1. Hive数据倾斜
原因:
key分布不均匀
业务数据本身的特性
SQL语句造成数据倾斜
解决方法
hive设置hive.map.aggr=true和hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定为true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job在根据预处理的数据结果按照 Group By Key 分布到Reduce中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。
SQL语句调整:
选用join key 分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表join的时候,数据量相对变小的效果。
大小表Join: 使用map join让小的维度表(1000条以下的记录条数)先进内存。在Map端完成Reduce。
大表Join大表:把空值的Key变成一个字符串加上一个随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终的结果。
count distinct大量相同特殊值:count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在做后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union.
2. Hive中的排序关键字有哪些
sort by ,order by ,cluster by ,distribute by
sort by :不是全局排序,其在数据进入reducer前完成排序
order by :会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序).只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
cluster by : 当distribute by 和sort by的字段相同时,等同于cluster by.可以看做特殊的distribute + sort
distribute by :按照指定的字段对数据进行划分输出到不同的reduce中
3. 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10
方案1:
在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。
比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。
最后堆中的元素就是TOP10大。
方案2
求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据
再利用上面类似的方法求出TOP10就可以了。
4. Hive中追加导入数据的4种方式是什么?请写出简要语法
从本地导入: load data local inpath ‘/home/1.txt’ (overwrite)into table student;
从Hdfs导入: load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;
查询导入: create table student1 as select * from student;(也可以具体查询某项数据)
查询结果导入:insert (overwrite)into table staff select * from track_log;
5. Hive导出数据有几种方式?如何导出数据
用insert overwrite导出方式
导出到本地:
insert overwrite local directory ‘/home/robot/1/2’ rom format delimited fields terminated by ‘\t’ select * from staff;(递归创建目录)
导出到HDFS
insert overwrite directory ‘/user/hive/1/2’ rom format delimited fields terminated by ‘\t’ select * from staff;
Bash shell覆盖追加导出
例如:$ bin/hive -e “select * from staff;” > /home/z/backup.log
Sqoop把hive数据导出到外部
6. hive 内部表和外部表区别
创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。
删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
7. 分区和分桶的区别
分区
是指按照数据表的某列或某些列分为多个区,区从形式上可以理解为文件夹,比如我们要收集某个大型网站的日志数据,一个网站每天的日志数据存在同一张表上,由于每天会生成大量的日志,导致数据表的内容巨大,在查询时进行全表扫描耗费的资源非常多。
那其实这个情况下,我们可以按照日期对数据表进行分区,不同日期的数据存放在不同的分区,在查询时只要指定分区字段的值就可以直接从该分区查找
分桶
分桶是相对分区进行更细粒度的划分。
分桶将整个数据内容安装某列属性值得hash值进行区分,如要按照name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。
如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件
8. Hive优化
通用设置
hive.optimize.cp=true:列裁剪
hive.optimize.prunner:分区裁剪
hive.limit.optimize.enable=true:优化LIMIT n语句
hive.limit.row.max.size=1000000:
hive.limit.optimize.limit.file=10:最大文件数
本地模式(小任务)
job的输入数据大小必须小于参数:hive.exec.mode.local.auto.inputbytes.max(默认128MB)
job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max(默认4)
job的reduce数必须为0或者1
hive.exec.mode.local.auto.inputbytes.max=134217728
hive.exec.mode.local.auto.tasks.max=4
hive.exec.mode.local.auto=true
hive.mapred.local.mem:本地模式启动的JVM内存大小
并发执行
hive.exec.parallel=true ,默认为false
hive.exec.parallel.thread.number=8
Strict Mode:
hive.mapred.mode=true,严格模式不允许执行以下查询:
分区表上没有指定了分区
没有limit限制的order by语句
笛卡尔积:JOIN时没有ON语句
动态分区
hive.exec.dynamic.partition.mode=strict:该模式下必须指定一个静态分区
hive.exec.max.dynamic.partitions=1000
hive.exec.max.dynamic.partitions.pernode=100:在每一个mapper/reducer节点允许创建的最大分区数
DATANODE:dfs.datanode.max.xceivers=8192:允许DATANODE打开多少个文件
推测执行
mapred.map.tasks.speculative.execution=true
mapred.reduce.tasks.speculative.execution=true
hive.mapred.reduce.tasks.speculative.execution=true;
多个group by合并
hive.multigroupby.singlemar=true:当多个GROUP BY语句有相同的分组列,则会优化为一个MR任务
虚拟列
hive.exec.rowoffset:是否提供虚拟列
分组
两个聚集函数不能有不同的DISTINCT列,以下表达式是错误的:
INSERT OVERWRITE TABLE pv_gender_agg SELECT pv_users.gender, count(DISTINCT pv_users.userid), count(DISTINCT pv_users.ip) FROM pv_users GROUP BY pv_users.gender;
SELECT语句中只能有GROUP BY的列或者聚集函数。
Combiner聚合
hive.map.aggr=true;在map中会做部分聚集操作,效率更高但需要更多的内存。
hive.groupby.mapaggr.checkinterval:在Map端进行聚合操作的条目数目
数据倾斜
hive.groupby.skewindata=true:数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。
第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key
有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
排序
ORDER BY colName ASC/DESC
hive.mapred.mode=strict时需要跟limit子句
hive.mapred.mode=nonstrict时使用单个reduce完成排序
SORT BY colName ASC/DESC :每个reduce内排序
DISTRIBUTE BY(子查询情况下使用 ):控制特定行应该到哪个reducer,并不保证reduce内数据的顺序
CLUSTER BY :当SORT BY 、DISTRIBUTE BY使用相同的列时。
合并小文件
hive.merg.mapfiles=true:合并map输出
hive.merge.mapredfiles=false:合并reduce输出
hive.merge.size.per.task=256*1000*1000:合并文件的大小
hive.mergejob.maponly=true:如果支持CombineHiveInputFormat则生成只有Map的任务执行merge
hive.merge.smallfiles.avgsize=16000000:文件的平均大小小于该值时,会启动一个MR任务执行merge。
自定义map/reduce数目
减少map数目:
set mapred.max.split.size
set mapred.min.split.size
set mapred.min.split.size.per.node
set mapred.min.split.size.per.rack
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
增加map数目:
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
假设有这样一个任务:
select data_desc, count(1), count(distinct id),sum(case when …),sum(case when ...),sum(…) from a group by data_desc
如果表a只有一个文件,大小为120M,但包含几千万的记录,如果用1个map去完成这个任务,肯定是比较耗时的,这种情况下,我们要考虑将这一个文件合理的拆分成多个,这样就可以用多个map任务去完成。
set mapred.reduce.tasks=10;
create table a_1 as select * from a distribute by rand(123);
这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,则会用10个map任务去完成。每个map任务处理大于12M(几百万记录)的数据,效率肯定会好很多。
reduce数目设置:
参数1:hive.exec.reducers.bytes.per.reducer=1G:每个reduce任务处理的数据量
参数2:hive.exec.reducers.max=999(0.95*TaskTracker数):每个任务最大的reduce数目
reducer数=min(参数2,总输入数据量/参数1)
set mapred.reduce.tasks:每个任务默认的reduce数目。典型为0.99*reduce槽数,hive将其设置为-1,自动确定reduce数目。
使用索引:
hive.optimize.index.filter:自动使用索引
hive.optimize.index.groupby:使用聚合索引优化GROUP BY操作
-------------------------------------------------------------------------------------------------------------------------------------------------
1.Hive表关联查询,如何解决数据倾斜的问题
1)倾斜原因:
map输出数据按key Hash的分配到reduce中,由于key分布不均匀、业务数据本身的特、建表时考虑不周、等原因造成的reduce 上的数据量差异过大。
(1)key分布不均匀;
(2)业务数据本身的特性;
(3)建表时考虑不周;
(4)某些SQL语句本身就有数据倾斜;
如何避免:对于key为空产生的数据倾斜,可以对其赋予一个随机值。
2)解决方案
(1)参数调节:
hive.map.aggr = true
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定位true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。
(2)SQL 语句调节:
① 选用join key分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表做join 的时候,数据量相对变小的效果。
② 大小表Join:
使用map join让小的维度表(1000 条以下的记录条数)先进内存(小表在左,大表在右)。在map端完成reduce.
③ 大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null 值关联不上,处理后并不影响最终结果。
④ count distinct大量相同特殊值:
count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
2.谈一下hive的特点,以及hive和RDBMS有什么异同
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换成mapreduce任务进行运行。它的优点就是学习成本低,可以通过类sql语句快速实现简单的mapreduce统计,不必开发专门的mapreduce应用,十分适合数据仓库的统计分析,缺点:不支持实时数据查询。
Hive与关系型数据库的区别:
3.说一下hive中sort by、order by、cluster by、distribute by各代表的意思
order by:对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序),只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by:局部排序,其在数据进入reducer前完成排序。
distribute by:按照指定的字段对数据进行划分输出到不同的reducer中。
cluster by:除具有distribute by功能外还具有sort by的功能。
4.简要描述数据库中的 null,说出null在hive底层如何存储,并解释select a.* from t1 a left outer join t2 b on a.id=b.id where b.id is null; 语句的含义
null与任何值运算的结果都是null,可以使用is null、is not null函数指定其值为null情况下的取值。
null在hive底层默认是用‘\N‘来存储的,可以通过alter table test SET SERDEPROPERTIES(‘serialization.null.format‘ = ‘a‘);来修改。
查询出t1表中与t2表中id相等的所有信息。
5.写出hive中split、coalesce及collect_list函数的用法(可举例)?
split将字符串转化为数组,即:split(‘a,b,c,d‘ , ‘,‘) ==> ["a","b","c","d"]。
coalesce(T v1, T v2, …) 返回参数中的第一个非空值;如果所有值都为 NULL,那么返回NULL。
collect_list列出该字段所有的值,不去重 select collect_list(id) from table。
6.hive有哪些方式保存元数据,各有哪些特点?
Hive支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数。
内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby是内嵌式元存储的默认数据库。
在本地模式下,每个Hive客户端都会打开到数据存储的连接并在该连接上请求SQL查询。mysql
在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信。
7.hive内部表与外部表的区别
创建表时:创建内部表,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
删除表时:删除内部表时,内部表的元数据和数据会被一起删除掉;外部表只删除元数据,不删除数据,外部表相对来所更加安全些,数据组织也更加灵活,方便共享源数据,生产环境选用外部表。
8.hive底层与数据库交互原理
由于hive的元数据可能面临不断地更新、修改和读取操作,所以它显然不适合使用hadoop文件系统来进行存储。目前hive的元数据信息主要存储在RDBMS中,比如存储在mysql、derby中,mysql中居多。hive元数据信息主要包括:存在的表、表的列、权限等。
9.写出将 text.txt 文件放入 hive 中 test 表‘2016-10-10’ 分区的语句,test 的分区字段是 l_date
load data local inpath ‘/your/path/test.txt‘ overwrite into table test partition(1_date=‘2016-10-10‘)
10.hive如何进行权限控制
目前hive支持简单的权限管理,默认情况下是不开启,这样所有的用户都具有相同的权限,同时也是超级管理员,也就对hive中的所有表都有查看和改动的权利,这样是不符合一般数据仓库的安全原则的。Hive可以是基于元数据的权限管理,也可以基于文件存储级别的权限管理。
为了使用Hive的授权机制,有两个参数必须在hive-site.xml中设置:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
<description>enable or disable the hive client authorization</description>
</property>
<property>
<name>hive.security.authorization.createtable.owner.grants</name>
<value>ALL</value>
<description>the privileges automatically granted to the owner whenever a table gets created. An example like "select,drop" will grant select and drop privilege to the owner of the table</description>
</property>
hive支持的权限
11.Hive 中的压缩格式TextFile、SequenceFile、RCfile 、ORCfile各有什么区别?
TextFile:默认格式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
SequenceFile:SequenceFile是Hadoop API提供的一种二进制文件支持,,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。优势是文件和hadoop api中的MapFile是相互兼容的。
RCfile: 存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
ORCfile:存储方式:数据按行分块 每块按照列存储。压缩快 快速列存取。效率比rcfile高,是rcfile的改良版本。
总结:相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势 。
12.Hive join过程中大表小表的放置顺序
在编写带有join操作的代码语句时,应该将条目少的表/子查询放在join操作符的左边。因为在reduce阶段,位于join操作符左边的表的内容会被加载进内存,载入条目较少的表可以有效减少oom(out of memory)即内存溢出。所以对于同一个key来说,对应的value值小的放前,大的放后。------小表放前(小表join大表)
13.hive的两张表关联,使用mapreduce怎么实现?
1)如果其中有一张表为小表,直接使用map端join的方式(map端加载小表)进行聚合。
2)如果两张都是大表,那么采用联合key,联合key的第一个组成部分是join on中的公共字段,第二部分是一个flag,0代表表A,1代表表B,由此让Reduce区分客户信息和订单信息;在Mapper中同时处理两张表的信息,将join on公共字段相同的数据划分到同一个分区中,进而传递到一个Reduce中,然后在Reduce中实现聚合。
14.Hive自定义UDF函数的流程
1)写一个类继承(org.apache.hadoop.hive.ql.)UDF类;
2)覆盖方法evaluate();
3)打JAR包;
4)通过hive命令将JAR添加到Hive的类路径:
hive> add jar /home/ubuntu/ToDate.jar;
5)注册函数:
hive> create temporary function xxx as ‘XXX‘;
6)使用函数;
------------------------------------------------------------------------------------------------------------------------------------------
1.hive 的使用, 内外部表的区别,分区作用, UDF 和 Hive 优化
(1)hive 使用:仓库、工具
(2)hive 内部表:加载数据到 hive 所在的 hdfs 目录,删除时,元数据和数据文件都删除
外部表:不加载数据到 hive 所在的 hdfs 目录,删除时,只删除表结构。
(3)分区作用:防止数据倾斜
(4)UDF 函数:用户自定义的函数 (主要解决格式,计算问题 ),需要继承 UDF 类
java 代码实现
class TestUDFHive extends UDF {
public String evalute(String str){
try{
return "hello"+str
}catch(Exception e){
return str+"error"
}
}
}
(5)sort by和order by之间的区别?
使用order by会引发全局排序;
select * from baidu_click order by click desc;
使用 distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
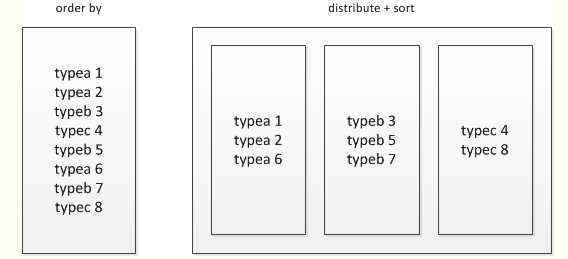
sort by的排序发生在每个reduce里,order by和sort by之间的不同点是前者保证在全局进行排序,而后者仅保证在每个reduce内排序,如果有超过1个reduce,sort by可能有部分结果有序。
注意:它也许是混乱的作为单独列排序对于sort by和cluster by。不同点在于cluster by的分区列和sort by有多重reduce,reduce内的分区数据时一致的。
(6)Hive 优化:看做 mapreduce 处理
排序优化: sort by 效率高于 order by。分区:使用静态分区 (statu_date="20160516",location="beijin") ,每个分区对应 hdfs 上的一个目录,减少 job 和 task 数量:使用表链接操作,解决 groupby 数据倾斜问题:设置hive.groupby.skewindata=true ,那么 hive 会自动负载均衡,小文件合并成大文件:表连接操作,使用 UDF 或 UDAF 函数:
原文:https://www.cnblogs.com/sx66/p/12038856.html