ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,
是一种流行的企业级搜索引擎。
ElasticSearch 下载:https://www.elastic.co/cn/downloads/elasticsearch
kibana 下载:https://www.elastic.co/cn/downloads/kibana
windows安装很简单,解压启动就行了。一些配置可百度查询用途,刚开始学习,默认不需要修改什么。 安装后 先启动Elasticsearch,再启动kibana。这里只是简单介绍常用的语法。
ElasticSearch 简单的来说,你可以看成它是一个数据库。
1)检索相关数据;
2)返回统计结果;
3)速度要快。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
形成集群的每个服务器称为节点。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
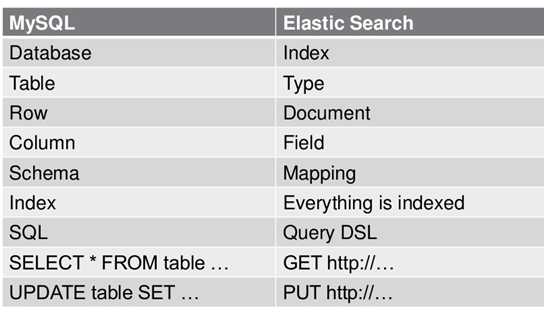
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type)
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。
与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
Elasticsearch常用术语
Document:文档数据,具体意义就是存储于elasticsearch中的一条数据
Index:索引,具体意义可以理解成mysql中的一个数据库
Type:索引中的数据类型。可以理解成一个表
Field:字段,文档的属性,理解为表中的字段
文档
它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。简单说,它就是一个json对象,存放着数据,这个就叫文档,且具有唯一性。
文档元数据
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index:文档在哪存放(索引)
一个 索引 应该是因共同的特性被分组到一起的文档集合。 例如,你可能存储所有的产品在索引
products中,而存储所有销售的交易到索引sales中。名字必须小写,不能以下划线开头,不能包含逗号。
_type:文档表示的对象类别(类型)
数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如 "electronics" 、 "kitchen" 和 "lawn-care"。
这些文档共享一种相同的(或非常相似)的模式:他们有一个标题、描述、产品代码和价格。他们只是正好属于“产品”下的一些子类。
_id:文档唯一标识(身份证号)
ID 是一个字符串,当它和
_index以及_type组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的_id,要么让 Elasticsearch 帮你生成。
索引篇
查看所有索引
命令行:curl -X GET”localhost:9200/_cat/indices?v”
Kibana: GET /_cat/indices?v
创建一个索引
命令行:curl -X PUT”localhost:9200/student?pretty”
Kibana: PUT /student
删除一个索引
命令行:curl -X DELETE”localhost:9200/student?pretty”
Kibana: DELETE /student
检查索引是否存在
命令行: curl -i -XHEAD http://localhost:9200/student
Kibana: HEAD/student(查看student文档是否存在) || HEAD /student/class1/3(查看ID为3的具体数据是否存在)
文档篇
查看所有文档数据
Kibana:POST /_search || POST /goods/_search || POST /goods/good/_search POST只可范围性查找,在指定索引index或指定类型type,但不能指定一个文档ID查找。
GET /_search || GET /goods/_search || GET /goods/good/_search GET没有此限制,它就是用于指定查找,当然范围也可以。
创建文档 关键词_create 可加可不加
命令行:curl -X PUT”localhost:9200/student/class1/1” -d’ //注意单引号’ 还有最后}后面的单引号’
{
"name":"汤姆",
"age":"23",
"favorite":"basketball"
}’
kibana:
PUT /goods/good/1/_create
{
"name":"iPhone XS Max",
"price":"8999",
"color":["黑色","红色","金色","银色","白色"],
"describe":"Apple iPhone XS Max (A2104) 64GB 金色 移动联通电信4G手机 双卡双待"
}POST /goods/good/2
{
"name":"iPhone 11 Pro Max",
"price":"9599",
"color":["暗夜绿色","深空灰色","金色","银色"],
"describe":"Apple iPhone 11 Pro Max (A2220) 64GB 金色 移动联通电信4G手机 双卡双待"
}
查询文档
查看具体的一个文档
命令行:curl -X GET “localhost:9200/goods/good/1?pretty”
kibana:GET /goods/good/1
删除文档
命令行:curl -XDELETE ‘localhost:9200/goods/good/1’
kibana:DELETE /student/class1/1 指定ID文档删除
DELETE /student || DELETE /student/class1 范围删除
更新文档之整体更新 和添加没差别,只是将信息替换
curl -X PUT”localhost:9200/goods/good/1?pretty” -H ’Content-Type:application/json’ -d’
{
"name":"汤姆",
"age":"23",
"favorite":"basketball"
}’
PUT /goods/good/1
{
"name":"iPhone XS Max",
"price":"8999",
"color":["黑色","红色","金色","银色","白色"]
}
更新文档之部分更新 关键字_update 将指定的文档中部分字段更新,不会影响其他字段
curl -X POST ”localhost:9200/goods/good/1/_update?pretty” -H ’Content-Type:application/json’ -d’
{
"doc":{
"describe":"Apple iPhone 11 Pro Max (A2220) 64GB 金色 移动联通电信4G手机 双卡双待"
}
}’
POST /goods/good/1/_update
{
"doc":{
"describe":"Apple iPhone 11 Pro Max (A2220) 64GB 金色 移动联通电信4G手机 双卡双待"
}
}
查询篇
空查询
GET /_search || GET /goods/_search 可指定索引或类型查询,不知道查询所有文档
{
"hits" : {
"total" : 14,
"hits" : [
{
"_index": "us",
"_type": "tweet",
"_id": "7",
"_score": 1,
"_source": {
"date": "2014-09-17",
"name": "John Smith",
"tweet": "The Query DSL is really powerful and flexible",
"user_id": 2
}
},
... 9 RESULTS REMOVED ...
],
"max_score" : 1
},
"took" : 4,
"_shards" : {
"failed" : 0,
"successful" : 10,
"total" : 10
},
"timed_out" : false
}
hits
返回结果中最重要的部分是
hits,它包含total字段来表示匹配到的文档总数,并且一个hits数组包含所查询结果的前十个文档。在
hits数组中每个结果包含文档的_index、_type、_id,加上_source字段。这意味着我们可以直接从返回的搜索结果中使用整个文档。这不像其他的搜索引擎,仅仅返回文档的ID,需要你单独去获取文档。每个结果还有一个
_score,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照_score降序排列的。在这个例子中,我们没有指定任何查询,故所有的文档具有相同的相关性,因此对所有的结果而言1是中性的_score。
多类型,多索引
/_search:在所有的索引中搜索所有的类型
/gb/_search:在gb索引中搜索所有的类型
/gb,us/_search:在gb和us索引中搜索所有的文档
/g*,u*/_search:在任何以g或者u开头的索引中搜索所有的类型
/gb/user/_search:在gb索引中搜索user类型
/gb,us/user,tweet/_search:在gb和us索引中搜索user和tweet类型
/_all/user,tweet/_search:在所有的索引中搜索user和tweet类型
轻量搜索
有两种形式的 搜索 API:一种是 “轻量的” 查询字符串 版本,要求在查询字符串中传递所有的参数,
另一种是更完整的 请求体 版本,要求使用 JSON 格式和更丰富的查询表达式作为搜索语言。
轻量
GET /goods/_search?q=iphone //任何字段中,只要包含iPhone,就匹配到。(注意查询的内容 是单独的,不能与其他内容相连。如:iPhone8匹配不到,iPhone 8匹配的到。 前后无内容相连)
复杂的查询
+name:(yuan zhang) + age:>35 + (male) 多个条件是或的关系
q=male 等同于 q=+(male)
多条件如下
name字段中包含mary或者johndate值大于2014-09-10_all字段包含aggregations或者geoGET /goods/_search?+name:(mary john) +date:>2014-09-10 +(aggregations geo)
更多:GET /goods/_search?q=+name:(IPhone Max Mac) +color:黑色 -price:>90000
批量操作 关键词_bulk
格式
{action:{metadata}} \n
{request body} \n
{action:{metadata}} \n
{request body} \n
action 必须是以下选项之一
create如果文档不存在,那么就创建它。
index创建一个新文档或者换一个现有文档。
update 部分更新一个文档
delete 删除一个文档
Metadata 指定被索引、创建、更新或者删除的文档的_index、_type和_id。
request body 一般除了delete命令没有body,其他都有
POST /_bulk
{ "delete": { "_index": "goods", "_type": "good", "_id": "3" }}
{ "create": { "_index": "goods", "_type": "good", "_id": "1" }}
{ "name": "iPhone" }
{ "index": { "_index": "goods", "_type": "good" }}
{ "name": "iPhone XS", "price" : 8000}
{ "update": { "_index": "goods", "_type": "good", "_id": "10"} }
{ "doc" : {"price" : 8900} }
curl -X POST ”localhost:9200/_bulk?pretty” -H ’Content-Type:application/json’ -d’
{ "delete": { "_index": "student", "_type": "class1", "_id": "3" }}
{ "create": { "_index": "student", "_type": "class1", "_id": "101" }}
{ "name": "xiaozhao" }
{ "index": { "_index": "student", "_type": "class1" }}
{ "name": "xiaoqiang", "age" : 15 }
{ "update": { "_index": "student", "_type": "class1", "_id": "10"} }
{ "doc" : {"age" : 32} }’
//可省略_index _type _id 按需添加
curl -X POST ”localhost:9200/_bulk?pretty” -H ’Content-Type:application/json’ -d’
{ "delete": { "_id": "2" }}
{ "create": { "_id": "200" }}
{ "name": "xiaozhang" }’
POST /goods/good/_bulk
{ "delete": { "_id": "2" }}
{ "create": { "_id": "200" }}
{ "name": "xiaozhang" }
更多内容请看官方文档
更多内容请看官方文档
更多内容请看官方文档
原文:https://www.cnblogs.com/FondWang/p/12001410.html