数 2 taoertao["交易地址"].isnull().value_counts()
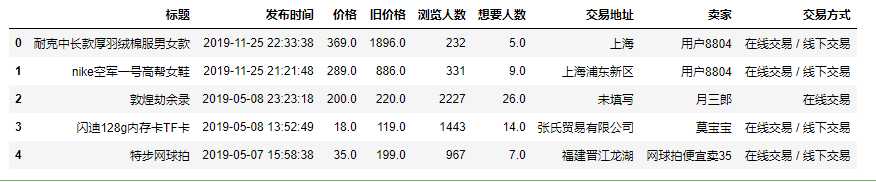
1 #将交易地址的空值设置为未填写 2 taoertao["交易地址"]=taoertao["交易地址"].fillna("未填写") 3 taoertao.head()
1 #数据异常值处理 2 taoertao.describe()
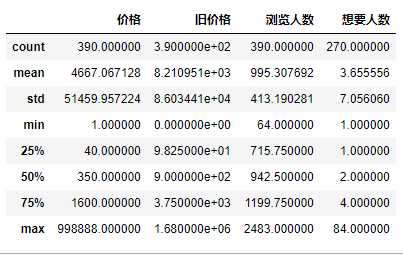
1 #数据异常值处理,假设想要人数max为异常数值 2 taoertao.replace([1.000000],taoertao["想要人数"].mean())
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
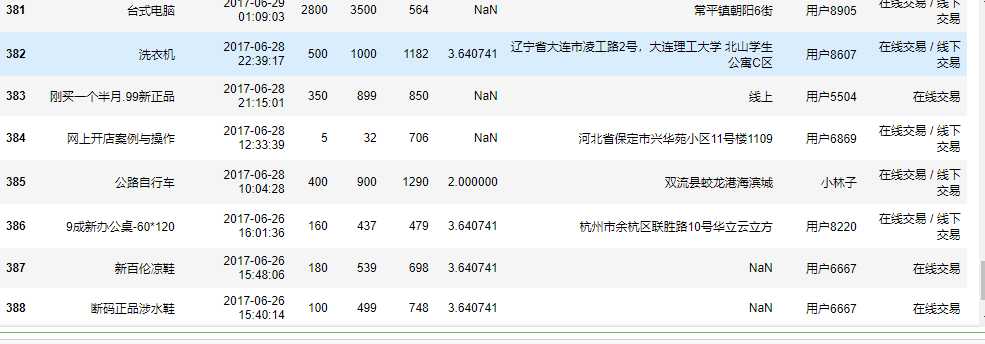
1 import numpy as np 2 #查看价格分布 3 taoertao["价格"].quantile(np.arange(0,1,0.1))
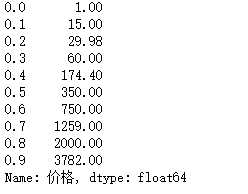
1 import seaborn as sns 2 sns.kdeplot(taoertao[‘价格‘]
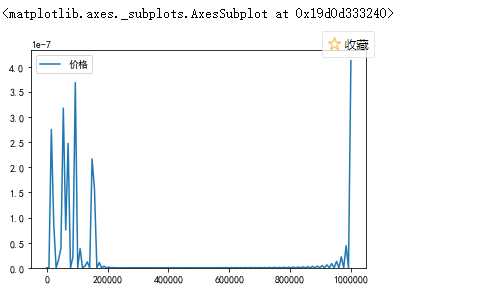
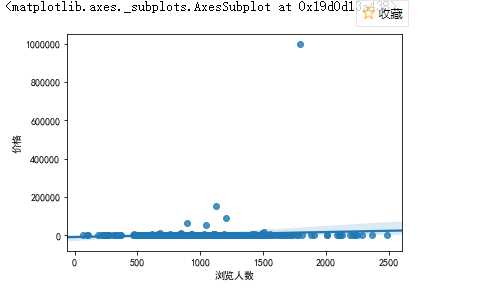
1 #获取价格与旧价格之间的关系 2 import seaborn as sns 3 import matplotlib.pyplot as plt 4 plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] 5 plt.rcParams[‘axes.unicode_minus‘] = False 6 sns.regplot(taoertao["价格"],taoertao["旧价格"])
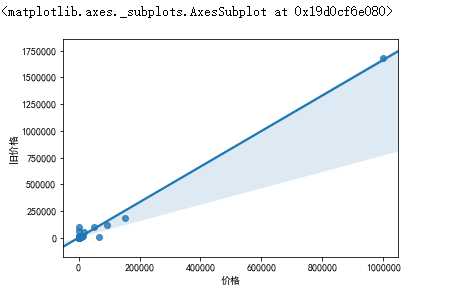
1 #获取浏览人数与想要人数之间的关系 2 sns.regplot(taoertao["浏览人数"],taoertao["想要人数"])
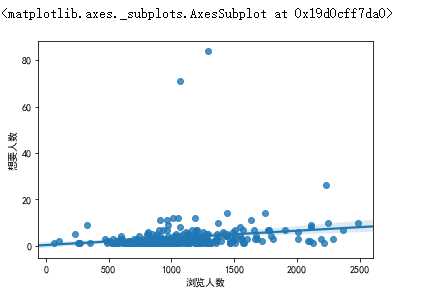
1 #获取浏览人数与价格之间的关系 2 sns.regplot(taoertao["浏览人数"],taoertao["价格"])
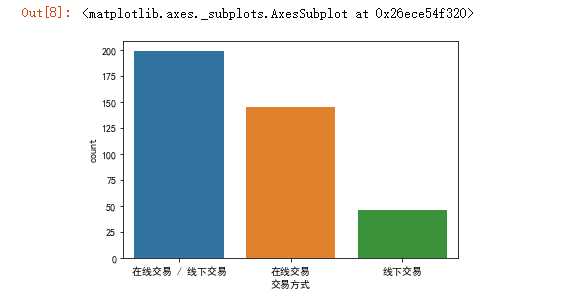
#使用柱状图查看淘二淘上商品的交易方式 import seaborn as sns import matplotlib.pyplot as plt plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.rcParams[‘axes.unicode_minus‘] = False sns.countplot(taoertao[‘交易方式‘])
5.数据持久化
6.附完整程序代码
#导入模块 from operator import contains import requests from lxml import html etree = html.etree from pandas import DataFrame import os #设置请求头 headers={ ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3‘, ‘Accept-Encoding‘: ‘gzip, deflate‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘, ‘Cache-Control‘: ‘no-cache‘, ‘Connection‘: ‘keep-alive‘, ‘Cookie‘: ‘taoertao.com=eyJhcmVhIjoib0Nabi85MmFES1REazk5SU5memJHdER5SmhwR0drdEd2a2hYTkx3NGlncE5Ba3RWdlY1UXJ1cUNLaVc2aEErL08xZUgwcEYyOXJpVGxjWloyVTRyS0pvQk9XNkllLzV1cnNaUHdSd2FSZ3FzTU81SkJ0aFBLVlgwbjVvMEpISnIifQ==; taoertao.com.sig=GQzrRg2vFHuiuwRokaAgeuBGnr4; UM_distinctid=16ef2ea28222e4-063814fcb90cf8-386a410b-100200-16ef2ea2823298; Hm_lvt_b43531d7c229bad3bcbfbc7991208c60=1576033463; CNZZDATA1255800214=978591821-1576028318-null%7C1576109523; Hm_lpvt_b43531d7c229bad3bcbfbc7991208c60=1576109562‘, ‘Host‘: ‘www.taoertao.com‘, ‘Pragma‘: ‘no-cache‘, ‘Upgrade-Insecure-Requests‘: ‘1‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36‘ } file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), ‘TaoErTao.csv‘) #csv文件命名 #设置获取地址的方法 def get_dateil_urls(url): # 获取页面内容 #使用requests模块的get函数向url发送一个get请求,将返回值,赋给response response = requests.get(url, headers=headers) #将HTTP响应内容进行解码 text = response.content.decode("utf-8"); # 解析页面内容 html = etree.HTML(text) #获取ul中class="list-con specialList"的ul ul = html.xpath(‘//ul[@class="clearfix"]‘)[0] #查找ul下所有的li标签 lis = ul.xpath(‘./li‘) # 声明数组,用于存储获取到的商品链接 date_urls=[] #遍历lis for li in lis: # 获取商品的详细链接 game_url = li.xpath(‘./a/@href‘) # 将lis中的数据取出,以字符串的形式覆盖原来的game_url game_url = game_url[1] #将获取到的数据进行拼接 game_url="http://www.taoertao.com"+game_url #将game_url加入到date_urls中 date_urls.append(game_url) return date_urls def main(): page=14 for i in range(1,page): url="http://www.taoertao.com/?&p="+str(i) TaoNei=get_dateil_urls(url) for TiaoXian in TaoNei: Subordinat_Goods = {} # 创建字典,用于存入数据 # 使用requests模块的get函数向url发送一个get请求,并设置请求头,将返回值赋给response response = requests.get(TiaoXian, headers=headers) text = response.content.decode("utf-8") html = etree.HTML(text) # 查找html->div[class=goods-properties]->p[class=row] title = html.xpath(‘//div[@class="detail fl clearfix"]‘) #获取发布时间 Goods_time=title[0].xpath("./div[@class=‘title‘]/span[@class=‘publish-time fl‘]/text()")[0][4:] # print(Goods_time) #获取浏览人数 Goods_browse=title[0].xpath("./div[@class=‘title‘]/span[@class=‘view-number fl‘]/text()")[0].split("次")[0] # print(Goods_browse) #获取想要人数 if(len(title[0].xpath("./div[@class=‘title‘]/span[@class=‘view-number fl‘]/text()"))>=2): Goods_want=title[0].xpath("./div[@class=‘title‘]/span[@class=‘view-number fl‘]/text()")[1].split("人")[0] else: Goods_want=‘null‘ # print(Goods_want) #商品的标题 Goods_title=title[0].xpath(‘./div[@class="good-info fr"]/h2/text()‘)[0] # print(Goods_title) Goods_nav=title[0].xpath(‘./div[@class="good-info fr"]/div[@class="info-line"]/span[@class="param-name"]/text()‘) #获取class属性包含param-value的标签的值 Goods_nav_value=title[0].xpath(‘./div[@class="good-info fr"]/div[@class="info-line"]/span[contains(@class,"param-value")]/text()‘) # print(Goods_nav_value) #获取价格 if("价格" in Goods_nav): index = Goods_nav.index("价格") if (contains(Goods_nav_value[index][1:], "元")): Goods_price = Goods_nav_value[index][1:].split("元")[0] else: Goods_price = Goods_nav_value[index][1:] else: Goods_price=‘null‘ #获取旧价格 if ("原价" in Goods_nav): index = Goods_nav.index("原价") if(contains(Goods_nav_value[index][1:],"元")): Goods_old_price = Goods_nav_value[index][1:].split("元")[0] else: Goods_old_price = Goods_nav_value[index][1:] else: Goods_old_price = ‘null‘ # print(Goods_old_price) #获取交易地址 if ("交易地址" in Goods_nav): index = Goods_nav.index("交易地址") Goods_address = Goods_nav_value[index] else: Goods_address = ‘null‘ #获取卖家信息 if ("卖家" in Goods_nav): index = Goods_nav.index("卖家") Goods_seller = Goods_nav_value[index] else: Goods_seller = ‘null‘ # print(Goods_seller) #获取交易方式 if ("交易方式" in Goods_nav): index = Goods_nav.index("交易方式") Goods_Transaction = Goods_nav_value[index] else: Goods_Transaction = ‘null‘ # print(Goods_Transaction) Subordinat_Goods[‘标题‘]=Goods_title Subordinat_Goods[‘发布时间‘] = Goods_time Subordinat_Goods[‘价格‘] = Goods_price Subordinat_Goods[‘旧价格‘] = Goods_old_price Subordinat_Goods[‘浏览人数‘] = Goods_browse Subordinat_Goods[‘想要人数‘] = Goods_want Subordinat_Goods[‘交易地址‘] = Goods_address Subordinat_Goods[‘卖家‘] = Goods_seller Subordinat_Goods[‘交易方式‘] = Goods_Transaction print(Subordinat_Goods) df = DataFrame(Subordinat_Goods, index=[0]) if os.path.exists(file_path): # 字符编码采用utf-8 df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") # 写入数据 else: df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig") if __name__ == ‘__main__‘: main()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)淘二淘二手商品的价格越高,其原来的价格也越高
(2)淘二淘二手商品的浏览人数普遍集中在1000人左右,同时想要的人数集中在7人左右
(3)两种交易方式中,线上交易普遍多于线下交易
2.对本次程序设计任务完成的情况做一个简单的小结。
经过本次用Python对淘二淘网站的爬取,对爬取方式有了一个初步的理解,更认知到现在的自己所学到的Python还只是冰山一角,为以后的Python学习增添了动力。
原文:https://www.cnblogs.com/chenguilai/p/12061550.html