Scala对XML有内建支持。例:
//类型为scala.xml.Elem val doc=<html><head><title>Test</title></head></html> //类型为scala.xml.NodeSeq val item=<li>Test1</li><li>Test2</li>
Node是所有XML节点类型的祖先,两个重要的子类Text和Elem
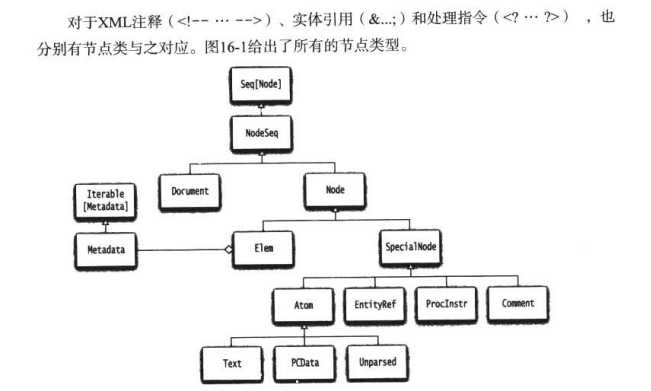
要处理某个元素的属性键和值,可以使用attributes属性,会产生一个MetaData对象,类似于映射。但是产出的是一个节点序列,而不是字符串。。。
可以在XML字面量中包含Scala代码块,动态计算元素的内容。如果代码块产出一个节点序列,序列中的节点会被直接添加到XML,所有其他值都会被放到一个Atom[T]中,这是一个针对类型T的容器,通过data属性取值。。。
可以用Scala表达式计算属性值,内嵌的代码块也可以产出一个序列。。。
有能时需要将非XML文本包含到XML文档中,需要在XML字面量中使用CDATA标记。。。
NodeSeq类提供了类似Xpath中的/和//操作符方法。由于//表示注释,Scala用\和\\替换。
\操作符定位于某个节点或节点序列的直接后代。
\\操作符定位于任何深度的后代。
可以在模式匹配中使用XML字面量。。。
在Scala中,XML节点和节点序列是不可变的如果想要编辑一个节点,则必须创建一个拷贝,给出需要的修改,然后拷贝未被显示修改的部分。
要拷贝Elem节点,用copy方法,有五个参数:label,attributes,child,还有用于命名空间的prefix和scope。
XML类库提供了一个RuleTransforms类可以将一个或多个RewriteRule实例应用到某个节点及其后代(需要重写所有满足某个特定条件的后代)。。。
要从文件中加载XML文档,调用XNL对象的loadFile方法:
import scala.xml.XML val root=XML.loadFile("xx.xml")
也可以从java.io.InputStream.java.io.Reader或URL加载:
val root2=XML.load(new FileInputStream("xx.xml")) val root3=XML.load(new InputStreamreader(new FileInputStream("xx.xml"),"UTF-8")) val root4=XML.load(new URL("https://...."))
注:文档使用标准的SAX解析器加载(没有提供文档类型定义);
Scala还提供了一个解析器,可以保留注释、CDATA节和空白(scala.xml.parsing.ConstructingParser)
。。。
类似于Java/C++中,命名空间用来避免名称冲突。
XML命名空间是一个URL,使用xmlns声明一个命名空间。。。


原文:https://www.cnblogs.com/lyq-biu/p/11977833.html