Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
瓜子二手车爬取
2.主题式网络爬虫爬取的内容与数据特征分析
2.1:爬取内容:
城市车辆品牌链接,车辆的标题,车辆具体链接,车源号,车辆价钱,车辆排量。上牌时间
2.2:数据特征分析
将爬取到的内容存放到MySQL中
对车辆价格做一个可视化表格
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.1 实现思路:
先对瓜子二手车的JS进行破解,能够获取网页的源代码
在使用正则表达式来筛选需要爬取的数据
将爬取到的存放到MySQL,在对MySQL里的数据进行分析
3.2 技术难点:
瓜子二手车有反爬虫,我们需要破解它的反爬虫
1 a反爬策略方法的分析 2 ---------------------------------------------------- 3 4 破解反爬 5 1、先把返回数据copy出来,发现,里面数据就在js 6 2、 eval(function(p,a,c,k,e,r){e=function(c){return(c<62?‘‘: 7 e(parseInt(c/62)))+((c=c%62)>35?String.fromCharCode(c+29):c.toString(36))}; 8 if(‘0‘.replace(0,e)==0){while(c--)r[e(c)]=k[c];k=[function(e){return r[e]||e}]; 9 e=function(){return‘([efhj-pru-wzA-Y]|1\\w)‘}; 10 c=1};while(c--)if(k[c])p=p.replace(new RegExp(‘\\b‘+e(c)+‘\\b‘,‘g‘),k[c]);return p} 11 3、这个叫js混淆 12 4、去掉eval,后面的代码,都复制出来。粘贴到浏览器的开发者工具里面去 13 5、粘贴到console标签里 14 6、解析出来的是半混淆的代码,能看到相关的函数了 15 7、粘贴到https://beautifier.io/,格式化 16 8、在Python里如何调用JS ,>pip install pyexecjs 17 9、破解成功了!!!
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
我们先选取在全国范围内的爬取:
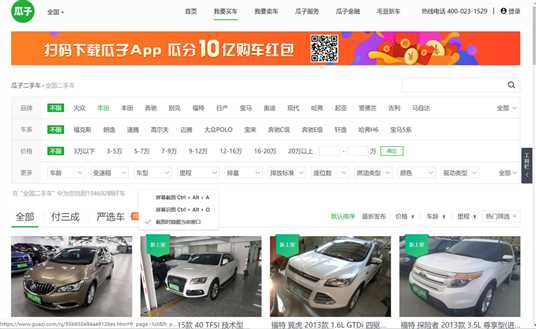
2.Htmls页面解析:
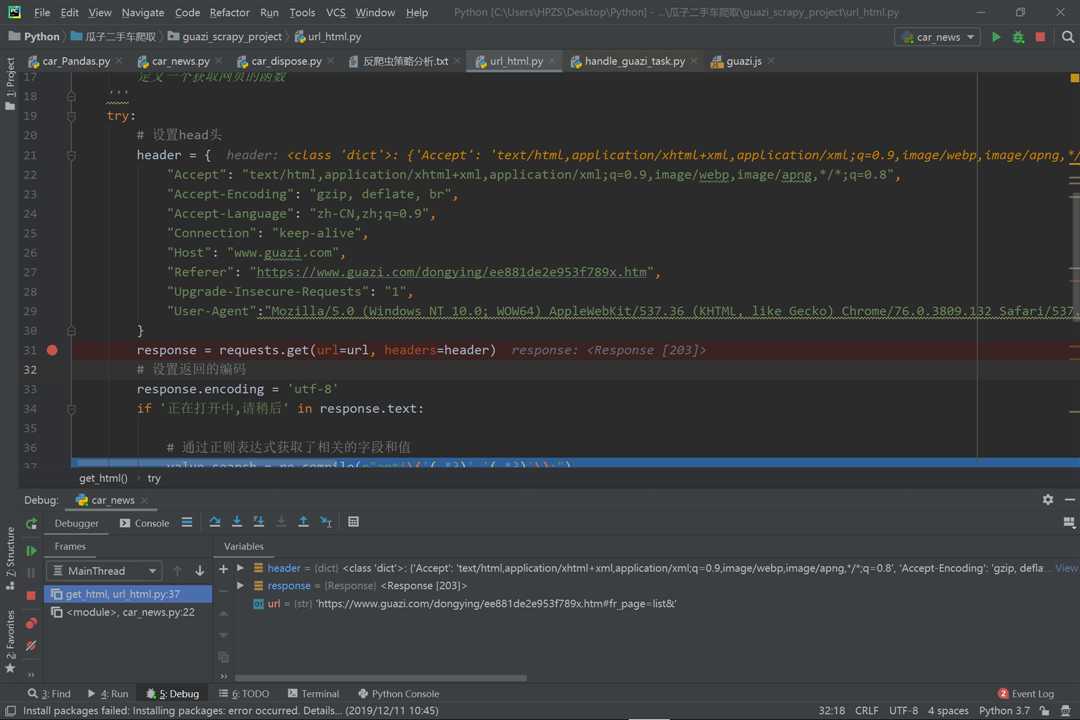
我们第一次发送请求,网页返回的是203,
然后我们再用这个203,再去访问这个JS文件,就可以让他返回一个可以被我们解析的Html界面了
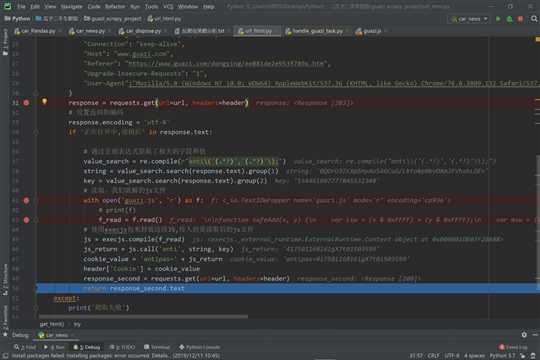
1 """ 2 瓜子二手车利用JS混淆,来反爬, 3 我们就可以利用这段JS代码 4 经过我们分析,他是用来设置cookie,Cookie: antipas=84381S2R54H236370l9820h6672 5 再次发送请求,要带着这个cookie,这样就能返回正常的html页面了 6 7 """ 8 9 function safeAdd(x, y) { 10 var lsw = (x & 0xFFFF) + (y & 0xFFFF); 11 var msw = (x >> 16) + (y >> 16) + (lsw >> 16); 12 return (msw << 16) | (lsw & 0xFFFF) 13 } 14 15 function bitRotateLeft(num, cnt) { 16 return (num << cnt) | (num >>> (32 - cnt)) 17 } 18 19 function cmn(q, a, b, x, s, t) { 20 return safeAdd(bitRotateLeft(safeAdd(safeAdd(a, q), safeAdd(x, t)), s), b) 21 } 22 23 function ff(a, b, c, d, x, s, t) { 24 return cmn((b & c) | ((~b) & d), a, b, x, s, t) 25 } 26 27 function gg(a, b, c, d, x, s, t) { 28 return cmn((b & d) | (c & (~d)), a, b, x, s, t) 29 } 30 31 function hh(a, b, c, d, x, s, t) { 32 return cmn(b ^ c ^ d, a, b, x, s, t) 33 } 34 35 function ii(a, b, c, d, x, s, t) { 36 return cmn(c ^ (b | (~d)), a, b, x, s, t) 37 } 38 39 function binl(x, len) { 40 x[len >> 5] |= 0x80 << (len % 32); 41 x[(((len + 64) >>> 9) << 4) + 14] = len; 42 var i; 43 var olda; 44 var oldb; 45 var oldc; 46 var oldd; 47 var a = 1732584193; 48 var b = -271733879; 49 var c = -1732584194; 50 var d = 271733878; 51 for (i = 0; i < x.length; i += 16) { 52 olda = a; 53 oldb = b; 54 oldc = c; 55 oldd = d; 56 a = ff(a, b, c, d, x[i], 7, -680876936); 57 d = ff(d, a, b, c, x[i + 1], 12, -389564586); 58 c = ff(c, d, a, b, x[i + 2], 17, 606105819); 59 b = ff(b, c, d, a, x[i + 3], 22, -1044525330); 60 a = ff(a, b, c, d, x[i + 4], 7, -176418897); 61 d = ff(d, a, b, c, x[i + 5], 12, 1200080426); 62 c = ff(c, d, a, b, x[i + 6], 17, -1473231341); 63 b = ff(b, c, d, a, x[i + 7], 22, -45705983); 64 a = ff(a, b, c, d, x[i + 8], 7, 1770035416); 65 d = ff(d, a, b, c, x[i + 9], 12, -1958414417); 66 c = ff(c, d, a, b, x[i + 10], 17, -42063); 67 b = ff(b, c, d, a, x[i + 11], 22, -1990404162); 68 a = ff(a, b, c, d, x[i + 12], 7, 1804603682); 69 d = ff(d, a, b, c, x[i + 13], 12, -40341101); 70 c = ff(c, d, a, b, x[i + 14], 17, -1502002290); 71 b = ff(b, c, d, a, x[i + 15], 22, 1236535329); 72 a = gg(a, b, c, d, x[i + 1], 5, -165796510); 73 d = gg(d, a, b, c, x[i + 6], 9, -1069501632); 74 c = gg(c, d, a, b, x[i + 11], 14, 643717713); 75 b = gg(b, c, d, a, x[i], 20, -373897302); 76 a = gg(a, b, c, d, x[i + 5], 5, -701558691); 77 d = gg(d, a, b, c, x[i + 10], 9, 38016083); 78 c = gg(c, d, a, b, x[i + 15], 14, -660478335); 79 b = gg(b, c, d, a, x[i + 4], 20, -405537848); 80 a = gg(a, b, c, d, x[i + 9], 5, 568446438); 81 d = gg(d, a, b, c, x[i + 14], 9, -1019803690); 82 c = gg(c, d, a, b, x[i + 3], 14, -187363961); 83 b = gg(b, c, d, a, x[i + 8], 20, 1163531501); 84 a = gg(a, b, c, d, x[i + 13], 5, -1444681467); 85 d = gg(d, a, b, c, x[i + 2], 9, -51403784); 86 c = gg(c, d, a, b, x[i + 7], 14, 1735328473); 87 b = gg(b, c, d, a, x[i + 12], 20, -1926607734); 88 a = hh(a, b, c, d, x[i + 5], 4, -378558); 89 d = hh(d, a, b, c, x[i + 8], 11, -2022574463); 90 c = hh(c, d, a, b, x[i + 11], 16, 1839030562); 91 b = hh(b, c, d, a, x[i + 14], 23, -35309556); 92 a = hh(a, b, c, d, x[i + 1], 4, -1530992060); 93 d = hh(d, a, b, c, x[i + 4], 11, 1272893353); 94 c = hh(c, d, a, b, x[i + 7], 16, -155497632); 95 b = hh(b, c, d, a, x[i + 10], 23, -1094730640); 96 a = hh(a, b, c, d, x[i + 13], 4, 681279174); 97 d = hh(d, a, b, c, x[i], 11, -358537222); 98 c = hh(c, d, a, b, x[i + 3], 16, -722521979); 99 b = hh(b, c, d, a, x[i + 6], 23, 76029189); 100 a = hh(a, b, c, d, x[i + 9], 4, -640364487); 101 d = hh(d, a, b, c, x[i + 12], 11, -421815835); 102 c = hh(c, d, a, b, x[i + 15], 16, 530742520); 103 b = hh(b, c, d, a, x[i + 2], 23, -995338651); 104 a = ii(a, b, c, d, x[i], 6, -198630844); 105 d = ii(d, a, b, c, x[i + 7], 10, 1126891415); 106 c = ii(c, d, a, b, x[i + 14], 15, -1416354905); 107 b = ii(b, c, d, a, x[i + 5], 21, -57434055); 108 a = ii(a, b, c, d, x[i + 12], 6, 1700485571); 109 d = ii(d, a, b, c, x[i + 3], 10, -1894986606); 110 c = ii(c, d, a, b, x[i + 10], 15, -1051523); 111 b = ii(b, c, d, a, x[i + 1], 21, -2054922799); 112 a = ii(a, b, c, d, x[i + 8], 6, 1873313359); 113 d = ii(d, a, b, c, x[i + 15], 10, -30611744); 114 c = ii(c, d, a, b, x[i + 6], 15, -1560198380); 115 b = ii(b, c, d, a, x[i + 13], 21, 1309151649); 116 a = ii(a, b, c, d, x[i + 4], 6, -145523070); 117 d = ii(d, a, b, c, x[i + 11], 10, -1120210379); 118 c = ii(c, d, a, b, x[i + 2], 15, 718787259); 119 b = ii(b, c, d, a, x[i + 9], 21, -343485551); 120 a = safeAdd(a, olda); 121 b = safeAdd(b, oldb); 122 c = safeAdd(c, oldc); 123 d = safeAdd(d, oldd) 124 } 125 return [a, b, c, d] 126 } 127 128 function binl2rstr(input) { 129 var i; 130 var output = ‘‘; 131 var length32 = input.length * 32; 132 for (i = 0; i < length32; i += 8) { 133 output += String.fromCharCode((input[i >> 5] >>> (i % 32)) & 0xFF) 134 } 135 return output 136 } 137 138 function rstr2binl(input) { 139 var i; 140 var output = []; 141 output[(input.length >> 2) - 1] = undefined; 142 for (i = 0; i < output.length; i += 1) { 143 output[i] = 0 144 } 145 var length8 = input.length * 8; 146 for (i = 0; i < length8; i += 8) { 147 output[i >> 5] |= (input.charCodeAt(i / 8) & 0xFF) << (i % 32) 148 } 149 return output 150 } 151 152 function rstr(s) { 153 return binl2rstr(binl(rstr2binl(s), s.length * 8)) 154 } 155 156 function rstrHMAC(key, data) { 157 var i; 158 var bkey = rstr2binl(key); 159 var ipad = []; 160 var opad = []; 161 var hash; 162 ipad[15] = opad[15] = undefined; 163 if (bkey.length > 16) { 164 bkey = binl(bkey, key.length * 8) 165 } 166 for (i = 0; i < 16; i += 1) { 167 ipad[i] = bkey[i] ^ 0x36363636; 168 opad[i] = bkey[i] ^ 0x5C5C5C5C 169 } 170 hash = binl(ipad.concat(rstr2binl(data)), 512 + data.length * 8); 171 return binl2rstr(binl(opad.concat(hash), 512 + 128)) 172 } 173 174 function rstr2hex(input) { 175 var hexTab = ‘0123456789abcdef‘; 176 var output = ‘‘; 177 var x; 178 var i; 179 for (i = 0; i < input.length; i += 1) { 180 x = input.charCodeAt(i); 181 output += hexTab.charAt((x >>> 4) & 0x0F) + hexTab.charAt(x & 0x0F) 182 } 183 return output 184 } 185 186 function str2rstrUTF8(input) { 187 return unescape(encodeURIComponent(input)) 188 } 189 190 function raw(s) { 191 return rstr(str2rstrUTF8(s)) 192 } 193 194 function hex(s) { 195 return rstr2hex(raw(s)) 196 } 197 198 function uid() { 199 var text = ""; 200 var possible = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; 201 var len = Math.floor(Math.random() * 2); 202 for (var i = 0; i < len; i++) { 203 text += possible.charAt(Math.floor(Math.random() * possible.length)) 204 } 205 return text 206 } 207 208 function charRun(s) { 209 s = s.replace(/[a-zA-Z]/g, ‘#‘); 210 var arr = s.split(‘‘); 211 for (var i = 0; i < arr.length; i++) { 212 if (arr[i] == ‘#‘) { 213 arr[i] = uid() 214 } 215 } 216 return arr.join(‘‘) 217 } 218 219 function anti(string, key) { 220 var estring = hex(string); 221 return charRun(estring) 222 }
这是复制他的标题信息
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1 """
2 我们就用这段代码来解析刚刚破解的JS代码,
3 这段代码可以每次访问瓜子二手车网页时,
4 都可以带入一个新的cookie。
5 返回一个可以被我们所解析的Html界面
6
7 """
8
9 import requests
10 # 通过execjs这个包,来解析js
11 import execjs
12 import re
13 from guazi_scrapy_project.mysql_srevice import GuaZiSrevice
14
15 def get_html(url):
16 ‘‘‘
17 定义一个获取网页的函数
18 ‘‘‘
19 try:
20 # 设置head头
21 header = {
22 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
23 "Accept-Encoding": "gzip, deflate, br",
24 "Accept-Language": "zh-CN,zh;q=0.9",
25 "Connection": "keep-alive",
26 "Host": "www.guazi.com",
27 "Upgrade-Insecure-Requests": "1",
28 "User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3610.2 Safari/537.36",
29 }
30 response = requests.get(url=url, headers=header)
31 # 设置返回的编码
32 response.encoding = ‘utf-8‘
33 # 通过正则表达式获取了相关的字段和值
34 value_search = re.compile(r"anti\(‘(.*?)‘,‘(.*?)‘\);")
35 string = value_search.search(response.text).group(1)
36 key = value_search.search(response.text).group(2)
37 # 读取,我们破解的js文件
38 with open(‘guazi.js‘, ‘r‘) as f:
39 f_read = f.read()
40 # 使用execjs包来封装这段JS,传入的是读取后的js文件
41 js = execjs.compile(f_read)
42 js_return = js.call(‘anti‘, string, key)
43 cookie_value = ‘antipas=‘ + js_return
44 header[‘Cookie‘] = cookie_value
45 response_second = requests.get(url=url, headers=header)
46 return response_second.text
47 except:
48 print(‘爬取失败‘)
1 """
2 创建MySQL的连接池
3
4 """
5
6 import mysql.connector.pooling
7
8 __config = {
9 "host": "localhost",
10 "port": 3306,
11 "user": "root",
12 "password": "123456",
13 "database": "guazi"
14 }
15 try:
16 pool = mysql.connector.pooling.MySQLConnectionPool(
17 **__config,
18 pool_size=10
19 )
20 except Exception as e:
21 print(e)
1 """
2 这是用来连接数据库的代码,
3 这段代码主要用来和MySQL进行交互
4
5 """
6 # 导入连接池
7 from guazi_scrapy_project.mysql_db import pool
8
9
10 class GuaZiDao():
11
12 # 添加城市、品牌列表
13 def city_brand_list(self, task_url, city_name, brand_name):
14 try:
15 con = pool.get_connection()
16 con.start_transaction()
17 cursor = con.cursor()
18 sql = "INSERT t_gua (task_url,city_name,brand_name) " 19 "VALUES (%s,%s,%s)"
20 cursor.execute(sql, (task_url, city_name, brand_name))
21 con.commit()
22 except Exception as e:
23 print(e)
24 finally:
25 if "con" in dir():
26 con.close()
27
28 # 获取汽车城市,品牌信息
29 def car_dispose(self, city_name):
30 try:
31 con = pool.get_connection()
32 cursor = con.cursor()
33 sql = "SELECT task_url " 34 "FROM t_gua " 35 "WHERE city_name=%s"
36 cursor.execute(sql, [city_name])
37 result = cursor.fetchall()
38 return result
39 except Exception as e:
40 print(e)
41 finally:
42 if "con" in dir():
43 con.close()
44
45 # 获取汽车具体信息的网址
46 def car_dispose_html(self):
47 try:
48 con = pool.get_connection()
49 cursor = con.cursor()
50 sql = "SELECT DISTINCT car_dispose_html FROM t_car_dispose"
51 cursor.execute(sql)
52 result = cursor.fetchall()
53 return result
54 except Exception as e:
55 print(e)
56 finally:
57 if "con" in dir():
58 con.close()
59
60 # 添加车辆页面,车辆标题
61 def car_html_model(self, car_dispose_html, car_model):
62 try:
63 con = pool.get_connection()
64 con.start_transaction()
65 cursor = con.cursor()
66 sql = "INSERT t_car_dispose (car_dispose_html,car_model) " 67 "VALUES (%s,%s)"
68 cursor.execute(sql, (car_dispose_html, car_model))
69 con.commit()
70 except Exception as e:
71 print(e)
72 finally:
73 if "con" in dir():
74 con.close()
75
76 # 添加车辆的具体信息
77 def car_news(self, car_id, car_price, car_displacement, cards_time):
78 try:
79 con = pool.get_connection()
80 con.start_transaction()
81 cursor = con.cursor()
82 sql = "INSERT t_car_news (car_id, car_price, car_displacement, cards_time) " 83 "VALUES (%s,%s,%s,%s)"
84 cursor.execute(sql, (car_id, car_price, car_displacement, cards_time))
85 con.commit()
86 except Exception as e:
87 print(e)
88 finally:
89 if "con" in dir():
90 con.close()
1 """
2 这是用来连接Python的代码,
3 它将刚刚写的连接mysql的代码一起使用
4
5 """
6
7 from guazi_scrapy_project.handle_MySQL import GuaZiDao
8
9
10 class GuaZiSrevice():
11
12 __guazi_dao = GuaZiDao()
13
14 # 获取城市、品牌列表
15 def city_brand_list(self, task_url, city_name, brand_name):
16 self.__guazi_dao.city_brand_list(task_url, city_name, brand_name)
17
18 # 获取汽车信息
19 def car_dispose(self, city_name):
20 car = self.__guazi_dao.car_dispose(city_name)
21 return car
22
23 # 获取汽车具体信息的网址
24 def car_dispose_html(self):
25 car_dispose_html = self.__guazi_dao.car_dispose_html()
26 return car_dispose_html
27
28 # 添加车辆页面,车辆标题
29 def car_html_model(self, car_dispose_html, car_model):
30 self.__guazi_dao.car_html_model(car_dispose_html, car_model)
31
32 # 添加车辆的具体信息
33 def car_news(self, car_id, car_price, car_displacement, cards_time):
34 self.__guazi_dao.car_news(car_id, car_price, car_displacement, cards_time)
35
36
37 if __name__ == ‘__main__‘:
38 opt = GuaZiSrevice()
39 i = opt.car_dispose_html()
40 print(i)
1 """
2 这个代码块的作用是将瓜子二手车的主页面传给解析代码给解析,
3 之后用解析后的Html代码,来通过正则表达式来获取城市和车辆品牌的信息
4 最后通过导入刚刚写的连接mysql的代码,将爬取到的数据导入到mysql中
5
6 """
7 # 将刚刚获取的Html导入
8 from guazi_scrapy_project.url_html import *
9 from guazi_scrapy_project.mysql_srevice import GuaZiSrevice
10
11 __guazi_srevice = GuaZiSrevice()
12
13 # 将瓜子二手车网页带入给url_html这个代码去解析,返回一个可以被我们爬取的Html
14 url = ‘https://www.guazi.com/www/buy/‘
15 response_second = get_html(url)
16 # 通过正则表达式,来提取出城市和车辆品牌的信息
17 city_search = re.compile(r‘href="\/(.*?)\/buy"\stitle=".*?">(.*?)</a>‘)
18 brand_search = re.compile(r‘href="\/www\/(.*?)\/c-1/#bread"\s+>(.*?)</a>‘)
19 city_list = city_search.findall(response_second)
20 brand_list = brand_search.findall(response_second)
21 # print(brand_list)
22 for city in city_list:
23 # 在全国范围里搜索
24 if city[1] == ‘全国‘:
25 for brand in brand_list:
26 info = {}
27 info[‘task_url‘] = ‘https://www.guazi.com/‘+city[0]+‘/‘+brand[0]+‘/‘+‘o1i7‘
28 info[‘city_name‘] = city[1]
29 info[‘brand_name‘] = brand[1]
30 print(info)
31 task_url = ‘https://www.guazi.com/‘+city[0]+‘/‘+brand[0]+‘/‘+‘o1i7‘
32 city_name = city[1]
33 brand_name = brand[1]
34 __guazi_srevice.city_brand_list(task_url, city_name, brand_name)
1 """
2 我们先把存入数据库的网址提取出来,
3 我们要全国范围还是要某个地区的二手车都可以,
4 我们在连接数据库的那段代码中来提取网址
5 提取的网址为需要提取的地区,品牌
6 在把车辆的标题和这辆车的网址提取出来
7 再把它存入数据库
8
9 """
10 import re
11 from guazi_scrapy_project.url_html import *
12 from guazi_scrapy_project.mysql_srevice import GuaZiSrevice
13
14 __guazi_srevice = GuaZiSrevice()
15
16 city_name = "全国"
17 result = __guazi_srevice.car_dispose(city_name)
18 # print(result)
19 for i in range(len(result)):
20 car_url = result[i][0]
21 car_html = get_html(car_url)
22 # print(car_html)
23 # href="/zz/4ffb6e18a9650969x.htm#fr_page=list&fr_pos=city&fr_no=1"
24 html1 = re.compile(r‘\/.*?\/.*?\.htm#fr_page=list&.*?‘)
25 html_list = html1.findall(car_html)
26 # print(html_list)
27 #<a title="奥迪A4L 2019款 40 TFSI 时尚型 国VI"
28 brand_search = re.compile(r‘<a\stitle="(.*?)"‘)
29 car_model_list = brand_search.findall(car_html)
30 # print(car_model_list)
31 for i in range(len(car_model_list)):
32 car_dispose_html = ‘https://www.guazi.com‘+html_list[i]
33 # print(car_dispose_html)
34 car_model = car_model_list[i]
35 # print(car_model)
36 __guazi_srevice.car_html_model(car_dispose_html, car_model)
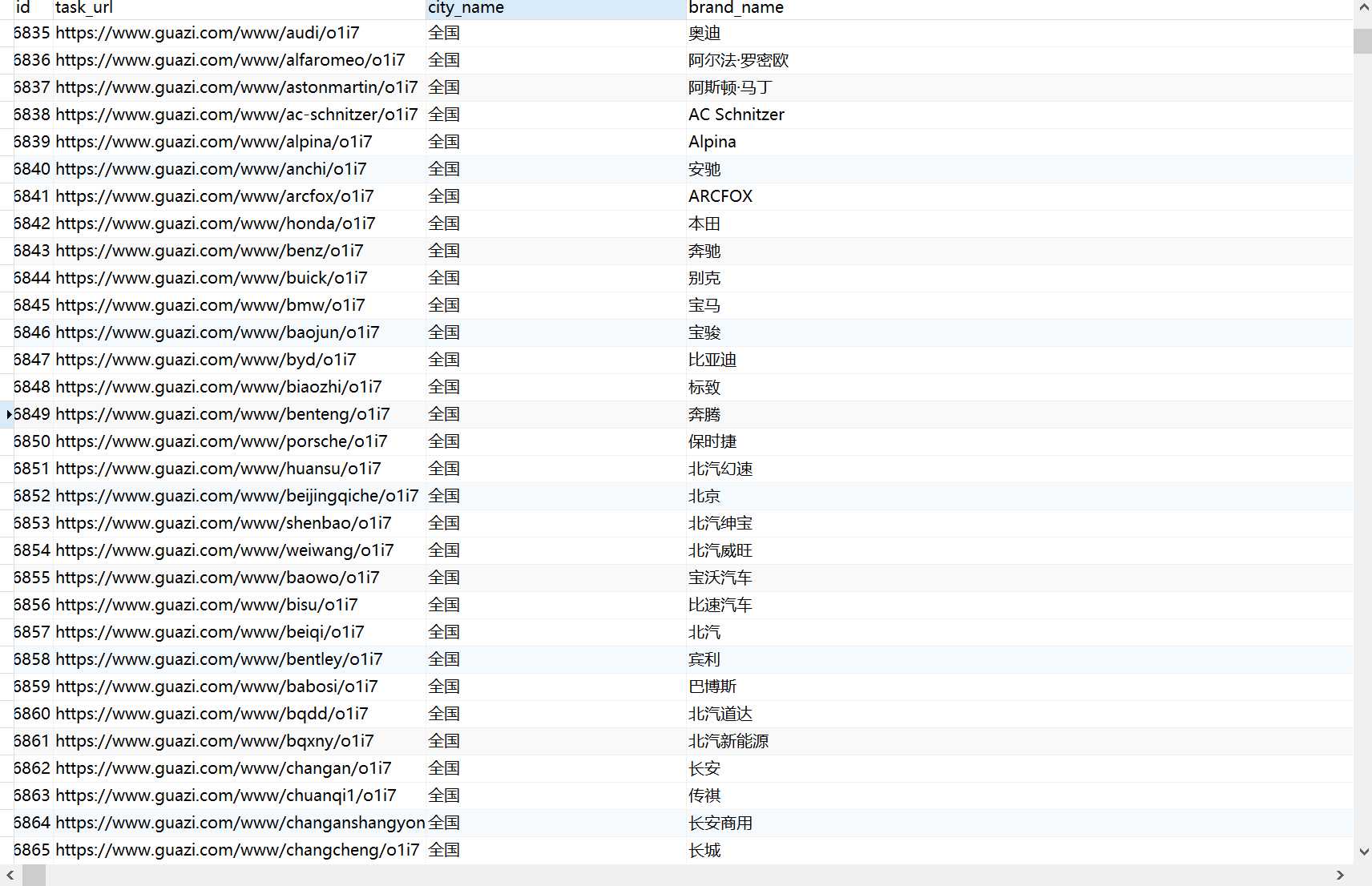
图为mysql的截图,这是在去全国范围里提取出奥迪的数据,数据包括标题和网址
1 """
2 我们在利用for循环来提取出网址,
3 每个网址都有自己的ID,
4 然后我们就用这个ID号来连接表,
5 然后另一张表存放的就是车辆车的具体信息,
6 我们提取了车辆的车源号,价钱,排量,上牌时间
7 然后保存到mysql数据库中
8 """
9
10 import re
11 from guazi_scrapy_project.url_html import *
12 from guazi_scrapy_project.mysql_srevice import GuaZiSrevice
13
14
15 __guazi_srevice = GuaZiSrevice()
16
17 car_dispose_html_list = __guazi_srevice.car_dispose_html()
18
19 for i in range(len(car_dispose_html_list)):
20 car_dispose_url = car_dispose_html_list[i][0]
21 # print(car_dispose_url)
22 car_dispose_html = get_html(car_dispose_url)
23 # print(car_dispose_html)
24
25 car_id_search = re.compile(r‘车源号:(.*?)\s+‘)
26 car_id_list = car_id_search.findall(car_dispose_html)
27 # print(car_id_list)
28 # <span class="pricestype">¥11.87 <span class="f14">万
29 car_price_search = re.compile(r‘<span\sclass="pricestype">¥(.*?)\s+<span\sclass="f14">万‘)
30 car_price_list = car_price_search.findall(car_dispose_html)
31 # print(car_price_list)
32 # <li class="three"><span>2.0</span>排量</li>
33 car_displacement_search = re.compile(r‘<li\sclass="three"><span>.*?</span>排量</li>‘)
34 car_displacement_list = car_displacement_search.findall(car_dispose_html)
35 # print(car_displacement_list)
36 # <li class="one"><span>2011-06</span>上牌时间</li>
37 cards_time_search = re.compile(r‘<li\sclass="one"><span>.*?</span>上牌时间</li>‘)
38 cards_time_list = cards_time_search.findall(car_dispose_html)
39 # print(cards_time_list)
40 # info = {}
41 # info["car_id"] = car_id_list[0]
42 # info["car_price"] = car_price_list[0][25:31] + "万"
43 # info["car_displacement"] = car_displacement_list[0][24:27]
44 # info["cards_time"] = cards_time_list[0][22:29]
45 # print(info)
46 for car_id_index in car_id_list:
47 car_id = car_id_index
48 # print(car_id)
49 car_price = car_price_list[0]
50 car_displacement = car_displacement_list[0][24:27]
51 cards_time = cards_time_list[0][22:29]
52 # print(cards_time)
53 __guazi_srevice.car_news(car_id, car_price, car_displacement, cards_time)
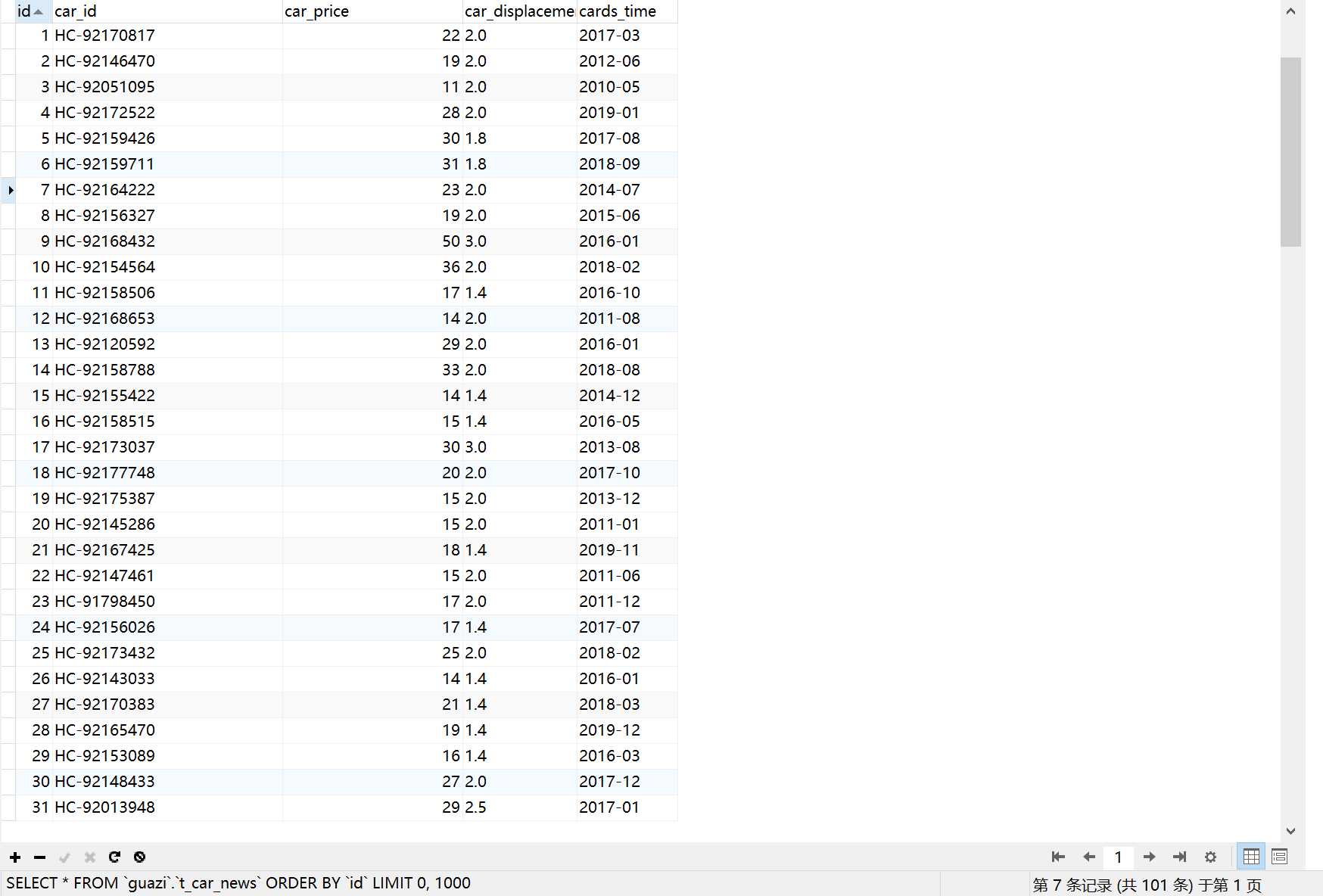
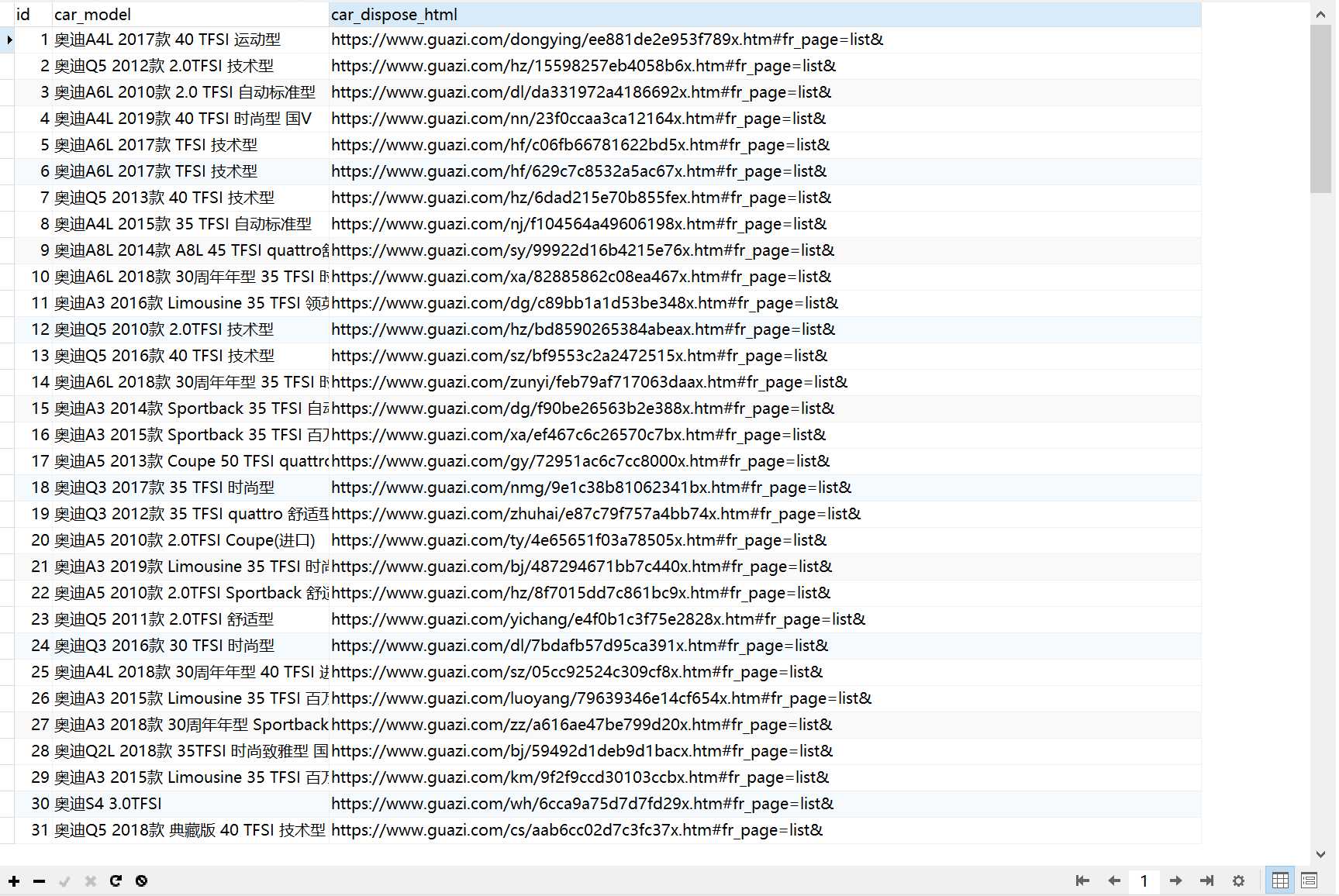
上面的表格是车辆的车源号,价钱,排量,上牌时间
2.对数据进行清洗和处理
1 """ 2 这段代码我们把mysql中保存的车辆价格提取出来再绘制成图像 3 """ 4 import matplotlib.pyplot as plt 5 import pandas as pd 6 import pymysql 7 8 conn = pymysql.connect( 9 host="localhost", 10 port=3306, 11 user="root", 12 password="123456", 13 database="guazi", 14 charset="utf8") 15 16 data = pd.read_sql("SELECT car_price,id FROM t_car_news", con=conn) 17 18 y = list(data.car_price) 19 x = list(data.id) 20 21 plt.plot(x, y, "g-") 22 23 # 设置x坐标轴的范围 24 plt.xlim(1, 100) 25 # 设置y坐标轴的范围 26 plt.ylim(0, 150) 27 28 # 设置X轴文字的标题 29 plt.xlabel("ID") 30 # 设置Y轴文字的标题 31 plt.ylabel("price(万)") 32 33 # 设置图表的标题 34 plt.title("CAR PRICE") 35 36 plt.show() 37 # print(type(x)) 38 # 关闭数据库连接 39 conn.close()
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
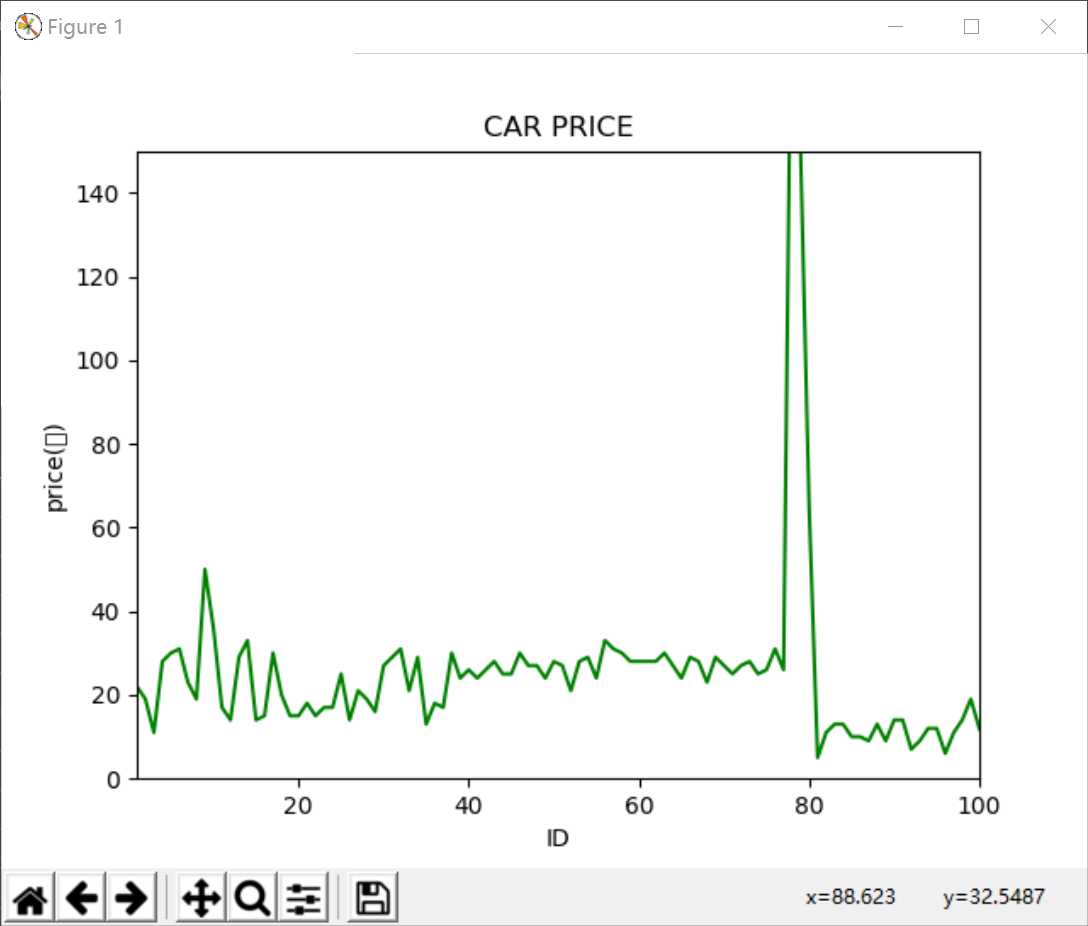
车辆价格表:
5.数据持久化
瓜子二手车主页面的url、城市信息、品牌信息
在全国范围里的奥迪车辆信息、这款车辆的url
上表的url对应的车辆ID、价格、排量、上牌时间,
此表ID与上表的ID对应
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1:这次数据可视化我们选取的是在全国范围里提取奥迪车的价格,
通过图我们可以看出大部分二手奥迪车都在20万上下区间,
2.对本次程序设计任务完成的情况做一个简单的小结。
在这次爬虫的过程中,最大的难点在于破解瓜子二手车的反爬,
只要破解了瓜子二手车的主页面,我们就可以使用mysql将其数据存入,在通过取出mysql的数据进行下一步爬取,
最后通过表连接的方式,来将整个瓜子二手车的数据连接起来
原文:https://www.cnblogs.com/HPZS/p/12036789.html