一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取淘手游王者荣耀租号的质量
2.主题式网络爬虫爬取的内容与数据特征分析
最短租期,记时价格,段位,英雄数量,以及皮肤数量
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
创建一个get的类,定义get_alldata()方法用来获取网页上的全部信息,get_detail()方法用来对整数数据的进一步加工和提取,再用字典把数据存储起来。
先对整个淘手游的页面进行抓取,然后在对整个租号频道进行抓取,最后在对王者荣耀频道进行抓取
技术难点是,对整个王者荣耀进行抓取无法抓取到比较准确的数据,以及写代码出现的错误
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
每页25项数据,爬取了49页,数据量为1225条。通过F12查看网页源代码分析需要提取的数据是否存在动态生成的数据,任意查看一个数据项中与原网页中的数据对比后,发现所需要爬取的数据都是静态的。
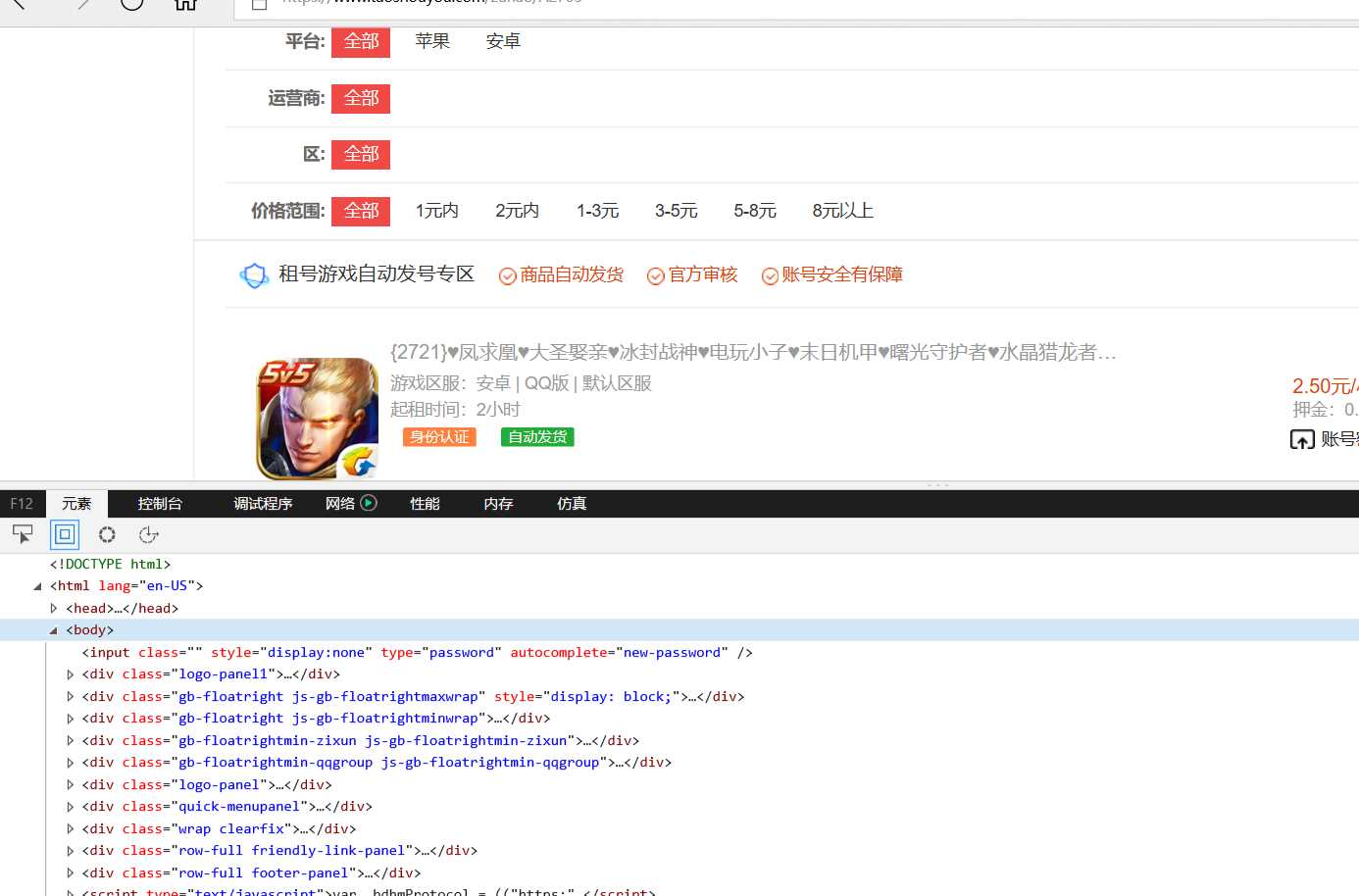
2.Htmls页面解析
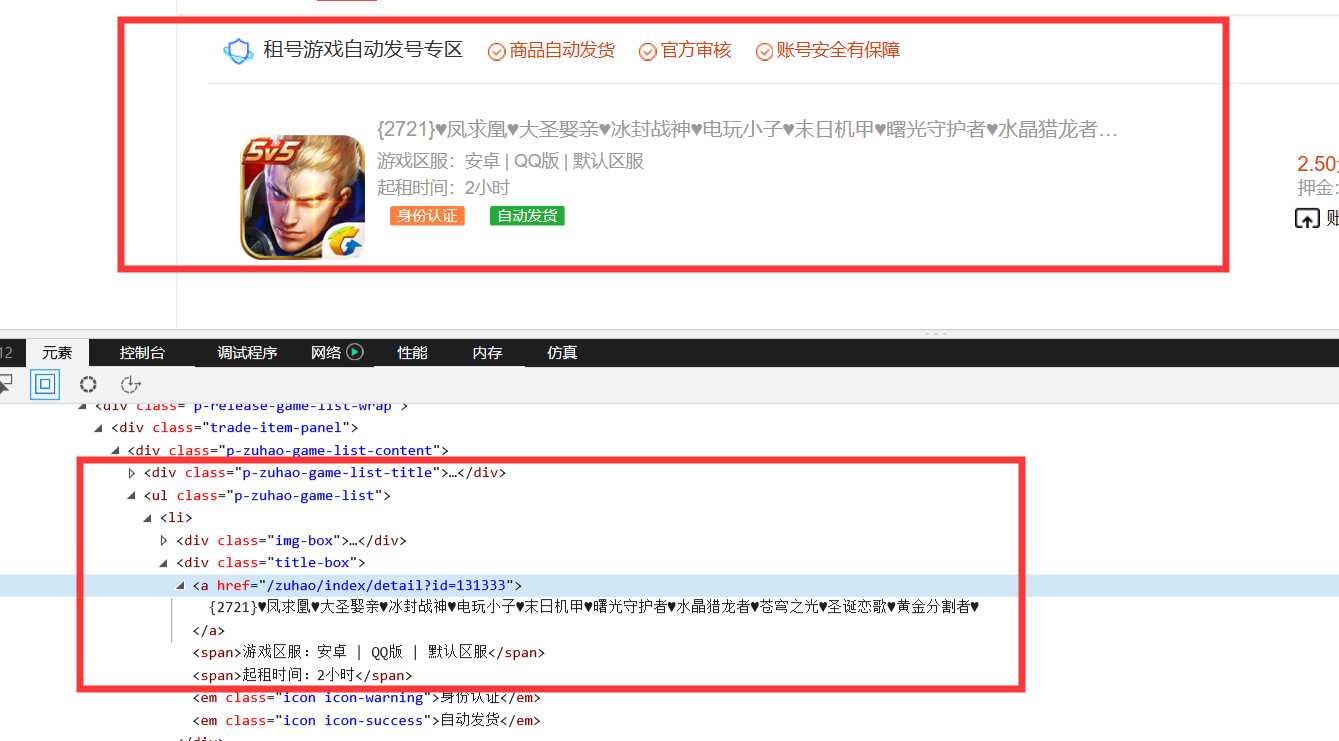
需要摘取的内容有
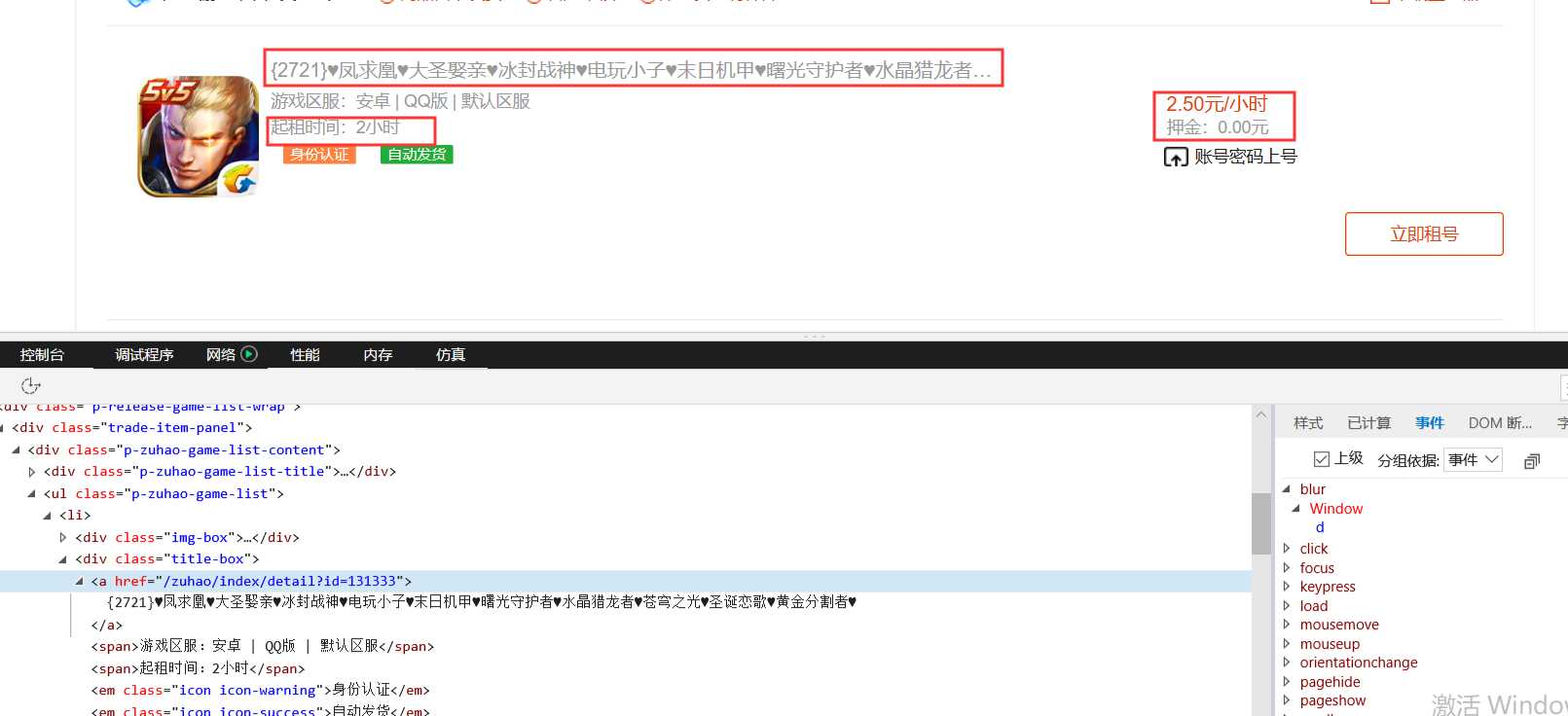
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
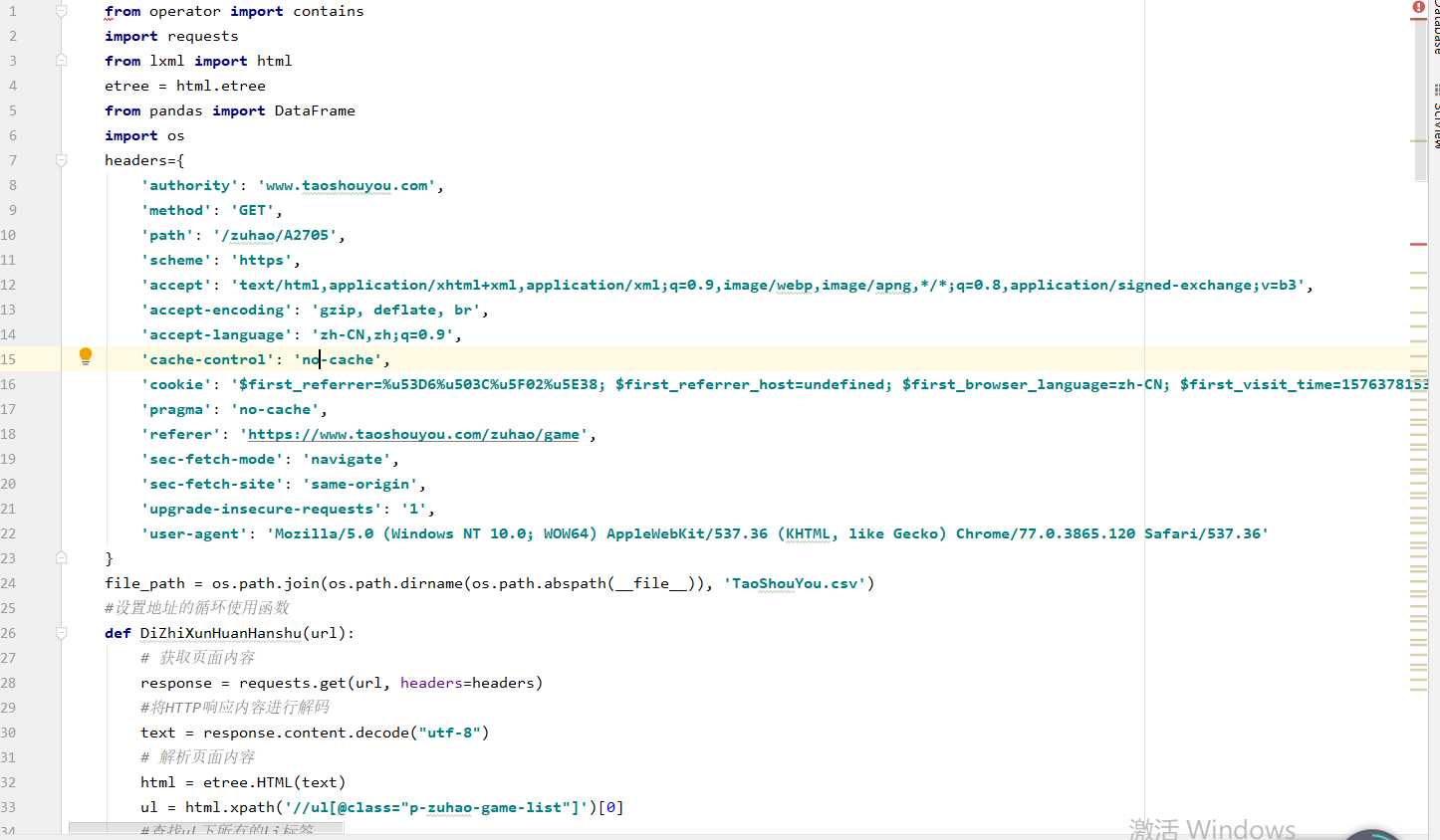
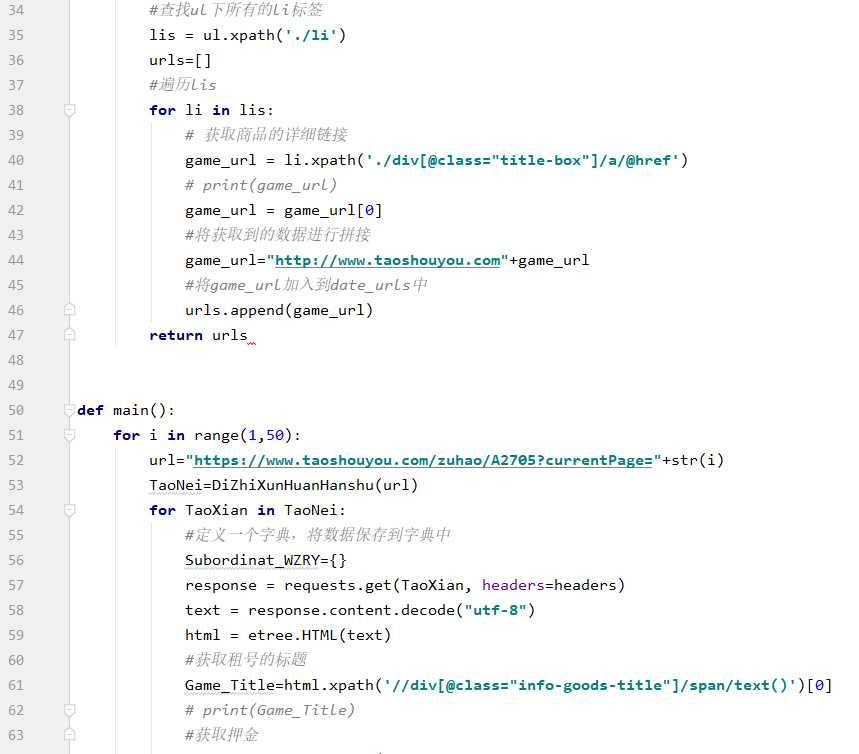
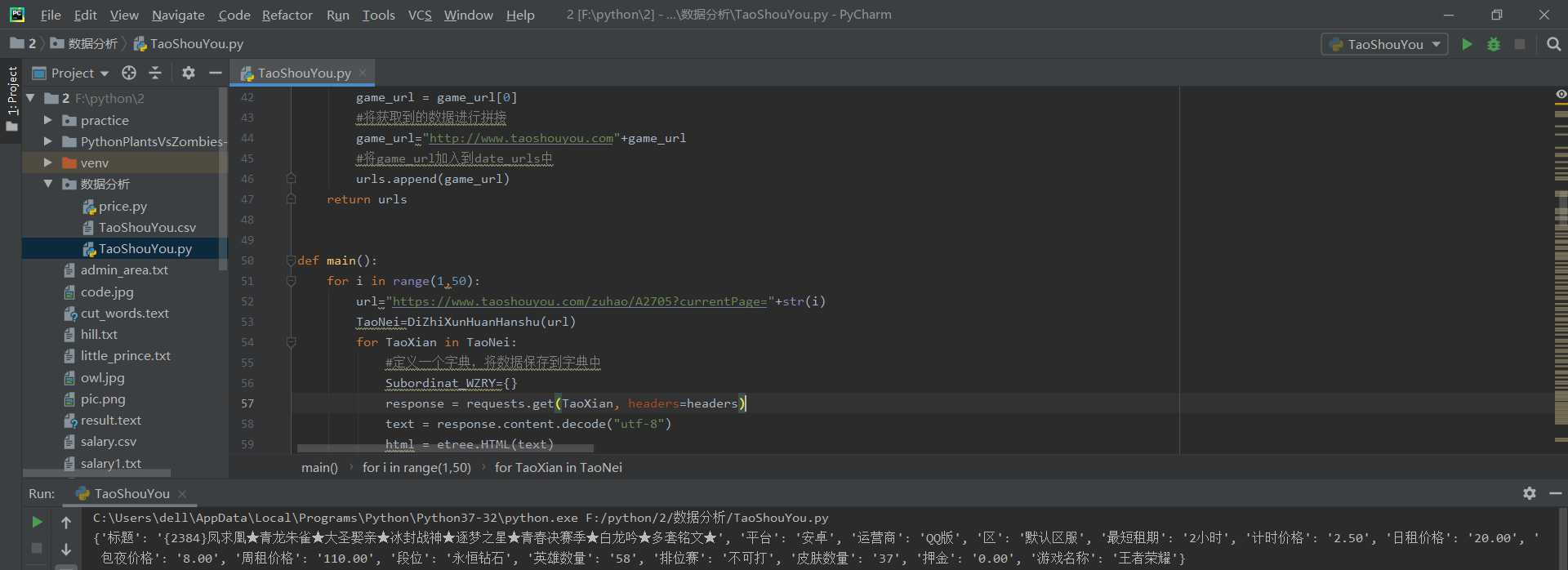
2.对数据进行清洗和处理
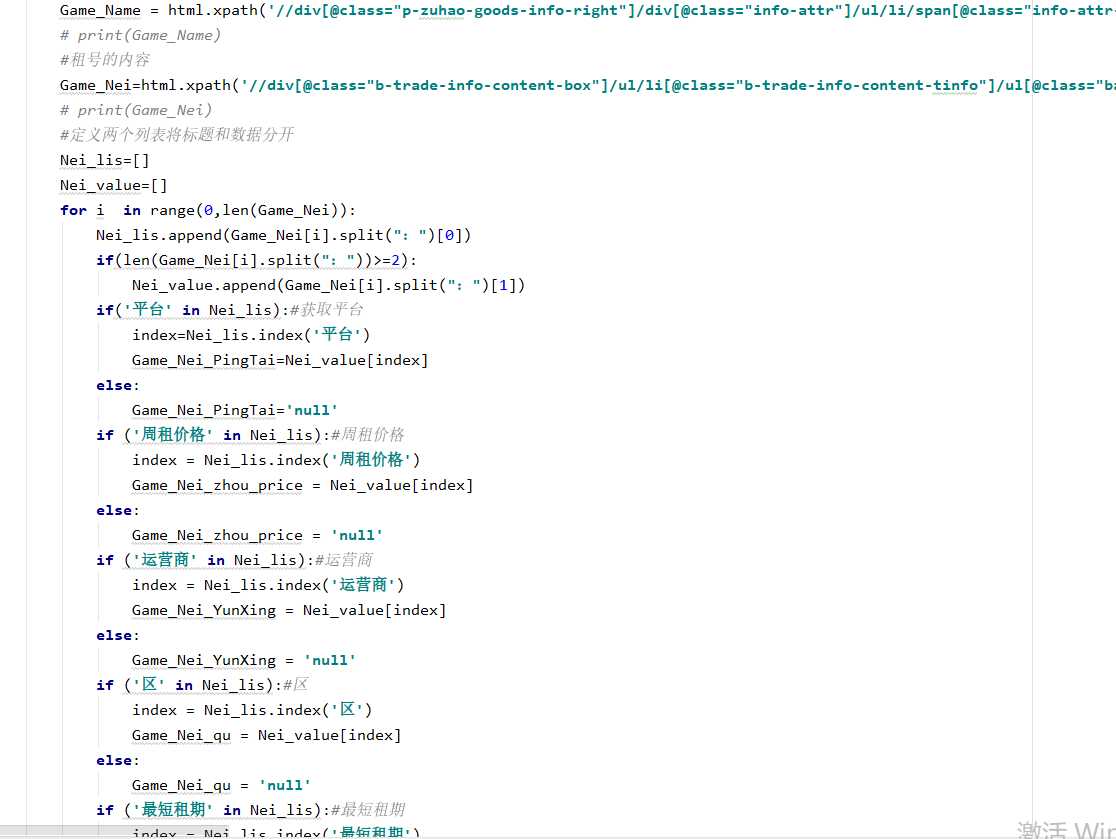

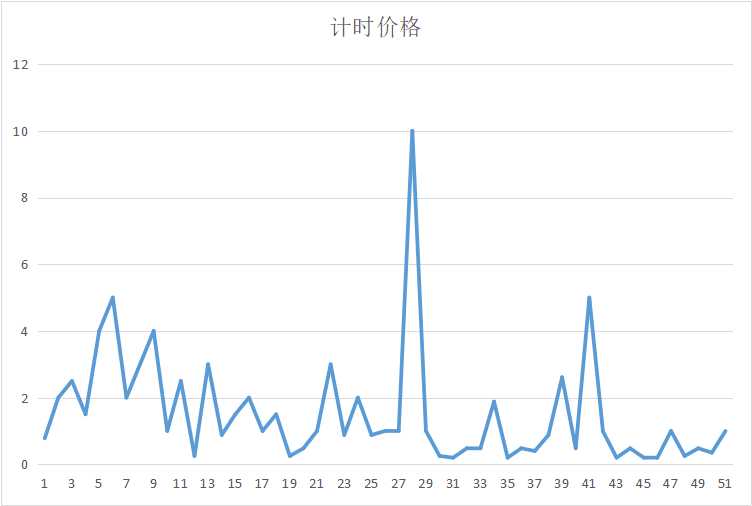
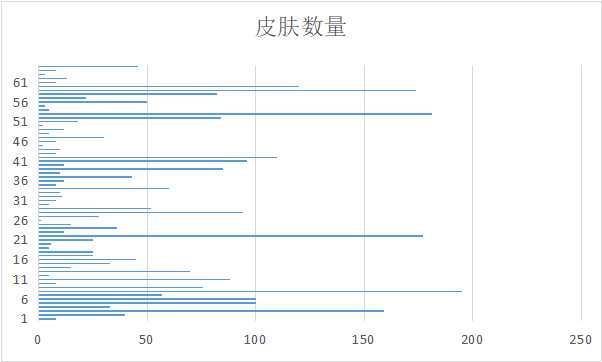
5.数据持久化
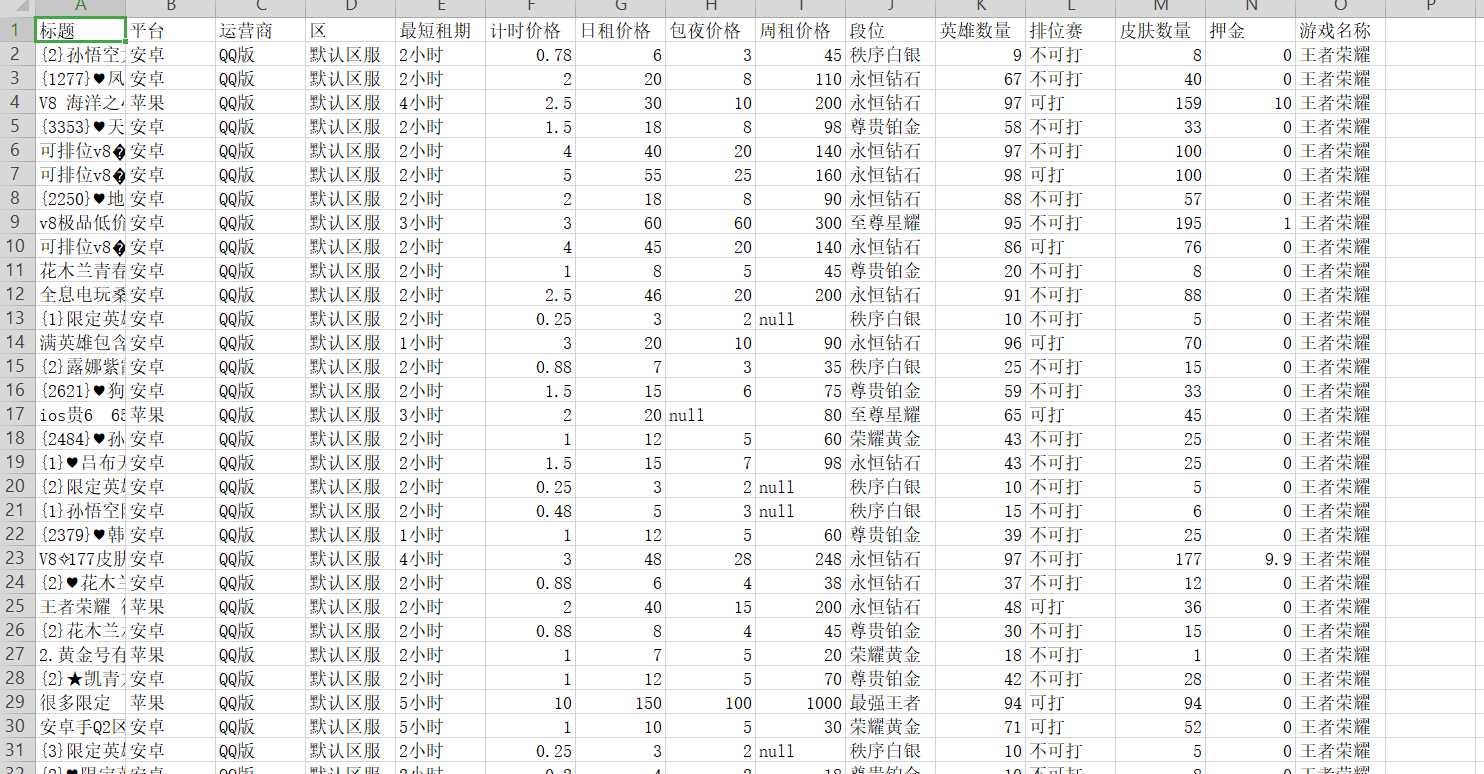
6.附完整程序代码
from operator import contains
import requests
from lxml import html
etree = html.etree
from pandas import DataFrame
import os
headers={
‘authority‘: ‘www.taoshouyou.com‘,
‘method‘: ‘GET‘,
‘path‘: ‘/zuhao/A2705‘,
‘scheme‘: ‘https‘,
‘accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3‘,
‘accept-encoding‘: ‘gzip, deflate, br‘,
‘accept-language‘: ‘zh-CN,zh;q=0.9‘,
‘cache-control‘: ‘no-cache‘,
‘cookie‘: ‘$first_referrer=%u53D6%u503C%u5F02%u5E38; $first_referrer_host=undefined; $first_browser_language=zh-CN; $first_visit_time=1576378153653; TSYUUID=e6567672-904c-4e6f-b0b1-9c58c4f77fa6; __cfduid=dbf3c95deea7228c6f987b797793f1ede1576377683; $first_referrer=%u53D6%u503C%u5F02%u5E38; $first_referrer_host=undefined; $first_browser_language=zh-CN; tsyguestid=tsyguest_A54DC56F77EB; PHPSESSID=ab46ad03ca8707d22b561a5f3994e312; Hm_lvt_3479dfbef7091d5aa569ec56e13113df=1576377683,1576377899,1576377978; Hm_lvt_417fdf811fee757b9b1f949949acba5c=1576377683,1576377899,1576377978; Hm_lpvt_3479dfbef7091d5aa569ec56e13113df=1576378020; $first_visit_time=1576378093578; Hm_lpvt_417fdf811fee757b9b1f949949acba5c=1576378154‘,
‘pragma‘: ‘no-cache‘,
‘referer‘: ‘https://www.taoshouyou.com/zuhao/game‘,
‘sec-fetch-mode‘: ‘navigate‘,
‘sec-fetch-site‘: ‘same-origin‘,
‘upgrade-insecure-requests‘: ‘1‘,
‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36‘
}
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), ‘TaoShouYou.csv‘)
#设置地址的循环使用函数
def DiZhiXunHuanHanshu(url):
# 获取页面内容
response = requests.get(url, headers=headers)
#将HTTP响应内容进行解码
text = response.content.decode("utf-8")
# 解析页面内容
html = etree.HTML(text)
ul = html.xpath(‘//ul[@class="p-zuhao-game-list"]‘)[0]
#查找ul下所有的li标签
lis = ul.xpath(‘./li‘)
urls=[]
#遍历lis
for li in lis:
# 获取商品的详细链接
game_url = li.xpath(‘./div[@class="title-box"]/a/@href‘)
# print(game_url)
game_url = game_url[0]
#将获取到的数据进行拼接
game_url="http://www.taoshouyou.com"+game_url
#将game_url加入到date_urls中
urls.append(game_url)
return urls
def main():
for i in range(1,50):
url="https://www.taoshouyou.com/zuhao/A2705?currentPage="+str(i)
TaoNei=DiZhiXunHuanHanshu(url)
for TaoXian in TaoNei:
#定义一个字典,将数据保存到字典中
Subordinat_WZRY={}
response = requests.get(TaoXian, headers=headers)
text = response.content.decode("utf-8")
html = etree.HTML(text)
#获取租号的标题
Game_Title=html.xpath(‘//div[@class="info-goods-title"]/span/text()‘)[0]
# print(Game_Title)
#获取押金
Game_Money=html.xpath(‘//div[@class="p-zuhao-goods-info-right"]/div[@class="info-attr"]/ul/li/span[@class="info-attr-value"]/text()‘)[1].split("元")[0]
# print(Game_Money)
#获取游戏名称
Game_Name = html.xpath(‘//div[@class="p-zuhao-goods-info-right"]/div[@class="info-attr"]/ul/li/span[@class="info-attr-value"]/text()‘)[0]
# print(Game_Name)
#租号的内容
Game_Nei=html.xpath(‘//div[@class="b-trade-info-content-box"]/ul/li[@class="b-trade-info-content-tinfo"]/ul[@class="base-desc "]/li/span/text()‘)
# print(Game_Nei)
#定义两个列表将标题和数据分开
Nei_lis=[]
Nei_value=[]
for i in range(0,len(Game_Nei)):
Nei_lis.append(Game_Nei[i].split(":")[0])
if(len(Game_Nei[i].split(":"))>=2):
Nei_value.append(Game_Nei[i].split(":")[1])
if(‘平台‘ in Nei_lis):#获取平台
index=Nei_lis.index(‘平台‘)
Game_Nei_PingTai=Nei_value[index]
else:
Game_Nei_PingTai=‘null‘
if (‘周租价格‘ in Nei_lis):#周租价格
index = Nei_lis.index(‘周租价格‘)
Game_Nei_zhou_price = Nei_value[index]
else:
Game_Nei_zhou_price = ‘null‘
if (‘运营商‘ in Nei_lis):#运营商
index = Nei_lis.index(‘运营商‘)
Game_Nei_YunXing = Nei_value[index]
else:
Game_Nei_YunXing = ‘null‘
if (‘区‘ in Nei_lis):#区
index = Nei_lis.index(‘区‘)
Game_Nei_qu = Nei_value[index]
else:
Game_Nei_qu = ‘null‘
if (‘最短租期‘ in Nei_lis):#最短租期
index = Nei_lis.index(‘最短租期‘)
Game_Nei_duan_Time = Nei_value[index]
else:
Game_Nei_duan_Time = ‘null‘
if (‘计时价格‘ in Nei_lis):#计时价格
index = Nei_lis.index(‘计时价格‘)
Game_Nei_Time_price = Nei_value[index]
else:
Game_Nei_Time_price = ‘null‘
if (‘日租价格‘ in Nei_lis):#日租价格
index = Nei_lis.index(‘日租价格‘)
Game_Nei_Day_price = Nei_value[index]
else:
Game_Nei_Day_price = ‘null‘
if (‘包夜价格‘ in Nei_lis):#包夜价格
index = Nei_lis.index(‘包夜价格‘)
Game_Nei_Ye_price = Nei_value[index]
else:
Game_Nei_Ye_price = ‘null‘
if (‘段位‘ in Nei_lis):#段位
index = Nei_lis.index(‘段位‘)
Game_Nei_Duanwei = Nei_value[index]
else:
Game_Nei_Duanwei = ‘null‘
if (‘英雄数量‘ in Nei_lis):#英雄数量
index = Nei_lis.index(‘英雄数量‘)
Game_Nei_Yingxiong_Count = Nei_value[index]
else:
Game_Nei_Yingxiong_Count = ‘null‘
if (‘排位赛‘ in Nei_lis):#排位赛
index = Nei_lis.index(‘排位赛‘)
Game_Nei_Paiwei = Nei_value[index]
else:
Game_Nei_Paiwei = ‘null‘
if (‘皮肤数量‘ in Nei_lis):#皮肤数量
index = Nei_lis.index(‘皮肤数量‘)
Game_Nei_Pifu_Count = Nei_value[index]
else:
Game_Nei_Pifu_Count = ‘null‘
Subordinat_WZRY[‘标题‘]=Game_Title
Subordinat_WZRY[‘平台‘]=Game_Nei_PingTai
Subordinat_WZRY[‘运营商‘] =Game_Nei_YunXing
Subordinat_WZRY[‘区‘] =Game_Nei_qu
Subordinat_WZRY[‘最短租期‘] =Game_Nei_duan_Time
Subordinat_WZRY[‘计时价格‘] =Game_Nei_Time_price
Subordinat_WZRY[‘日租价格‘] =Game_Nei_Day_price
Subordinat_WZRY[‘包夜价格‘] =Game_Nei_Ye_price
Subordinat_WZRY[‘周租价格‘] =Game_Nei_zhou_price
Subordinat_WZRY[‘段位‘] =Game_Nei_Duanwei
Subordinat_WZRY[‘英雄数量‘] =Game_Nei_Yingxiong_Count
Subordinat_WZRY[‘排位赛‘] =Game_Nei_Paiwei
Subordinat_WZRY[‘皮肤数量‘] =Game_Nei_Pifu_Count
Subordinat_WZRY[‘押金‘] =Game_Money
Subordinat_WZRY[‘游戏名称‘] =Game_Name
print(Subordinat_WZRY)
df = DataFrame(Subordinat_WZRY, index=[0])
if os.path.exists(file_path):
df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig")
else:
df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig")
if __name__ == ‘__main__‘:
main()
四、结论(10分)
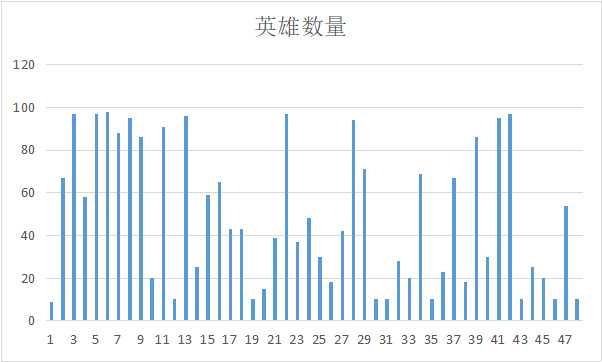
1.经过对主题数据的分析与可视化,可以得到哪些结论?
对于皮肤多的账号更受欢迎
对于价格便宜的账号更喜欢
对段位高的账号更加喜欢
2.对本次程序设计任务完成的情况做一个简单的小结。
通过爬虫的拉取数据,让我可以更加清晰的了解到大数据是怎么进行的,认识到了自己的不足,还需要认真学习
原文:https://www.cnblogs.com/dwsuccessful/p/12058406.html