正则表达式就是为了处理大量的字符串而定义的一套规则和方法。
通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。
Linux正则表达式一般以 行 为单位处理。
工作中会有大量带有字符串的文本配置、程序、命令输出及日志文件等,我们经常会有迫切的需要,从大量的字符串内容中查找符合工作需要的特定的字符串。
这就需要正则表达式。
正则表达式就是为了过滤这样的字符串需求而诞生的。
正则表达式应用非常广泛,存在于各种语言中,例如:php, python, java等。
[root@oldboy test]# alias grep=‘grep --color=auto‘ [root@oldboy test]# alias grep alias grep=‘grep --color=auto‘
[root@oldboy test]# export LC_ALL=C [root@oldboy test]# echo $LC_ALL C
[root@oldboy test]# cat >>oldboy.log<<EOF > I am oldboy teacher! > I teach Linux. > > I like badminton ball, billiard ball and chinese chess! > my blog is http://oldboy.blog.51cto.com > our site is http://www.etiantian.org > my qq is 49000448. > > not 49000000448 > my god, I am not oldboy,but OLDBOY! > EOF
示例1:
以m开头的行(内容):grep ‘^m‘ oldboy.log
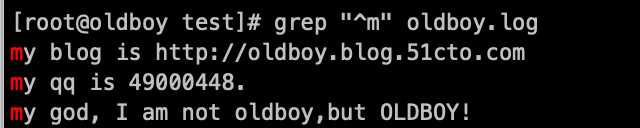
以m为结尾的行(内容 ):grep ‘m$‘ oldboy.log

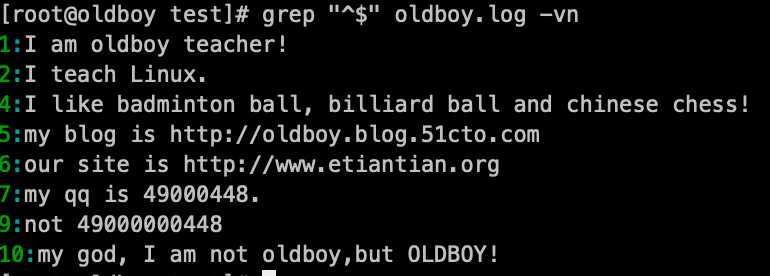
空行,通过-n参数定位到具体的行号:grep ‘^$‘ oldboy.log
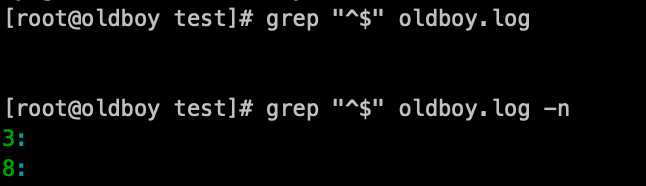
用-v参数,排除空行:grep -v ‘^$‘ oldboy.log
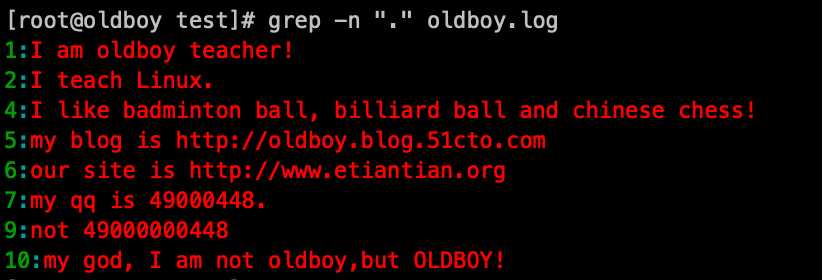
点(.)的含义小结:
1. 筛选任意一个字符的一行,空行没有字符,所以过滤排除掉了
grep -n ‘.‘ oldboy.log
2. "oldb.y"表示"oldb"任意一个字符"y"(不匹配大小写):grep -n ‘oldb.y‘ oldboy.log

3. -i 参数,匹配大小写: grep -ni ‘oldb.y‘ oldboy.log

4. 匹配以"."结尾的行: grep -ni ‘\.$‘ oldboy.log

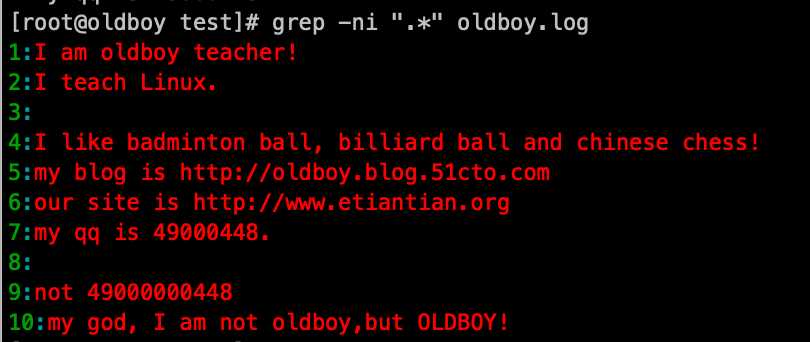
5. 匹配所有:".*": grep ‘.*‘ oldboy.log -ni
6. -o 参数,只显示匹配的内容,不显示整行: grep -no ‘oldb.y‘ oldboy.log

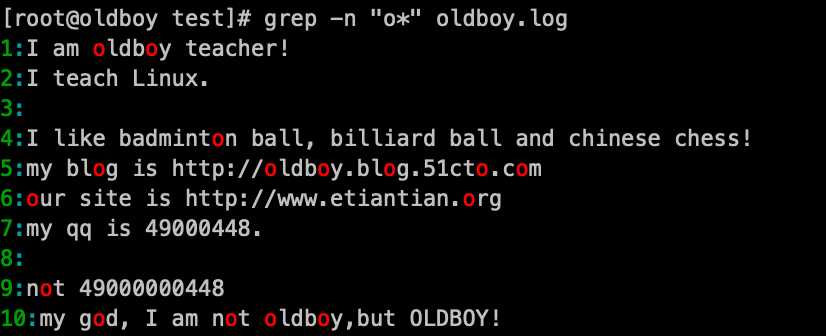
7. 匹配"o*"的内容:grep -n ‘o*‘ oldboy.log
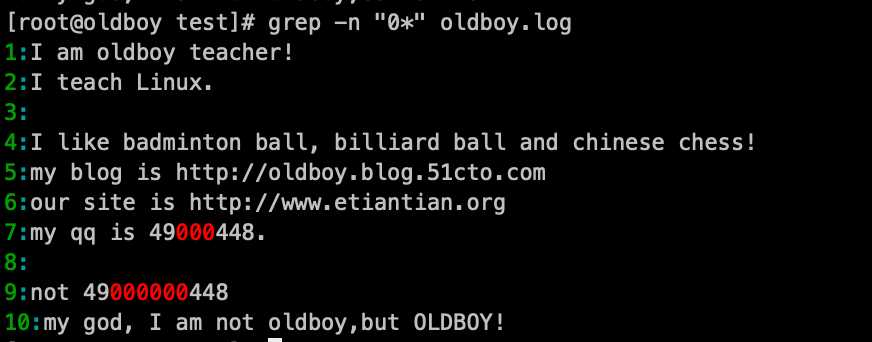
8. 匹配"0*"的内容: grep -n ‘0*‘ oldboy.log
注意:egrep 或 sed -r 过滤,一般特殊字符({})可以不转义
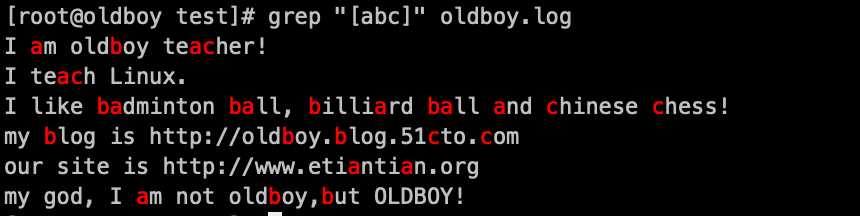
1. 匹配[abc]中任一一个字符 grep ‘[abc]‘ oldboy.log
2. 匹配[^abc]中的字符(非a,非b,非c)grep ‘[^abc]‘ oldboy.log
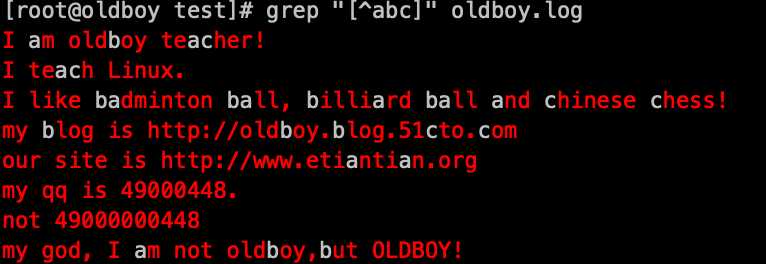
3. 匹配"oldboy"或"oldbey",不区分大小写:grep ‘oldb[oe]y‘ oldboy.log -io

4. 匹配含数字的行:grep ‘[0-9]‘ oldboy.log

5. 下面分别是:
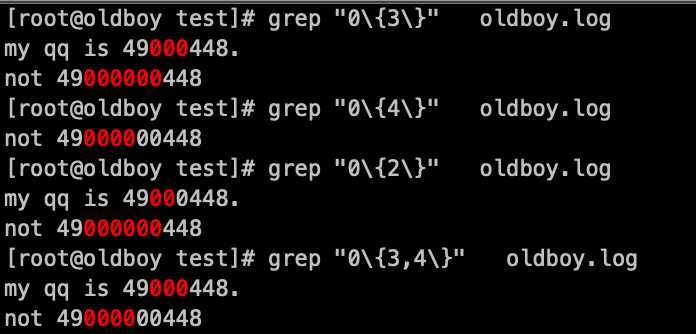
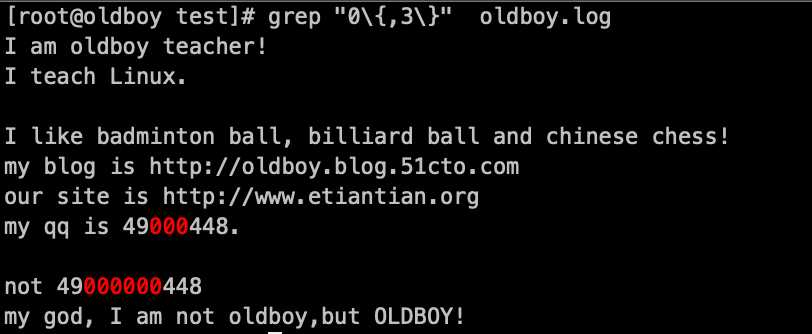
匹配0(重复0次到3次):
正则表达式(Regular Expression)实际上就是一些特殊符号,赋予了他特定的含义:
^ 以...开头
$ 以...结尾
^$ 表示空行
.* 匹配所有字符
[abc] 匹配字符集合内的任意一个字符[a-zA-Z],[0-9]。
注意:egrep 或 sed -r 过滤,一般特殊字符({})可以不转义
1. + 表示重复“一个或一个以上”前面的字符(* 是 0 个或多个)
[root@oldboy test]# grep -Eo "go+d" oldboy.log god [root@oldboy test]# grep -Eo "go.d" oldboy.log [root@oldboy test]# grep -Eo "go*d" oldboy.log god [root@oldboy test]# grep -Eo "g*d" oldboy.log d d d d d d d
2. ? 表示重复 “0个或1个”前面的字符(. 是有且只有1个):
[root@oldboy test]# echo good >>oldboy.log [root@oldboy test]# egrep "goo?d" oldboy.log --color=auto -o god good [root@oldboy test]# egrep "htt?p" oldboy.log my blog is http://oldboy.blog.51cto.com our site is http://www.etiantian.org
3. | 表示同时过滤多个字符串
[root@oldboy test]# egrep "3306|1521" /etc/services mysql 3306/tcp # MySQL mysql 3306/udp # MySQL ncube-lm 1521/tcp # nCube License Manager ncube-lm 1521/udp # nCube License Manager
4. () 分组过滤,后向引用:
[root@oldboy test]# egrep "g(o|oo)d" oldboy.log -o god good
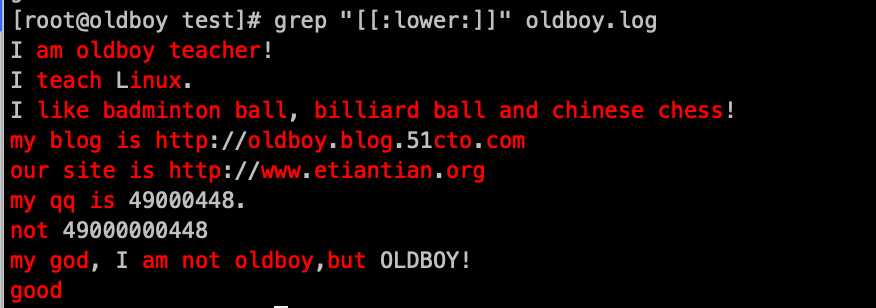
另外一个需要了解的知识:posix 方括号字符集(挺鸡肋的知道就行)
过滤小写字母:
元字符(meta character)是一种Perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的文本处理工具都支持。
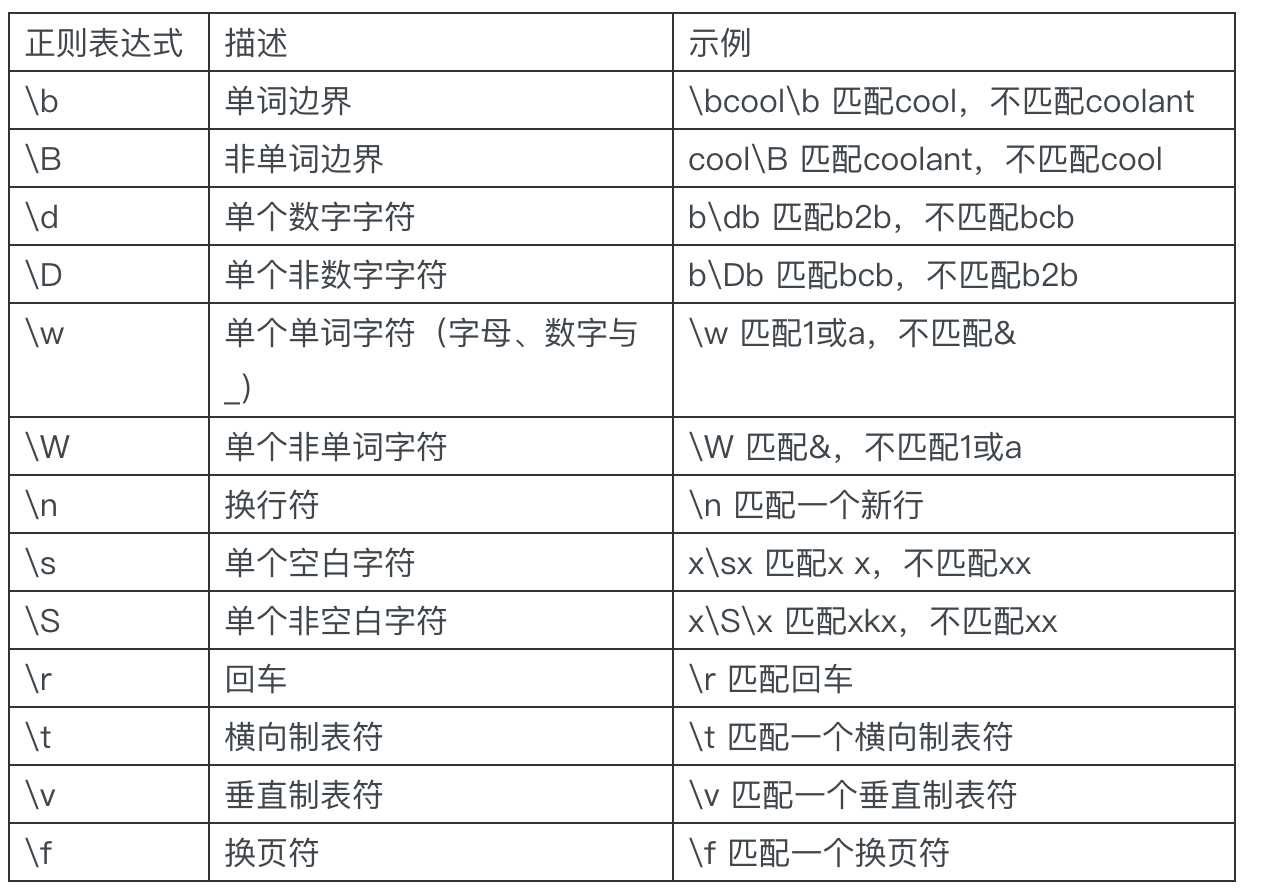
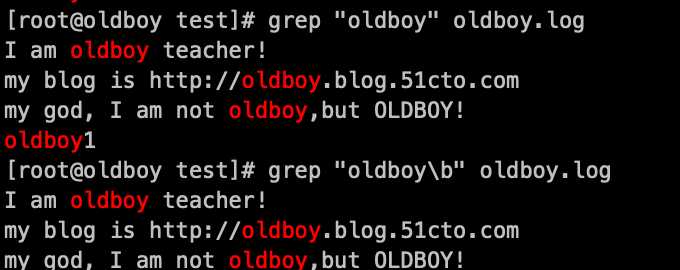
示例:\b 单词边界
Linux通配符和三剑客的正则表达式是不一样的,因此,代表的意义也有较大的区别。
通配符一般用户命令行bash环境,而linux正则表达式用于grep, sed, awk场景。
示例:* 的使用:代表任意0-N个字符,代表所有字符
[root@oldboy /]# mkdir /test [root@oldboy /]# cd /test [root@oldboy test]# touch test.sh oldboy.sh oldgirl.sh [root@oldboy test]# ls oldboy.sh oldgirl.sh test.sh [root@oldboy test]# ls *.sh oldboy.sh oldgirl.sh test.sh [root@oldboy test]# touch gongli.txt [root@oldboy test]# ls * gongli.txt oldboy.sh oldgirl.sh test.sh
[root@oldboy test]# ls ????.sh test.sh
示例:; 是命令之间的分隔符
[root@oldboy test]# whoami;pwd root /test
示例:单引号,双引号和反引号
# 单引号:所见即所得 [root@oldboy test]# echo ‘date‘ date # 双引号会解析,但是要加上反引号 [root@oldboy test]# echo "date" date # 双引号内部反引号执行的命令,会解析变量后输出 [root@oldboy test]# echo "`date`" Fri Sep 6 05:26:49 CST 2019 # 单引号:所见即所得,即使内部是反引号的命令,输出仍然是所见即所得。 [root@oldboy test]# echo ‘`date`‘ `date`
示例:{}
# 文件备份 [root@oldboy test]# cp test.sh{,.ori} [root@oldboy test]# ls test.sh* test.sh test.sh.ori # 批量创建文件 [root@oldboy test]# touch stu{1..5} [root@oldboy test]# ls stu* stu1 stu2 stu3 stu4 stu5 # 批量创建目录,目录下的子文件等 [root@oldboy test]# mkdir /test/a/{A..C}/{1..3}/end -p [root@oldboy test]# tree /test/ -d /test/ └── a ├── A │ ├── 1 │ │ └── end │ ├── 2 │ │ └── end │ └── 3 │ └── end ├── B │ ├── 1 │ │ └── end │ ├── 2 │ │ └── end │ └── 3 │ └── end └── C ├── 1 │ └── end ├── 2 │ └── end └── 3 └── end
原文:https://www.cnblogs.com/zoe233/p/11919424.html