阻塞:程序遇到IO阻塞,程序遇到IO立马会停止(挂起),cpu马上切换,等IO结束后再执行
非阻塞:程序没有IO或者遇到IO通过某种手段让CPU去执行同一个线程里面的其他的任务,尽可能的占用CPU
# 异步回收任务的方式一: 将所有任务的结果统一收回
from concurrent.futures import ProcessPoolExecutor
import os
import time
import random
def task():
print(f'{os.getpid()} is running')
time.sleep(random.randint(1, 3))
return f'{os.getpid()} is finish'
if __name__ == '__main__':
p = ProcessPoolExecutor(4)
lst = []
for i in range(10):
res = p.submit(task) # 异步发出 res返回一个future的对象
lst.append(res)
# print(res.result()) # 在这里result()就会变成同步
p.shutdown(wait=True)
# 1.阻止再向进程池投放新的任务
# 2.wait=True 一个任务完成了就减一,直至为0才执行下一行
for res in lst:
print(res.result()) # 通过对象点的方式取出结果?
# 浏览器做的事情很简单,封装一些头部,发一个请求到服务器,服务器拿到请求信息,分析信息,分析正确之后,给浏览器返回一个文件,浏览器将这个文件的代码渲染就成了网页
# 爬虫: 利用requests模块,模拟浏览器,封装头给服务器发送请求,骗过服务器,服务器也给你返回一个文件,
# 爬虫拿到文件进行数据清洗,获取想要的信息
# 爬虫: 分两步
# 第一步: 爬取服务端的文件(IO阻塞)
# 第二步: 拿到文件,进行数据清洗(非IO,极少IO)
# 版本一
from concurrent.futures import ProcessPoolExecutor
import requests # 爬虫相关模块
import time
import os
import random
def get(url): # 爬取文件
response = requests.get(url)
print(os.getpid(), '正在爬取:', url)
time.sleep(random.randint(1, 3))
if response.status_code == 200:
return response.text
def parse(text): # 对爬取回来的字符串的分析,用len模拟一下
print('分析结果:', len(text))
if __name__ == '__main__':
url_list = [
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/',
'https://www.cnblogs.com/'
]
pool = ProcessPoolExecutor(4)
obj_list = []
for url in url_list:
obj = pool.submit(get, url)
obj_list.append(obj)
pool.shutdown(wait=True)
for obj in obj_list:
text = obj.result()
parse(text)
# 问题出在哪里?
# 1.分析结果的过程是串行,效率低
# 2.将所有的结果全部爬取成功之后,放在一个列表中
-------------------------------------------------------
# 版本二:异步处理,获取结果的第二种方式
# 完成一个任务,返回一个结果,并发的获取结果
from concurrent.futures import ProcessPoolExecutor
import requests
import time
import os
import random
def get(url): # 爬取文件
response = requests.get(url)
print(os.getpid(), '正在爬取:', url)
time.sleep(random.randint(1, 3))
if response.status_code == 200:
parse(response.text)
# return response.text
def parse(text): # 对爬取回来的字符串的分析,用len模拟一下
print('分析结果:', len(text))
if __name__ == '__main__':
url_list = [
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/',
'https://www.cnblogs.com/'
]
pool = ProcessPoolExecutor(4)
for url in url_list:
obj = pool.submit(get, url)
pool.shutdown(wait=True)
# 问题,增强了耦合性
------------------------------------------------------
# 版本三: 版本二,两个任务有耦合性.在上一个基础上,对其进行解耦
from concurrent.futures import ProcessPoolExecutor
import requests
import time
import os
import random
def get(url): # 爬取文件
response = requests.get(url)
print(os.getpid(), '正在爬取:', url)
time.sleep(random.randint(1, 3))
if response.status_code == 200:
return response.text
def parse(obj): # 对爬取回来的字符串的分析,用len模拟一下
print(f'{os.getpid()}分析结果:', len(obj.result()))
if __name__ == '__main__':
url_list = [
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/',
'https://www.cnblogs.com/'
]
pool = ProcessPoolExecutor(4)
for url in url_list:
obj = pool.submit(get, url)
obj.add_done_callback(parse) # 增加一个回调函数
# 现在的进程完成的还是网络爬取的任务,拿到返回值之后,丢给回调函数,
# 进程继续完成下一个任务,回调函数进行分析结果
pool.shutdown(wait=True)
# 回调函数是主进程实现的,回调函数帮我们进行分析任务
# 明确了进程的任务就是网络爬取,分析任务交给回调函数执行,对函数之间解耦
# 极值情况: 如果回调函数是IO任务,那么由于回调函数是主进程做的,所以有可能影响效率
# 回调不是万能的,如果回调的任务是IO,那么异步+回调机制不好,此时如果需要效率,只能再开一个线程或进程池
# 异步就是回调?
# 这个论点是错的,异步,回调是两个概念
# 如果多个任务,多进程多线程处理的IO任务
# 1. 剩下的任务 非IO阻塞 异步+回调机制
# 2. 剩下的任务有 IO 远小于 多个任务的IO 异步+回调机制
# 3. 剩下的任务 IO 大于等于 多个任务的IO 第二种解决方式,或者开启两个进程/线程池FIFO: 先进先出
import queue
#不需要通过threading模块里面导入,直接import queue就可以了,这是python自带的
#用法基本和我们进程multiprocess中的queue是一样的
q = queue.Queue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(先进先出):
first
second
third
'''LIFO: 后进先出(栈)
import queue
q = queue.LifoQueue() # 队列,类似于栈
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(后进先出):
third
second
first
'''Priority: 优先级队列
import queue
q = queue.PriorityQueue()
# put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((-10, 'a'))
q.put((-5, 'a')) #负数也可以
# q.put((20, 'ws')) #如果两个值的优先级一样,那么按照后面的值的acsii码顺序来排序,如果字符串第一个数元素相同,比较第二个元素的acsii码顺序
# q.put((20, 'wd'))
# q.put((20, {'a': 11})) #TypeError: unorderable types: dict() < dict() 不能是字典
# q.put((20, ('w', 1))) #优先级相同的两个数据,他们后面的值必须是相同的数据类型才能比较,可以是元祖,也是通过元素的ascii码顺序来排序
q.put((20, 'b'))
q.put((20, 'a'))
q.put((0, 'b'))
q.put((30, 'c'))
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
'''
结果(数字越小优先级越高,优先级高的优先出队):
(-10, 'a')
(-5, 'a')
(0, 'b')
(20, 'a')
(20, 'b')
(30, 'c')
'''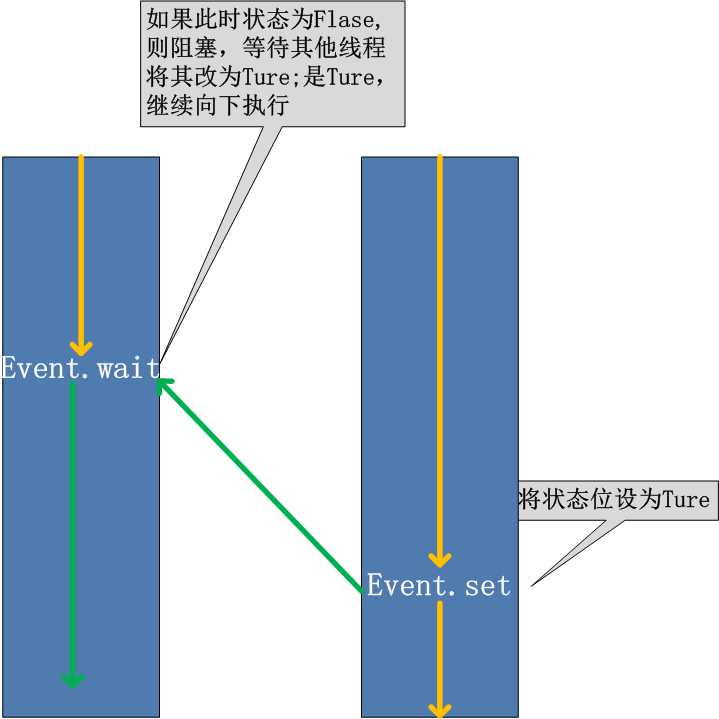
方法
event.isSet(): 返回event的状态值
event.wait(): 如果 event.isSet() == False将阻塞线程
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度
event.clear(): 恢复event的状态值为False示例
from threading import Thread
from threading import current_thread
from threading import Event
import time
event = Event() # 默认False
def task():
print(f'{current_thread().name}检测服务器是否正常开启....')
time.sleep(3)
event.set() # 改成True
def task1():
print(f'{current_thread().name}正在尝试连接服务器')
event.wait() # 阻塞,轮询检测event是否为True,当其为True,继续下一行代码
# event.wait(1) # 超时时间,超过时间无论是否为True都继续下一行代码
print(f'{current_thread().name}连接成功')
if __name__ == '__main__':
t1 = Thread(target=task1)
t2 = Thread(target=task1)
t3 = Thread(target=task1)
t = Thread(target=task)
t1.start()
t2.start()
t3.start()
t.start()并发编程----同步,异步,阻塞,非阻塞,异步加回调机制,线程队列,event事件
原文:https://www.cnblogs.com/douzi-m/p/11984406.html