************************************************************************
如淘宝等网站都有一个爬虫约定
https://www.taobao.com/robots.txt
robots协议:根域名/robots.txt 弱约定,道德约定
************************************************************************
.Net爬虫是可以获取网站中相关的一些信息在通过网页的定位并获取既可以获取相关内容
1,在书写爬虫的时候我们要获取相关的插件来辅助我们对页面的快速定位和获取内容等等,这个插件就是 HtmlAgilityPack
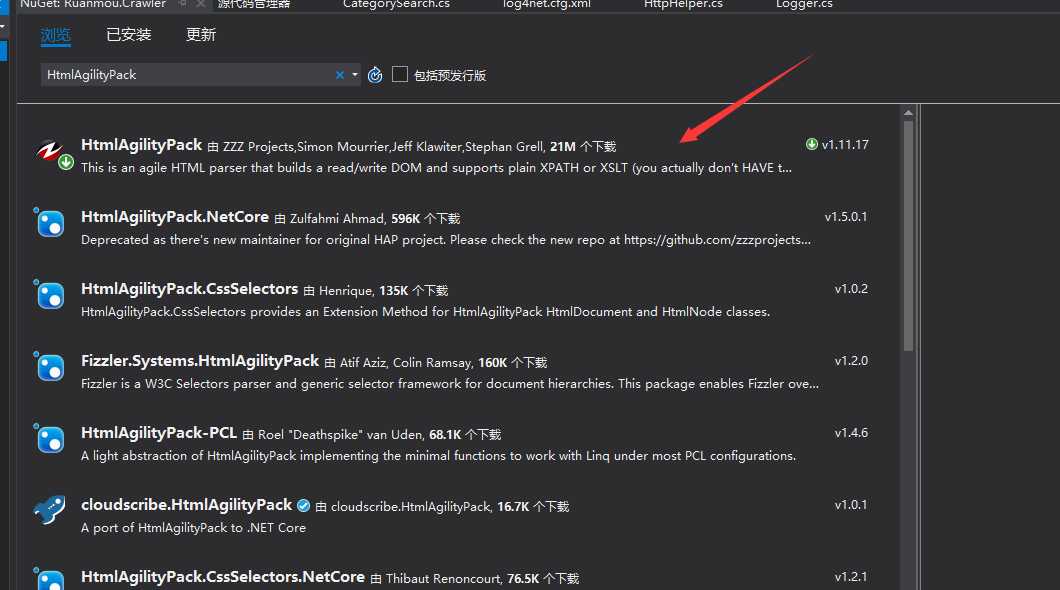
2 HtmlAgilityPack 控件可以使文件信息通过控件Xpath来获取控件的位置
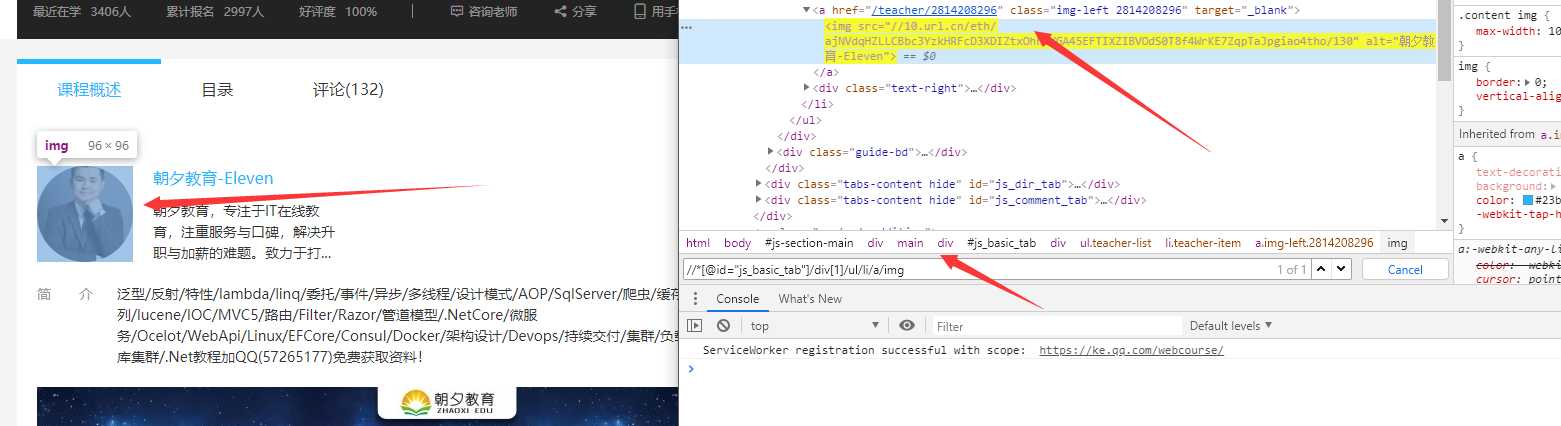
使用Xpath我们可以轻易的定位到到相关控件位置
1,首先我们要通过Url来获取我们需要信息的网站路劲 如:www.jd.com, https://www.dytt8.net/index0.html等等
痛过Url地址我们来获取网站的源码信息
1 public class HttpHelper 2 { 3 private static Logger logger = new Logger(typeof(HttpHelper)); 4 5 /// <summary> 6 /// 根据url下载内容 之前是GB2312 7 /// </summary> 8 /// <param name="url"></param> 9 /// <returns></returns> 10 public static string DownloadUrl(string url) 11 { 12 return DownloadHtml(url, Encoding.UTF8); 13 } 14 15 //HttpClient--WebApi 16 17 /// <summary> 18 /// 下载html 19 20 21 /// </summary> 22 /// <param name="url"></param> 23 /// <returns></returns> 24 public static string DownloadHtml(string url, Encoding enc) 25 { 26 string html = string.Empty; 27 try 28 { 29 //https可以下载-- 30 31 //ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback((object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors) => 32 //{ 33 // return true; //总是接受 34 //}); 35 //ServicePointManager.SecurityProtocol = SecurityProtocolType.Ssl3 | SecurityProtocolType.Tls12 | SecurityProtocolType.Tls11 | SecurityProtocolType.Tls; 36 37 HttpWebRequest request = HttpWebRequest.Create(url) as HttpWebRequest;//模拟请求 38 request.Timeout = 30 * 1000;//设置30s的超时 39 request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36"; 40 //request.UserAgent = "User - Agent:Mozilla / 5.0(iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/ 537.51.2(KHTML, like Gecko) Version / 7.0 Mobile / 11D257 Safari / 9537.53"; 41 42 request.ContentType = "text/html; charset=utf-8";// "text/html;charset=gbk";// 43 //request.Host = "search.yhd.com"; 44 45 //request.Headers.Add("Cookie", @"newUserFlag=1; guid=YFT7C9E6TMFU93FKFVEN7TEA5HTCF5DQ26HZ; gray=959782; cid=av9kKvNkAPJ10JGqM_rB_vDhKxKM62PfyjkB4kdFgFY5y5VO; abtest=31; _ga=GA1.2.334889819.1425524072; grouponAreaId=37; provinceId=20; search_showFreeShipping=1; rURL=http%3A%2F%2Fsearch.yhd.com%2Fc0-0%2Fkiphone%2F20%2F%3Ftp%3D1.1.12.0.73.Ko3mjRR-11-FH7eo; aut=5GTM45VFJZ3RCTU21MHT4YCG1QTYXERWBBUFS4; ac=57265177%40qq.com; msessionid=H5ACCUBNPHMJY3HCK4DRF5VD5VA9MYQW; gc=84358431%2C102362736%2C20001585%2C73387122; tma=40580330.95741028.1425524063040.1430288358914.1430790348439.9; tmd=23.40580330.95741028.1425524063040.; search_browse_history=998435%2C1092925%2C32116683%2C1013204%2C6486125%2C38022757%2C36224528%2C24281304%2C22691497%2C26029325; detail_yhdareas=""; cart_cookie_uuid=b64b04b6-fca7-423b-b2d1-ff091d17e5e5; gla=20.237_0_0; JSESSIONID=14F1F4D714C4EE1DD9E11D11DDCD8EBA; wide_screen=1; linkPosition=search"); 46 47 //request.Headers.Add("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"); 48 //request.Headers.Add("Accept-Encoding", "gzip, deflate, sdch"); 49 //request.Headers.Add("Referer", "http://list.yhd.com/c0-0/b/a-s1-v0-p1-price-d0-f0-m1-rt0-pid-mid0-kiphone/"); 50 51 //Encoding enc = Encoding.GetEncoding("GB2312"); // 如果是乱码就改成 utf-8 / GB2312 52 53 //如何自动读取cookie 54 request.CookieContainer = new CookieContainer();//1 给请求准备个container 55 using (HttpWebResponse response = request.GetResponse() as HttpWebResponse)//发起请求 56 { 57 if (response.StatusCode != HttpStatusCode.OK) 58 { 59 logger.Warn(string.Format("抓取{0}地址返回失败,response.StatusCode为{1}", url, response.StatusCode)); 60 } 61 else 62 { 63 try 64 { 65 //string sessionValue = response.Cookies["ASP.NET_SessionId"].Value;//2 读取cookie 66 StreamReader sr = new StreamReader(response.GetResponseStream(), enc); 67 html = sr.ReadToEnd();//读取数据 68 sr.Close(); 69 } 70 catch (Exception ex) 71 { 72 logger.Error(string.Format($"DownloadHtml抓取{url}失败"), ex); 73 html = null; 74 } 75 } 76 } 77 } 78 catch (System.Net.WebException ex) 79 { 80 if (ex.Message.Equals("远程服务器返回错误: (306)。")) 81 { 82 logger.Error("远程服务器返回错误: (306)。", ex); 83 html = null; 84 } 85 } 86 catch (Exception ex) 87 { 88 logger.Error(string.Format("DownloadHtml抓取{0}出现异常", url), ex); 89 html = null; 90 } 91 return html; 92 } 93 }
通过来url返回一个源码的字符串
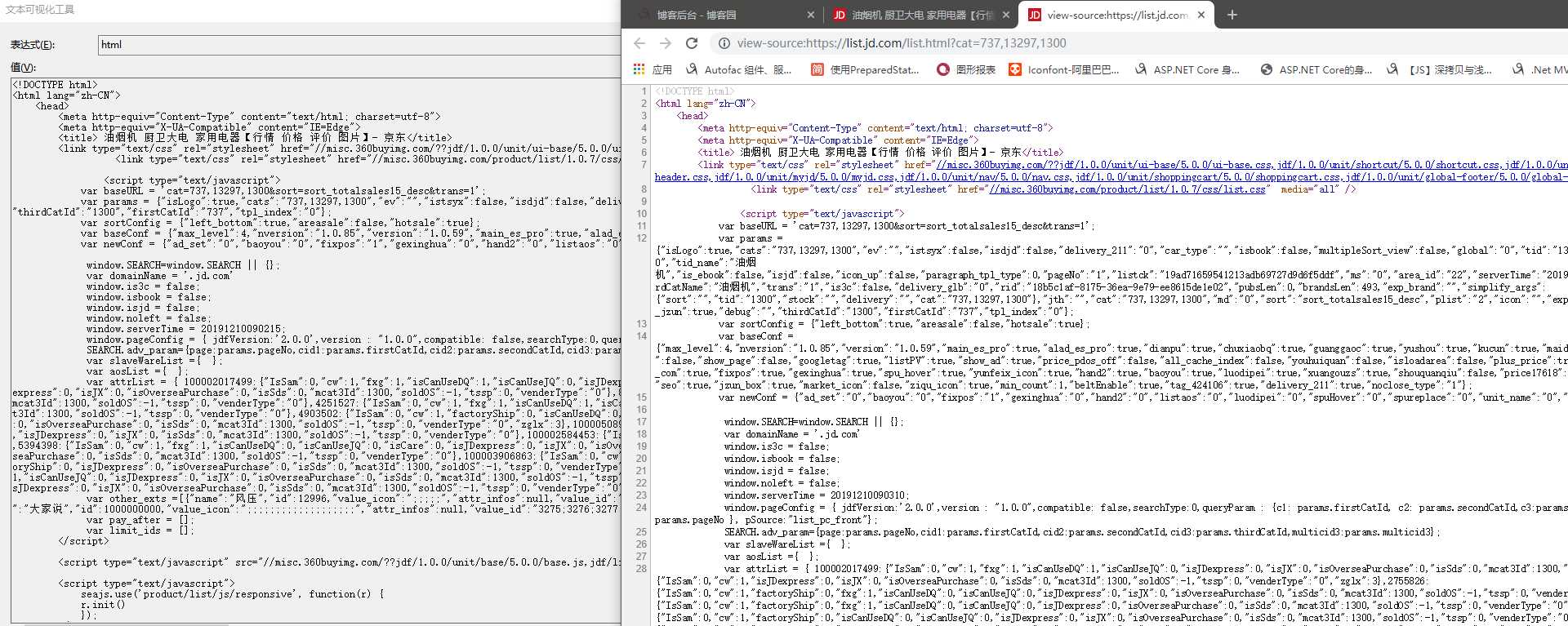
来获取页面的html源码信息
获取源码信息之后我们就可以使用HTMLDocument对象去加载HTML并使用Xpath去查找响应的位置信息
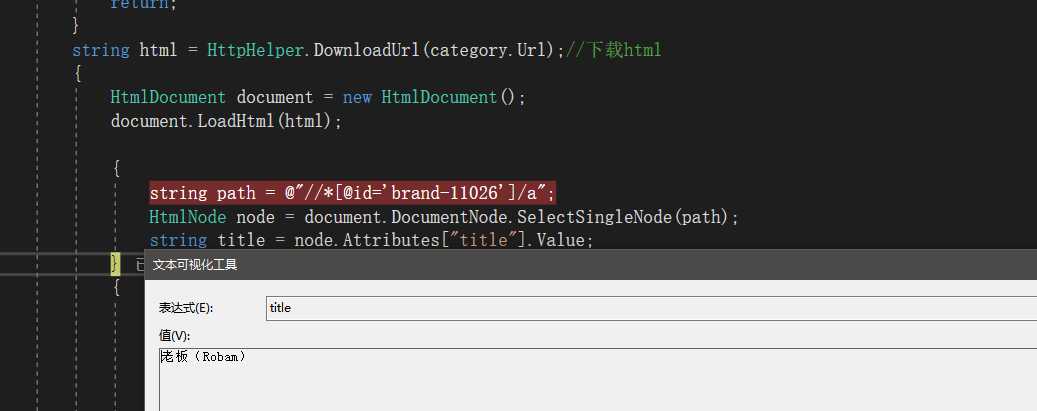
既可以获取文件中的值通过此方法不断的去获取和遍历,就可以获取整个页面的信息,
第二页和第三也的我们在开发时发现
只有page后的数字不一样而已,我们也可以因此获取url地址在page后面是一些参数的设置项我们尝试删除配置项再次输入链接地址
我们一样的可以访问,现在一个网站只要是能设计到的都可以通过此方法获取到
原文:https://www.cnblogs.com/YZM97/p/12014702.html