这是一个古老的问题,即我们输入URL后按下回车到网页测呈现都发生了什么?
首先来看一张图:
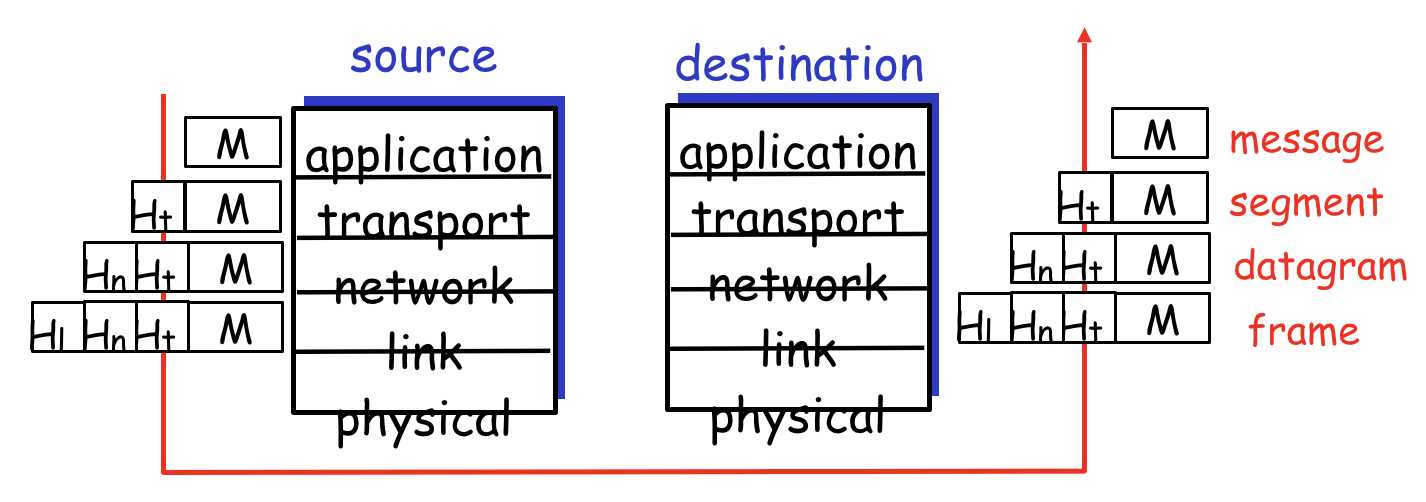
表示了数据从源端到目的端的封装和拆解过程
URL格式:
以http为例:
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
有时候我们并没有输入完整的url,浏览器会智能地进行自动补全,如浏览器会对不同协议自动添加端口,如http的80端口,https的443端口等等。除此之外浏览器还会根据我们的历史记录,书签等信息进行智能提示,并对一些非ASCII字符进行编码。如果不合法,将会转为搜索关键字。
浏览器在得到合法的URL后,就要进行域名解析,DNS采用UDP协议进行传输数据,默认端口为53,DNS查询过程本质上还是一个客户端请求服务端的过程,它同样会经过其下面的网络层和数据链路/物理层的封装。
只考虑查询过程:
chrome://net-internals/#dns)NSCD缓存服务/etc/hosts 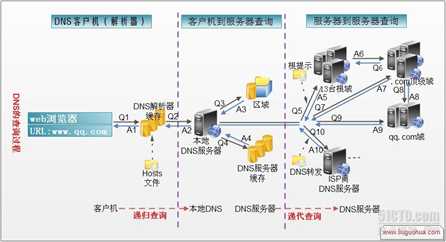
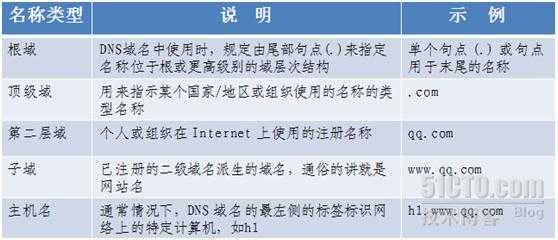
图片来源:51cto
我们可以使用命令dig +trace www.luoxia.me来跟踪dns查询过程:
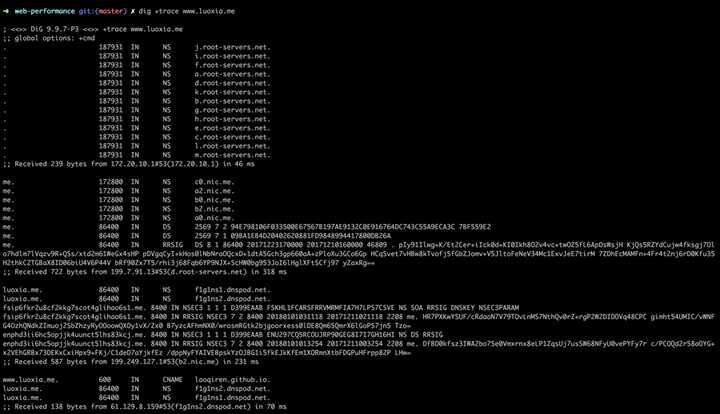
可以清晰地看到这个迭代查询的过程。
浏览器得到IP地址和端口号以后,就会调用系统库函数socket,请求一个TCP流套接字,下面是之后的逐层封装过程:
ARP 广播来查询其地址。
数据可以通过以下方式进行传输:
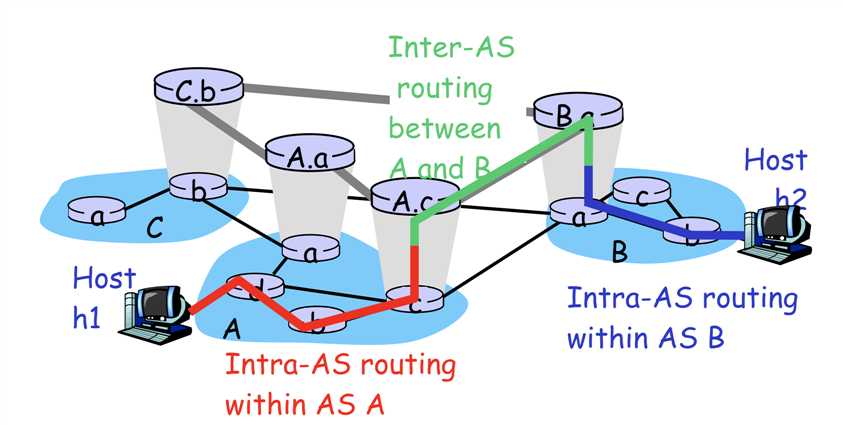
数据经过一层层封装,经过本地网络,传送到网络的下一个节点,再到管理该主机所在子网的路由器,这个路由器经过区域内路由(Intra-AS routing)算法(如RIP)将数据发送给自治区域(autonomous system, 缩写 AS,如运营商区域网络)的边界路由(网关),再通过区域间路由(Inter-AS routing)算法(如BGP)找到其他域的边界路由,再经过区域内路由算法,直到找到目的主机。
一路上经过的这些路由器会从IP数据报头部里提取出目标地址,并将封包正确地路由到下一个目的地。IP数据报头部 time to live (TTL) 域的值每经过一个路由器就减1,如果封包的TTL变为0,或者路由器由于网络拥堵等原因封包队列满了,那么这个包会被路由器丢弃。
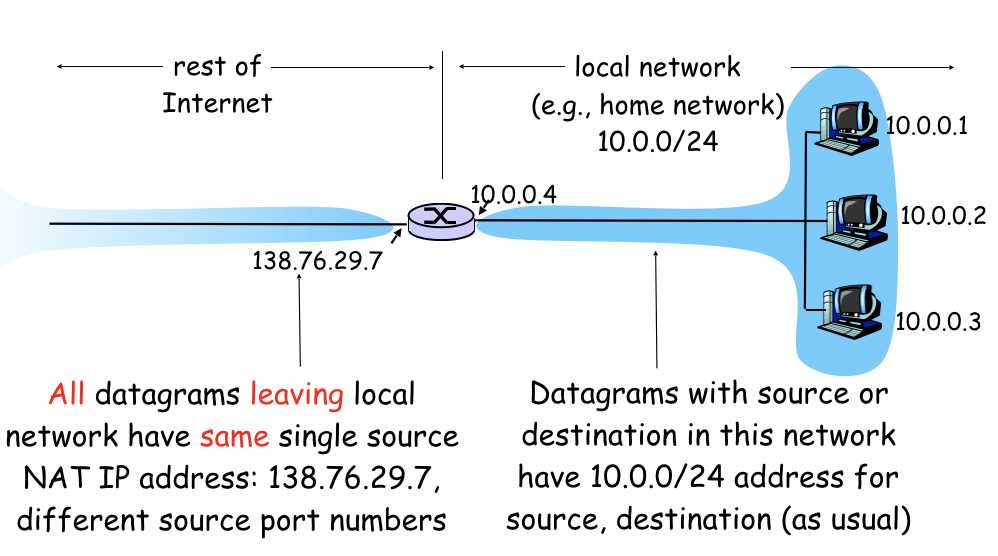
此外,由于IPV4的能够分配的IP有限,我们往往使用NAT来进行公网到内网的地址映射:
数据包最终传到目的主机的网卡,接着网卡会将数据拷贝到内存中(DMA),然后通过中断来通知 CPU,经过一层层的拆解到达指定端口的进程进行处理。
可以看到,我们的数据包会经过多个路由的不断转发,由于路由存在的各种延迟,会导致性能瓶颈的出现,后面会细讲。此外,TCP协议用于点对点的可靠传输,此部分也存在性能瓶颈,会在后面的小节单独展开。
可以通过命令traceroute查看数据包经过的路由.
客户端发起的请求形成HTTP请求报文,经过层层封装最终到达服务端HTTP服务器所在进程,HTTP服务在接受到请求报文后,连同数据形成响应报文,再通过传输层、网络层等等地包装传输回客户端。
以luoxia.me/images/climb.jpg为例:
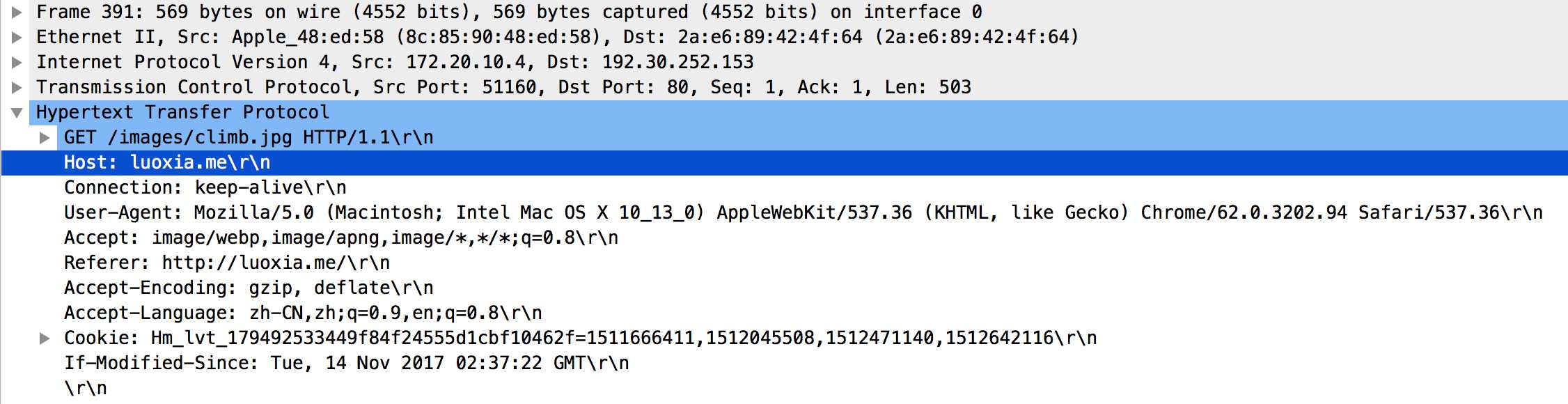
访问网页的时候,服务端最终返回html文档,接下来就是网页的渲染过程了,这部分参照网页渲染原理章节。
各层协议的具体字段可以通过抓包分析
从输入url到数据内容的返回,更多的学习:
可参考链接:https://www.cnblogs.com/LXG97/p/10999022.html
http://www.bubuko.com/infodetail-2275283.html
参考:
前端性能优化----从输入URL开始到返回数据的中间经历过程
原文:https://www.cnblogs.com/syw20170419/p/11953774.html
