以下内容为转载,原文出自微信公众号:JavaFamily
答:英俊潇洒的面试官,您好。我们可以先看一下 关系型数据库 和 Redis 本质上的区别。
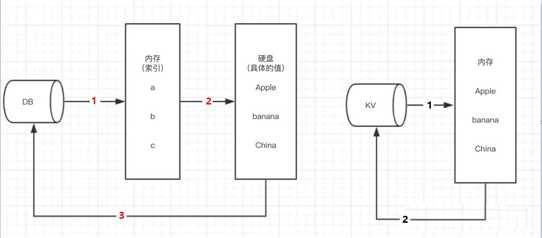
Redis采用的是基于内存的,采用的是单进程单线程模型的 KV 数据库,有C语言编写,官方提供的数据是可以达到 10w+ 的QPS(每秒内查询次数)。
我打个比方吧:以前有人这么问过我,上下文切换是啥,为什么会县城不安全?我是这么说的,就好比你看一本英文书,看到第十页发现有个单词不会读,你加了个书签,然后去查字典,过了一会儿你又回来继续从书签那里读,OK,到目前为止没什么问题的。
如果是你一个人读肯定没什么问题的,但是你去查的时候,别人好奇你在看啥,他过来翻一下你的数,然后就跑路了。当你再回来的时候,你会发现书不是你看的那一页了。不知道到这里为止,我有没有解释清楚,以及为什么会线程不安全,就是因为你一个人怎么看都没事,但是人多了,换来换去的操作,一本书的数据就乱了。可能我解释得比较粗糙,但是道理应该是差不多的。
答:是的,它是单线程的,但是,我们可以通过在单机开多个Redis实例嘛。
答:我们用到了集群的部署方式,也就是 Redis cluster ,并且是主从同步读写分离,类似 MySQL 的主从同步,Redis cluster 支撑 N 个 Redis master node,每个 master node 都可以挂载多个 slave node。
这样整个 Redis 就可以横向扩容了。如果你要支撑更大数据量的缓存,那就横向扩容更多的 master 节点,每个 master 节点就能存放更多的 数据了。
答:是的,持久化的话是 Redis 高可用中比较重要的一个环节,因为 Redis 数据再内存的特性,持久化必须得有,我了解到的持久化是两种方式的。
两种方式都可以把 Redis 内存中的数据持久化到磁盘上,然后再讲这些数据备份到别的地方去,RDB更适合做冷备,AOF更适合做热备,比如深圳某电商公司,有这两个数据,我备份一份到深圳的节点,再备份一份到广州的节点,就算发生无法避免的自然灾害,也不会两个地方都一起挂吧,这灾备也就是异地容灾,要是地球毁灭当我啥也没说。。。
Tip:两种机制全部开启的时候,Redis在重启的时候会默认使用AOF去重新构建数据,因为AOF的数据是比RDB更完整。
优点:
它会生成多个数据文件,每个数据文件分别代表了某一时刻 Redis 里面的数据,这种方式,有没有觉得很适合做冷备,完整的数据运维设置定时任务,定时同步到云端的服务器,比如阿里云服务,这样一旦线上挂了,你想恢复多少分钟之前的数据,就去云端拷贝一份之前的数据就好了。
RDB对 Redis 的性能影响非常小,是因为在同步数据的时候他只是 fork 了一个子进程去做持久化,而且他在数据恢复的时候速度比AOF来的快。
缺点:
RDB都是快照文件,都是默认五分钟甚至更久的时间才会生成一次,这意味着你这次同步到下次同步这中间五分钟的数据很有可能全部丢失。AOF则最多丢失一秒的数据,数据完整性上高低立判。
还有就是RDB在生成数据快照的时候,如果文件很大,客户端可能会暂停几毫秒甚至几秒,你公司在做秒杀或者抢单的时候,它刚好在这个时候 fork 了一个子进程去生成一个大快照,这肯定要出大问题的。
优点:
上面提到了,RDB五分钟一次生成快照,但是AOF是一秒一次去通过一个后台的县城 fsync 操作,那最多丢失这一秒的数据。
AOF在对日志文件进行操作的时候,是以 append-only 的方式去写的,他只是追加的方式写数据,自然就少了很多磁盘寻址的开销,写入性能惊人,文件也不容易破损。
AOF的日志是通过一个叫非常可读的方式记录的,这样的特性就适合做灾难性数据误删除的紧急恢复了,比如某公司的实习生通过 flushall 清空了所有的数据,只要这个时候后台重写还没发生,你马上拷贝一份AOF日志文件,把最后一条 flushall 命令删除了就完事了。
Tip:这命令别去线上系统操作啊!!!想试去自己买的服务器上装个Redis试!!!
缺点:
一样的数据,AOF文件比RDB还要大。
AOF开启后,Redis 支撑写的QPS会比RDB支持写的要低,他不是每秒都要去异步刷新一次日志 fsync 嘛,当然即使这样性能还是很高,我记得 ElasticSearch 也是这样的,异步刷新缓存区的数据去持久化,为什么这么做,而不是来一条怼一条呢?那我会告诉你这样性能可能低到没办法用的。至于为何这么做,后面记得再补了。
答:小朋友才会做选择题,我全都要!你单独使用RDB,你会丢失很多数据;你单独使用AOF,你数据恢复没RDB来得快,真出了什么问题,第一时间用RDB恢复,然后AOF做数据补全,简直不要太完美!冷备、热备一起上,才是互联网时代一个健壮系统的王道。
完了,给自己挖坑了。。。(其实早有准备,就等你来问!也提醒一下,不会的知识点,回答中别说,否则真就是自己挖坑还自己往里跳)
答:可以假装思考(略作思考,免得以为你真的不会),哦,想起来了,还有哨兵集群 sentinel 。
哨兵必须用三个实例去保证自己的健壮性,哨兵 + 主从 并不能保证数据不丢失,但是可以保证集群的高可用。
为什么必须要三个实例呢?我们先看看两个哨兵会咋样。
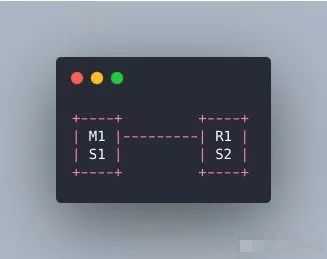
master宕机了,S1 和 S2 两个哨兵只要有一个认为你宕机了就切换了,并且会选举一个哨兵去执行故障,但是这个时候也需要大多数哨兵都是运行的。
那这样有啥问题呢?M1宕机了,S1没有挂,这是OK的,但是整个机器都挂了呢?哨兵就剩下S2个光杆司令了,没有哨兵去允许故障转移了,虽然另外一个机器上还有R1,但是故障转移就是不执行。
经典的哨兵集群是这样的:
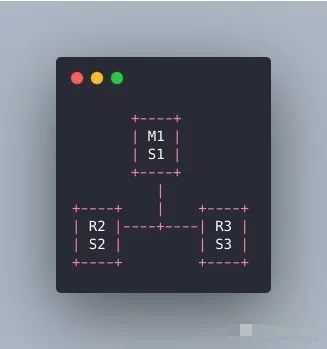
M1所在的机器挂了,哨兵还有两个,两个人一看M1挂了,那我们就选举一个出来执行故障转移不就行了嘛。
简单总结下哨兵组件的主要功能:
答:提到这个,就跟我前面提到的数据持久化的 RDB 和 AOF 有着密切的关系了。
我先说说为什么要用主从这样的架构模式,前面提到了单机 QPS 是有上限的,而且Redis的特性就是必须支撑读高并发的,那你一台机器又读又写,就算是机器也扛不住啊。但是你让这个 master 机器去写,数据同步给别的 slave 机器,他们都拿去读,分发掉大量的请求那就会好很多,而且扩容的时候还可以轻松实现水平扩容。
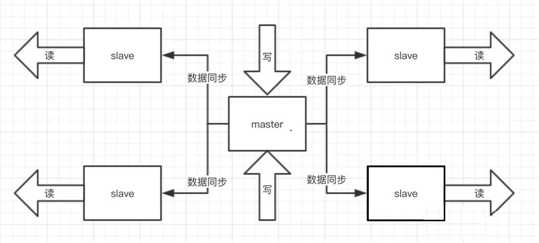
回归正题,他们的数据是怎么同步的呢?
你启动了一台 slave 的时候,他会发送一个 psync 命令给 master,如果是这个 slave 第一次连接到 master,他会触发一个全量复制。master 就会启动一个线程,生成 RDB快照,还会把新的写请求都缓存在内存中,RDB文件生成后,master 会将这个 RDB 发送给 slave 的,slave 拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,然后 master 会把内存里面的缓存的那些新命名都发给 slave。
答:传输过程中有什么网络问题的,会自动重连的,并且连接之后会把缺少的数据不上。
Tip:大家需要记住的是,RDB快照的数据生成的时候,缓存区也必须同时开始接受新请求,不然你旧的数据过去了,你在同步期间的增量数据咋办?对吧?
答:Redis 的过期策略,是有定期删除和惰性删除两种。
定期删除好理解,就是默认100s就随机抽取一些设置了过期时间的key,去检查是否过期,过期了就删除。
答:假如Redis里面所有的key都有过期时间,再全扫描一遍?这太恐怖了,而且我们线上基本上都会设置一定的过期时间。全扫描就跟你去查数据库不带where条件、不走索引全表扫描一样,100s一次,会给 CPU 带来很大的负载!
答:这就回到刚才说的惰性删除了。见名知意,惰性嘛,就是我不主动删,我懒,我等你来查询了,再看看你过期了没,过期就删除还不给你返回,没过期该怎样就怎样。
答:如果过期就删除,假设Redis里放了10万个key,都设置了过期时间,你每隔几把毫秒,就检查10万个key,那Redis基本上就死了,CPU负载会很高的,基本都消耗在你的检查过期key上。
但是问题是,定期删除可能回导致很多过期key到了时间并没有被删除掉,那应该怎么处理呢?所以就有了惰性删除了。这就是说,在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间,那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
并不是key到了时间就被删除,而是你查询这个key的时候,redis再懒惰地检查一下。
通过上述两种手段结合起来,保证过期的key一定会被删除。
所以说,用了上述2种策略后,这种现象就不难解释了:数据明明都过期了,但是还占着内存。
答:会出现大量的key堆积在内存里,导致redis内存很快耗尽。使用redis内存淘汰机制解决这个问题。
可能有的小伙伴遇到过这种情况,放在redis中的数据怎么没了?
因为Redis将数据放到内存中,内存时有限的,比如redis就只能用10个G,你要是忘里面写了20G的数据,会出现什么情况?当然是会干掉10个G的数据,然后保留10个G的数据了。那干掉哪些数据?保留哪些数据?当然时干掉不常用的数据,保留常用的数据了。
Redis提供了6中数据淘汰策略:
原文:https://www.cnblogs.com/qiuhaitang/p/11899662.html