1.Attention
最先出自于Bengio团队一篇论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ,论文在2015年发表在ICLR。
encoder-decoder模型通常的做法是将一个输入的句子编码成一个固定大小的state,然后将这样的一个state输入到decoder中的每一个时刻,这种做法对处理长句子会很不利,尤其是随着句子长度的增加,效果急速下滑。
论文动机:是针对encoder-decoder长句子翻译效果不好的问题。
解决原理:仿造人脑结构,对一张图片或是一个句子,能够重点关注到不同部分。
论文解决思路:在生成当前词的时候,只要把上一个state与所有的input word作为融合,而后做一个权重计算。通过这种方式生成的词就会有针对性,在句子长度较长时效果尤其明显。
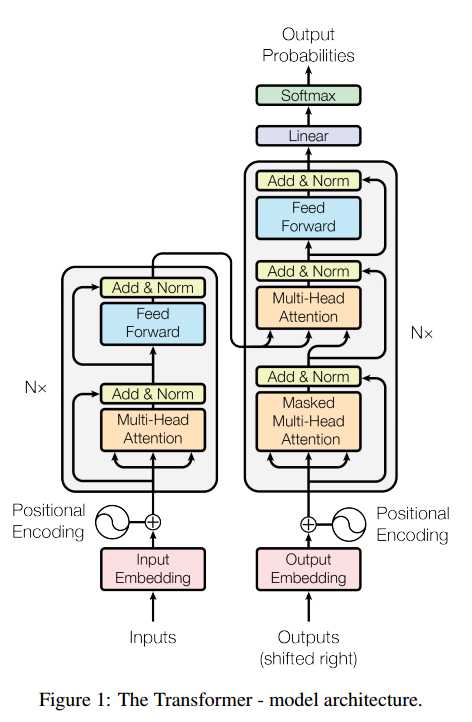
整体框架如下图:

2.Self-attention
出自于Google团队的论文:Attention Is All You Need ,2017年发表在NIPS。
论文动机:RNN本身的结构,阻碍了并行化;同时RNN对长距离依赖问题,效果会很差。
解决思路:通过不同词向量之间矩阵相乘,得到一个词与词之间的相似度,进而无距离限制。
整体结构:
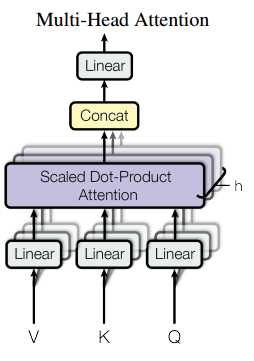
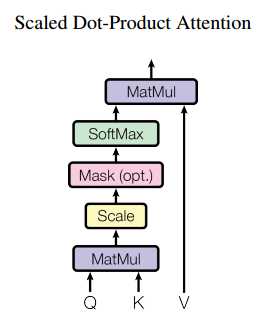
multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如下图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。

原文:https://www.cnblogs.com/AntonioSu/p/12019534.html