WHERE 子句中主要的运算符,可以在 WHERE 子句中使用,如下表:
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
WHERE 子句中主要的运算符,可以在 WHERE 子句中使用,如下表:
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name;
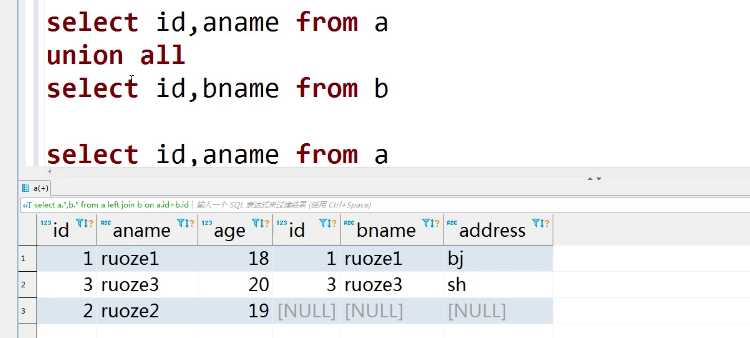
select a.*,b.* from a left join b as bb on a.id=b.id
输出结果:
select a.*,b.* from a right join b on a.id=b.id;
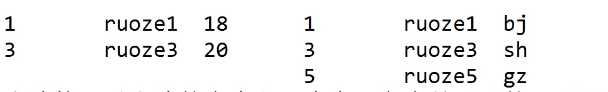
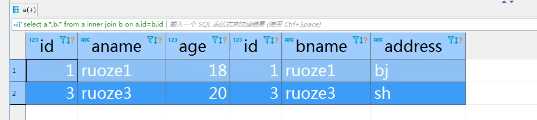
select a.*,b.* from a inner join b on a.id=b.id;
select sum(age)from rzdata; #数值求和sum(id) select count(*)from rzdata; #数值求和求条数1+1+1=3
应该注意:1、少用count(* ),应该将任一列替换*, count(0)表示第一列;
2、算age数据多少 sum(age)。count(age)表示查询age的个数,age 表示age<20的记录值,sum(age)表示age的和;

3、count(distinct id)去掉重复记录的条数,效果对比,如:
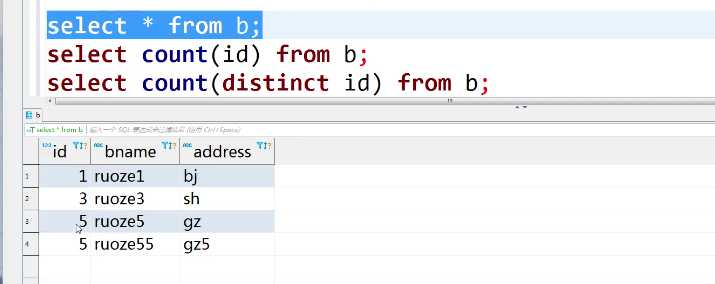
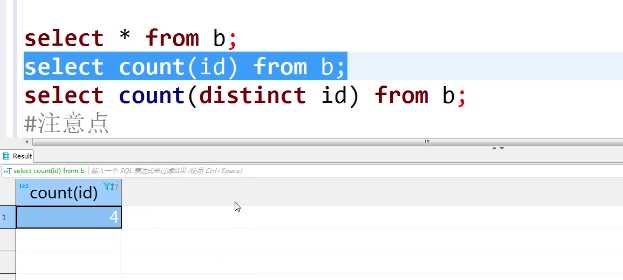
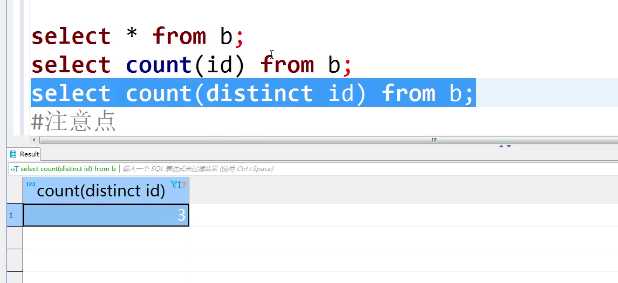
方法一:
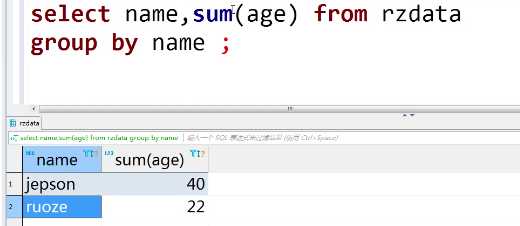
select sum(age)from rzdata group by name
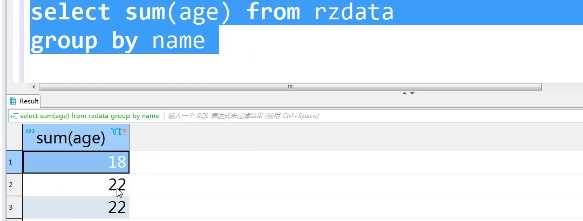
方法二:
select * from rzdata;
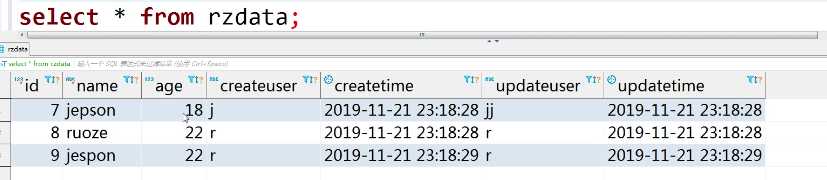
select name,sum(age) from rzdata group by name;
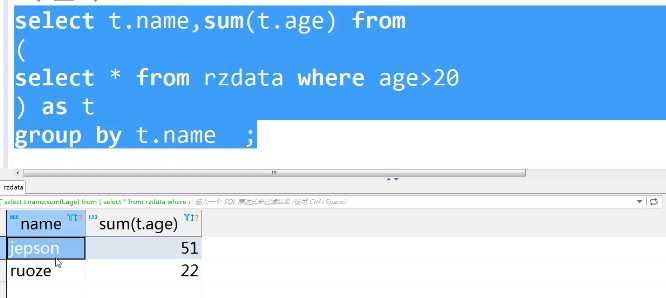
方法一:
select t. name, sum(t. age) from select * from rzdata where age>20 ) as t group by t. name;
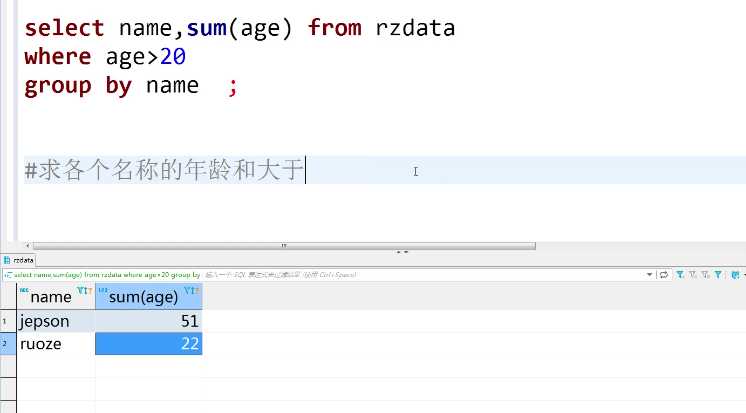
方法二:
select name,sum(age) from rzdata where age>20 group by name;
select name,sum(age) from rzdata group by name having sum(age)>25;
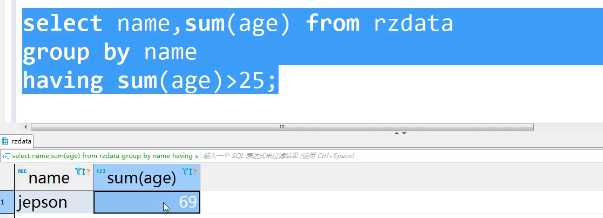
表级别名,尽量少用子查询
select * from select name, sum(age) as sumage from rzdata group by name ) as t where t. sumage >25
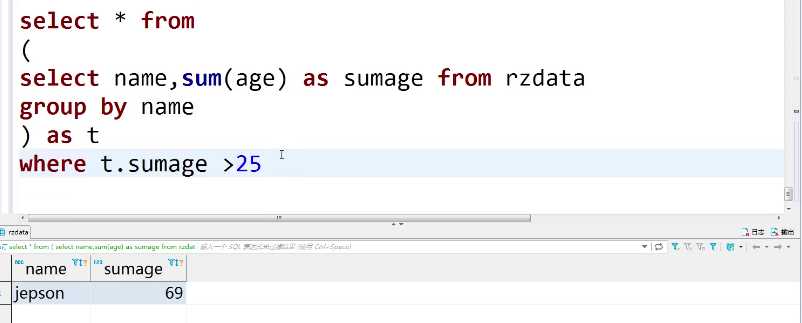
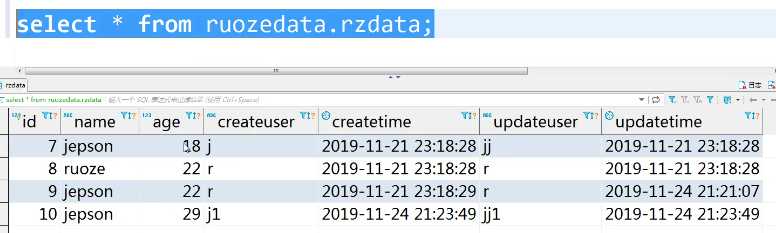
select * from ruozedata.rzdata;
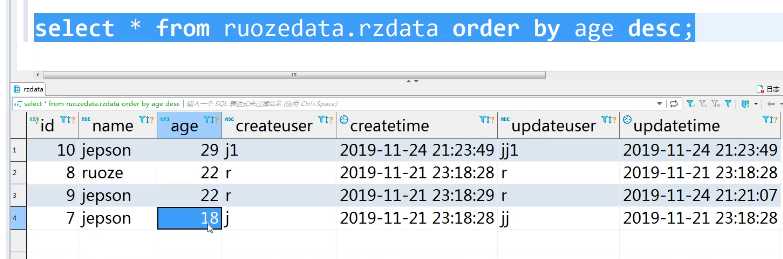
select * from ruozedata.rzdata order by age desc;
按照名字排序:
select * from ruozedata.rzdata order by name desc;
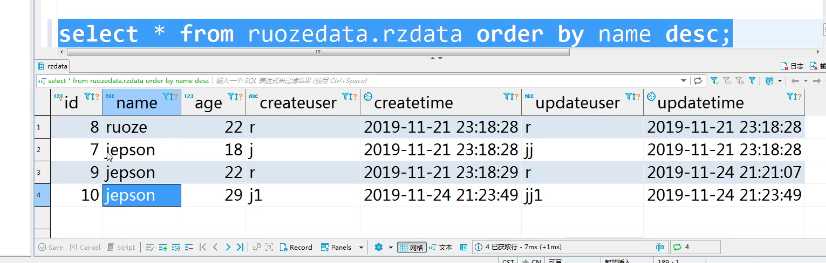
#desc倒序
#asc升序 默认,可以不加该参数
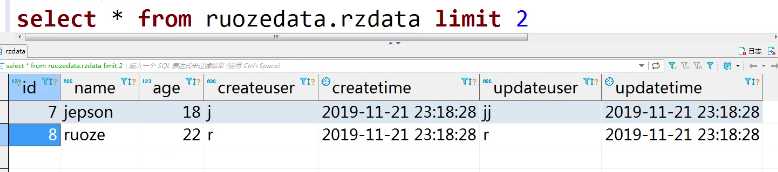
select * from ruozedata.rzdata limit 2
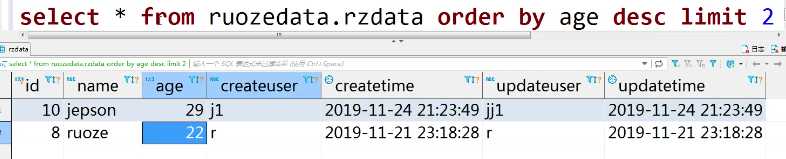
select * from ruozedata.rzdata order by age desc limit 2
select yyyyy from zzz where xxx group by xxx having xxx order by xxx limit xxx;
上述的关键词,顺序不能颠倒
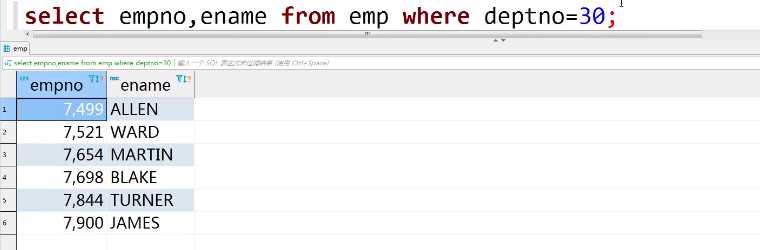
select empno,ename from emp where deptno=30;
select * from emp where(deptno=10 and job=‘MANAGER‘) or (deptno=20 and job=‘SALESMAN‘);
select * from emp order by sal desc,hiredate asc;
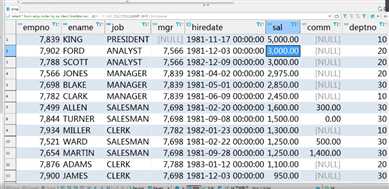
思路:首先查出,最低薪金大于1500的
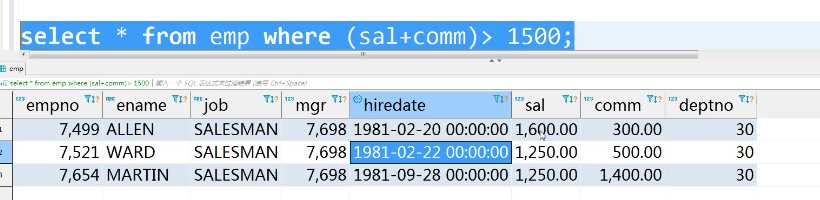
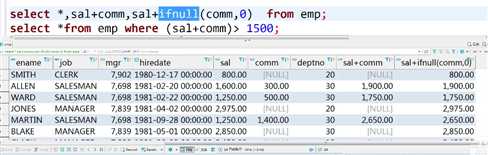
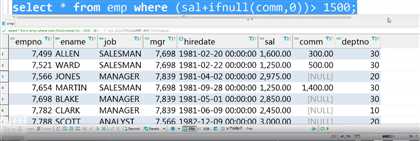
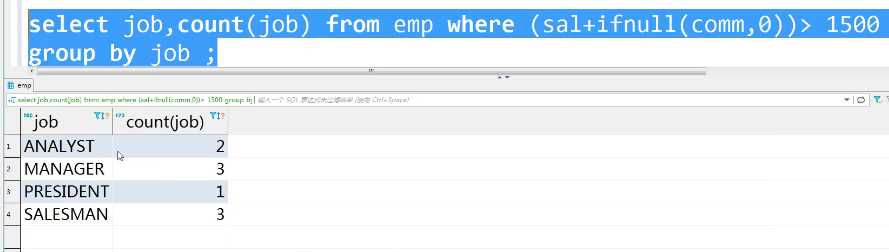
having可以来自其他字段的数值
select job,count(job)from emp group by job having min(sal+ifnull(comm,0))>1500;
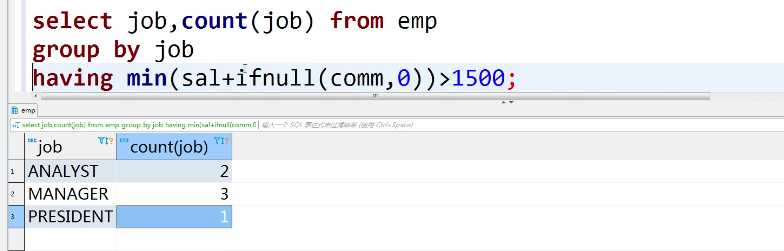
select xxx,yyyy,count(job) from emp group by xxx,yyyy;
group by后面的xxx,yyyy 应该和前面 select xxx,yyyy一致
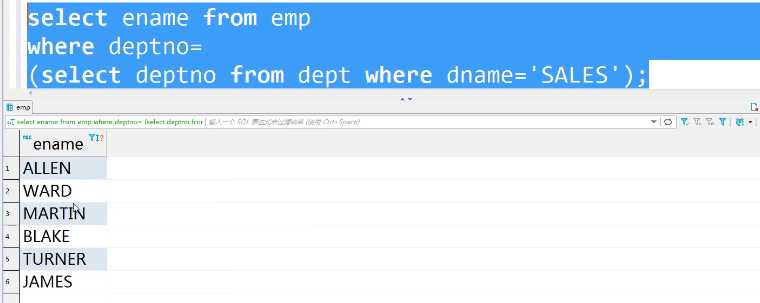
select ename from emp where deptno= (select deptno from dept where dname=‘SALES‘);
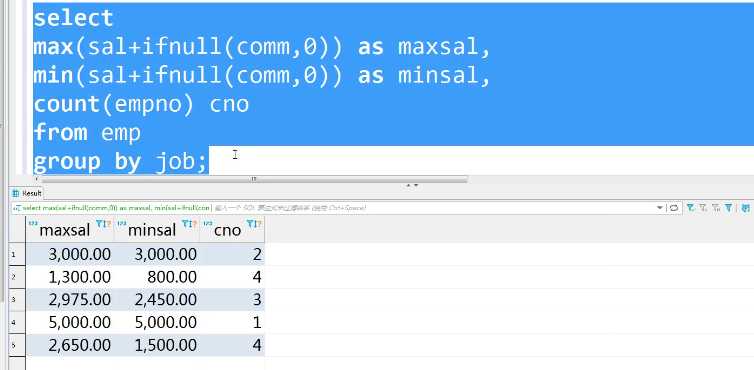
select max(sal+ifnull(comm,0)) as maxsal,min(sal+ifnul1(comm,0)) as minsal, count(empno) cno from emp group by job;
select e. ename, e. deptno,d. dname, e. mgr, m.ename, e.sal+ifnull(e.comm,0) as sal, s. grade from emp e left join dept d on e. deptno=d. deptno left join emp m on e. mgr=m.empno left join salgrade s on (e.sal+ifnull(e.comm,0)) between s.losal and s.hisal where(e.sal+ifnull(e.comm,0)) > (select avg(sal+ifnull(comm,e)) from emp);
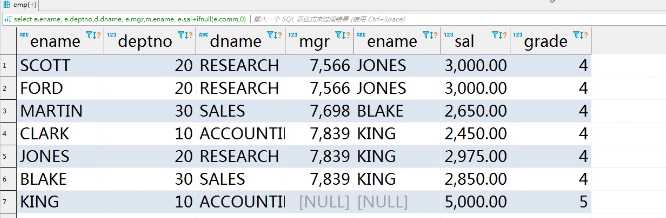
在大数据生产上join,第一反应on的字段一定先抽样检查null条数 ,其中a left join b on a.aid=b.bid ,若bid 或者aid 有null ,笛卡尔积前,先抽样
select aid,count(aid) from a;
使用该语句进行过滤:select * from a where aid is not null
数据仓库009 - SQL命令实战 - where GROUP BY join 部门综合案例
原文:https://www.cnblogs.com/Raodi/p/11925273.html