找到 系统中瓶颈的命令
1. 客户端请求的生命周期:
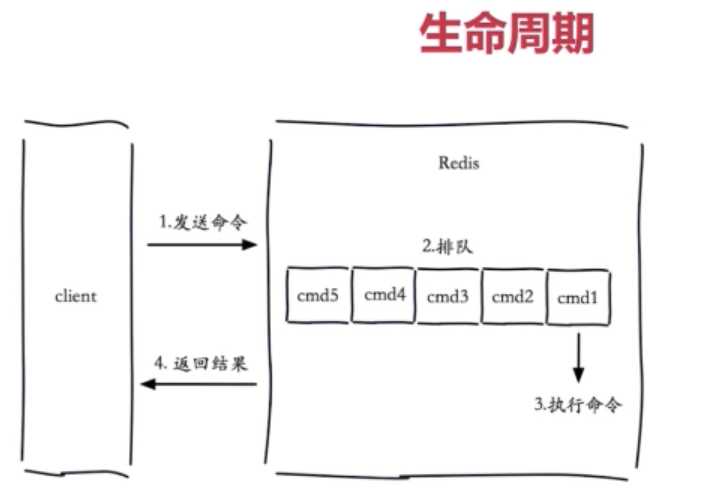
①. 慢查询通常发生在第三阶段。
②. 客户端超时不一定是慢查询,但慢查询是客户端超时的一个可能因素。
2. 相关配置
慢查询命令会存放在一个先进先出的队列
查询队列的长度:
config get slowlog-max-len
默认值是 128,我们通常建议设置为 1000
config set slowlog-max-len=1000
查询慢查询的定义时长:
config get slowlog-log-slower-than
默认值是 10000 微秒= 10 毫秒,我们建议设置为 1 毫秒
config set slowlog-log-slower-than=1000
3. 相关命令
slowlog get [n] # 查询慢查询队列的 n 条
slowlog len # 获取慢查询队列长度
slowlog reset # 清空慢查询队列
流水线是一个类似于 mget / mset 的一个批量操作
区别在于 m 操作是 redis 原生的命令,他在执行队列中作为一个整体在排队。
而流水线是 Java 客户端的命令,在排队时会跟其他命令杂乱在一起排队,非原子性的。但返回时会一起返回。
1. Jedis 客户端直连:
Jedis jedis = new Jedis("127.0.0.1", 6379); for (int i = 0; i < 100; i++) { Pipeline pipeline = jedis.pipelined(); for (int j = i * 100; j < (i + 1) * 100; j++) { pipeline.hset("hashkey:" + j, "field" + j, "value" + j); }
// 嗯嗯?逗号是什么鬼 pipeline.syncAndReturnAll(); }
2. SpringBoot 提供的 RedisTemplate 客户端:
// 1 重写入参 RedisCallback 类的 doInRedis 方法 List<Object> list = redisTemplate.executePipelined((RedisConnection connection) -> { // 2 打开连接 connection.openPipeline(); // 3 要一次性执行的命令 // 3.1 一个 set 操作 connection.set("key1".getBytes(), "value1".getBytes()); // 3.2 一个 mSet 操作 Map<byte[], byte[]> tuple = new HashMap(); tuple.put("m_key1".getBytes(), "m_value1".getBytes()); tuple.put("m_key2".getBytes(), "m_value2".getBytes()); tuple.put("m_key3".getBytes(), "m_value3".getBytes()); connection.mSet(tuple); // 3.3 一个 get 操作 connection.get("m_key2".getBytes()); // 4 返回 null 即可 return null; }, RedisSerializer.string()); // 5 遍历结果 for (Object obj : list) { System.out.println(String.valueOf(obj)); }
执行结果:

减少内存的方案
极端的减少内存的方案 / 数据结构
存储经纬度,计算两地距离,范围计算等
原文:https://www.cnblogs.com/libra0920/p/12027962.html