字典是python中唯一一个映射数据类型。
不可变数据类型:元组,bool值,int,可hash。元组,只可查,可循环,切片,更改条件:子不可改,孙可能可以改。
可变数据类型:list,dict,set(集合) 不可hash。
dict:key必须是不可变数据类型,可hash。
value:任意数据类型。
dict 优点:二分查找去查询。
储存大量的关系型数据。
特点:无序,只针对3.5及以前,以后排序。
建立字典
eg:
dic={ ‘name‘:[‘eric‘,‘eric_one‘], ‘py‘:[{‘num‘:71,‘avg_age‘:18,}], True:1, (1,2,3):‘wuyiyi‘, 2:‘儿子‘ } print(dic)
dic1={‘age‘:18,‘name‘:‘jin‘,‘sex‘:‘male‘,}
1> 增
dic1[‘height‘]=185#有则覆盖,没有则添加 dic1.setdefault(‘weight‘,140)#用的比较少 #二者区别:有key_value对不覆盖,没有才添加 print(dic1) dic1.setdefault(key,default=none)
2> 删
dic1.pop(‘age‘)有返回值,按键去删除,如果没有这个键,报错 dic1.pop(‘111‘,None),当没有时,会打印‘None‘,可设置返回值 dic1.popitem()#有返回值(元组类型键值),(随机删除3.5以前,3.6以后删最后一个) dic1.clear()#清空键值对 print(dic1)
3> 改 update
dic1[‘height‘]=185 dic={‘name‘:‘jin‘,‘age‘:18,‘sex‘:‘male‘} dic2={‘name‘,‘alex‘,‘weight‘:75} dic2.update(dic) #用dic将dic2的键值没有的添加进来,有的覆盖掉
4> 查
print(dic1[‘height‘])#打印它的值,如果字典中没有会报错 print(dic1.get(‘name1‘,default=None))#如果没有,不会报错,输出None print(dic1.keys(),type(dic1.keys()))#对应键列表 print(dic1.values())#对应值列表 print(dic1.items())#列表→元组→键值对
示例代码:
#循环打印键 for i in dic1: print(i) for i in dic1.keys(): print(i) #打印值 for i in dic1.values(): print(i) a,b=1,2 a,b=[1,2] a,b=(1,2) a,b=[1,2],[2,3] #只打印对应的键值 for k,v in dic1.items(): print(k,v) dic1={‘name‘:[‘alex‘,‘wusir‘,‘taibai‘], ‘py9‘:{ ‘time‘:‘1213‘, ‘learn_money‘:19800, ‘addr‘:‘CBD‘, }, ‘age‘:21 }
| python2 | python3 |
| print() print ‘abc‘ | print(‘abc‘) |
| range() xrange() 生成器 | range() |
| raw_input() | input() |
1.数字的范围: -5 - 256
2.字符串:1> 不能有特殊字符。
2> s*20 还是同一个地址,s*21以后都是两个地址。
3.剩下的 list dict tuple set均无小数据池概念。
i1 = 6 i2 = 6 print(id(i1),id(i2)) i1 = 300 i2 = 300 print(id(i1),id(i2))
= 赋值, == 比较值是否相等 is 比较,比较的是内存地址 id(内容) li1 = [1,2,3] li2 = li1 li3 = li2 print(id(li1),id(li2))
l1 = [1,] l2 = [1,] print(l1 is l2)
s = ‘eric‘ s1 = b‘eric‘ print(s,type(s)) print(s1,type(s1)) s = ‘中国‘ print(s,type(s)) s1 = b‘中国‘ print(s1,type(s1)) s1 = ‘eric‘ #encode 编码,如何将str --> bytes, () s11 = s1.encode(‘utf-8‘) s11 = s1.encode(‘gbk‘) print(s11) s2 = ‘中心‘ s22 = s2.encode(‘utf-8‘) s22 = s2.encode(‘gbk‘) print(s22)
1.有如下变量(tu是个元组),请实现要求功能
tu=(‘alex‘,[11,22,{‘k1‘:‘v1‘,‘k2‘:[‘age‘,‘name‘],‘k3‘:(11,22,33)},44])
a.讲述元组特性
b.请问tu变量中的第一个元素‘alex‘是否可被修改?
c.请问tu变量中的‘k2‘对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素‘seven‘.
d.请问tu变量中的‘k3‘对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素‘seven‘.
2.字典dic,dic={"k1":"v1","k2":"v2","k3":[11,22,33]}
a.请循环输出所有的key
b.请循环输出所有的value
c.请循环输出所有的key和value
d.请在字典中添加一个键值对"k4":"v4",输出添加后的字典
e.请在修改字典中"k1",对应的值为"alex",输出修改后的字典
f.请在k3对应的值中追加一个元素44,输出修改后的字典
g.请在k3对应的值的第1个位置插入个元素18,输出修改后的字典
3.元素分类
有如下值li=[11,22,33,44,55,66,77,88,99,90],将所有大于66的值保存至字典的第一个key中,将小于66得知保存至第二个key的值中
即:{"k1":大于66的所有值列表,"k2":大于66的所有值列表}
4.输出商品列表,用户输入序号,显示用户选中的商品。
商品:li=["手机","电脑","鼠标垫","游艇"]
要求: 1.页面显示 序号+商品名称,如:
1 手机
2 电脑
2.用户输入选择的商品序号,然后打印商品名称。
3.如果用户输入的商品序号有误,则提示输入错误,并重新输入
4.用户输入"Q"或"q",退出程序
5.简易购物车实现。
6.模拟Hr输入员工用户名及密码,如下形式,若用户名输入为"q"或"Q",则退出程序。若碰到board中的非法字符时,根据非法字符个数,用“*”代替,但仍需要保存在就直
接添加到user_list中里,如果没有,直接添加到user_list中。
1. a.儿不可改,孙可改,不可变数据类型 b.不可修改 c.列表类型,可修改,tu[1][2]["k2"].append("seven") d.元组类型,不可改
2. for i in dic.keys(): print(i) for i in dic.values(): print(i) for i in dic.items(): print(i) dic["k4"]="v4" print(dic) dic["k1"]="alex" print(dic) dic={"k1":"v1","k2":"v2","k3":[11,22,33]} dic1={"k3":[11,22,33,44]} dic.update(dic1) print(dic) dic={"k1":"v1","k2":"v2","k3":[11,22,33]} dic1={"k3":[18,11,22,33]} dic.update(dic1) print(dic)
3.给出的程序只有: li=[11,22,33,44,55,77,88,99,90] result={} for row in li: #法1 li=[11,22,33,44,55,77,88,99,90] result={} for row in li: if int(row)>66: if ‘key1‘ not in result: result[‘key1‘]=[] result[‘key1‘].append(row) else: if ‘key2‘ not in result: result[‘key2‘]=[] result[‘key2‘].append(row) print(result) #法2 li=[11,22,33,44,55,77,88,99,90] result={} for row in li: result.setdefault(‘key1‘,[]) result.setdefault(‘key2‘,[]) if row>66: result[‘key1‘].append(row) else: result[‘key2‘].append(row) print(result) #法3(不符合程序初始给出要求,但结果实现) li=[11,22,33,44,55,66,77,88,99,90] dic={} l_bigger=[]#存储大于66的所有值的列表 l_small=[]#存储小于66的所有值的列表 for i in li: if i==66:continue if i>66: l_bigger.append(i) else: l_small.append(i) dic.setfault(‘k1‘,l_bigger) #dic.append(‘k1‘)=l_bigger dic.setfault(‘k2‘,l_small) #dic.append(‘k2‘)=l_small print(dic)
4. li=["手机","电脑","鼠标垫","游艇"] length=len(li) for i in li: print(‘{}\t{}‘.format(li.index(i)+1,i)) length -= 1 while 1: user_input=input("请输入序号:").strip() if user_input.isalpha(): if user_input.upper()=="Q": break elif user_input.isdigit(): if int(user_input)<len(li)+1: print(int(user_input),li[int(user_input)-1]) else: print("输入有误,请重新输入")
5. li=[{"name":"苹果","price":10}, {"name":"香蕉","price":20}, {"name":"西瓜","price":30}] shopping_car={} money=input("请输入你的金额:") if money.isdigit() and int(money)>0: while 1: for i,k in enumerate(li): print("序号{}\t商品{}\t价格{}".format(i,k["name"],k["price"])) choose_food=input("请输入所需商品的序号:") if choose_food.isdigit() and int(choose_food) < len(li): choose_num=input("请输入所需数量:") if choose_num.isdigit() and int(choose_num)>=0: if int(money)>=li[int(choose_food)]["price"]*int(choose_num): money=int(money)-li[int(choose_food)]["price"]*int(choose_num) if li[int(choose_food)]["name"] in shopping_car: shopping_car[li[int(choose_food)]["name"]]=shopping_car[li[int(choose_food)]["name"]]+int(choose_num) else: shopping_car[li[int(choose_food)]["name"]]=int(choose_num) print("你所选择的商品是{}\t余额为{}".format(shopping_car,money)) else: print("您的余额不足!") break else: print("请输入序号选择对应商品!")
删除字典中带‘k‘的键值对 第一种: dic={"k1":"v1","k2":"v2","a3":"v3"} l=[] for i in dic: if "k" in i: l.append(i) for i in l: del dic[i] print(dic) 第二种: dic={"k1":"v1","k2":"v2","a3":"v3"} dic1={} for i in dic: if "k" not in i: dic1.setdefault(i,dic[i]) dic=dic1 print(dic)
6. ##user_list=[ ## {‘username‘:‘barry‘,‘password‘:‘1234‘}, ## {‘username‘:‘alex‘,‘password‘:‘asdf‘}, ## ] ##board=[‘张三‘,‘李四‘,‘王二麻子‘] user_list=[] board=[‘张三‘,‘李四‘,‘王二麻子‘] while 1: usn=input("请输入用户名:") if usn.upper()==‘Q‘: break else: pwd=input("请输入密码:") for i in board: if i in usn: usn=usn.replace(i,‘*‘*len(i)) user_list.append({"username":usn,"password":pwd}) print({"username":usn,"password":pwd}) print(user_list)
可变数据类型,里面的数据类型必须是不可变数据类型,无序,不重复,列表转化为集合则可自动去重。
set1 = set({1,2,3})
set2 = {1,2,3,[2,3],{‘name‘:‘alex‘}} # 错的
print(set1)
print(set2)
set1 = {‘alex‘,‘wusir‘,‘ritian‘,‘egon‘,‘barry‘,}
1.add set1.add(‘女神‘) print(set1) 2.update set1.update(‘abc‘) print(set1)
1. set1.pop() # 随机删除 print(set1.pop()) # 有返回值 print(set1) 2.set1.remove(‘alex‘) # 按元素 print(set1) 3.set1.clear()#清除 print(set1) #集合与元组class的区分 set() 4.del set1 print(set1)
for i in set1: print(i)
1.交(∩)
set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 & set2) print(set1.intersection(set2)) # {4, 5} 2.并(∪) set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 | set2) print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7,8} 3.差分 set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 ^ set2) print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8} 4.差集 set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 - set2) #set1独有的 print(set1.difference(set2)) # {1, 2, 3} 5.子集|超集 set1 = {1,2,3,} set2 = {1,2,3,4,5,6} print(set1 < set2) print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。 print(set2 > set1) print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
6.去重
li = [1,2,33,33,2,1,4,5,6,6]
set1 = set(li)
# print(set1)
li = list(set1)
print(li)
s1 = {1,2,3}#集合数据类型
print(s1,type(s1))
s = frozenset(‘barry‘)#数据类型:可变→不可变
print(s,type(s))
#只能查
for i in s:
print(i)
1.rb
f = open(‘儿子老爹小孩子‘,mode=‘rb‘,) content = f.read() print(content) f.close()
2.r+
f = open(‘log‘,mode=‘r+‘,encoding=‘utf-8‘) print(f.read()) f.close()
3.r+b
f = open(‘log‘,mode=‘r+b‘) print(f.read()) f.write(‘大猛,小孟‘.encode(‘utf-8‘)) f.close()
4.r(bytes ---->str)
f = open(‘儿子老爹小孩子‘,mode=‘r‘,encoding=‘utf-8‘) content = f.read() f.write(‘fjsdlk‘) f.close()
5.对于w:没有此文件就会创建文件.
f = open(‘log‘,mode=‘w‘,encoding=‘utf-8‘) f.write(‘骑兵步兵‘) f.close()
6.w(先将源文件的内容全部清除,在写。)
f = open(‘log‘,mode=‘w‘,encoding=‘utf-8‘) f.write(‘附近看到类似纠纷‘) f.close()
7.w+
f = open(‘log‘,mode=‘w+‘,encoding=‘utf-8‘) f.write(‘aaa‘) f.seek(0) print(f.read()) f.close()
8.wb
f = open(‘log‘,mode=‘wb‘) f.write(‘附近看到类似纠纷‘.encode(‘utf-8‘)) f.close()
9.a(追加)
f = open(‘log‘,mode=‘a‘,encoding=‘utf-8‘) f.write(‘佳琪‘) f.close()
10.a+
f = open(‘log‘,mode=‘a+‘,encoding=‘utf-8‘) f.write(‘佳琪‘) f.seek(0) print(f.read()) f.close()
11.ab
f = open(‘log‘,mode=‘ab‘) f.write(‘佳琪‘.encode(‘utf-8‘)) f.close()
12.功能详解
obj = open(‘log‘,mode=‘r+‘,encoding=‘utf-8‘) content = f.read(3) # 读出来的都是字符 f.seek(3) # 是按照字节定光标的位置 f.tell() 告诉你光标的位置 print(f.tell()) content = f.read() print(content) f.tell() f.readable() # 是否刻度 line = f.readline() # 一行一行的读 line = f.readlines() # 每一行当成列表中的一个元素,添加到list中 f.truncate(4) for line in f: print(line) f.close()
13.调节光标、读取指定字符
f = open(‘log‘,mode=‘a+‘,encoding=‘utf-8‘) f.write(‘佳琪‘) count = f.tell()#获取光标位置 f.seek(count-9)#将光标定位到倒数第9个字节 print(f.read(2))#读取2个字符 f.close()
14.打开多个文件
with open(‘log‘,mode=‘r+‘,encoding=‘utf-8‘) as f, open(‘log‘,mode=‘w+‘,encoding=‘utf-8‘) as f1:
15.修改文件内部
# 修改文件 with open(‘小小子‘,encoding=‘utf-8‘) as f,open(‘小小子.bak‘,‘w‘,encoding=‘utf-8‘) as f2: for line in f: if ‘星儿‘ in line: line = line.replace(‘星儿‘,‘阿娇‘) f2.write(line) import os os.remove(‘小小子‘) #删除文件 os.rename(‘小小子.bak‘,‘小小子‘) #重命名文件
username=input("请输入需要注册的用户名:") password=input("请输入需要注册的密码:") with open("file_of_info",mode="w",encoding="utf-8") as f: f.write("{}\n{}".format(username,password)) print("恭喜你注册成功!") li=[]#文件读取到的用户名、密码 i=0 while i<3: usn=input("请输入需要登录的用户名:") pwd=input("请输入需要登录的密码:") with open("file_of_info",mode="r+",encoding="utf-8") as f1: for line in f1: li.append(line) if usn==li[0].strip() and pwd==li[1].strip() : print("恭喜你登陆成功") break else: print(",账户密码错误,请重新登陆!") i+=1
#str --->byte encode 编码 s = ‘儿子‘ b = s.encode(‘utf-8‘) print(b) #byte --->str decode 解码 s1 = b.decode(‘utf-8‘) print(s1) s = ‘abf‘ b = s.encode(‘utf-8‘) print(b) #byte --->str decode 解码 s1 = b.decode(‘gbk‘) print(s1)
可方便调用的,具有一定功能。
1.返回值
返回值的3种情况
没有返回值 —— 返回None
不写return
只写return:结束一个函数的继续
return None —— 不常用
返回1个值
可以返回任何数据类型
只要返回就可以接收到
如果在一个程序中有多个return,那么只执行第一个
返回多个值
用多个变量接收:有多少返回值就用多少变量接收
用一个变量接收: 得到的是一个元组
def func(): l = [‘儿子‘,‘二哥‘] for i in l: print(i) if i==‘儿子‘: return None print(‘=‘*10) ret = func() print(ret) def func(): return {‘k‘:‘v‘} print(func()) def func2(): return 1,2,3 #return 1,2,3 r= func2() print(r)
2.参数
1> 没有参数:定义函数和调用函数时括号里都不写内容。
2> 有一个参数:传什么就是什么。
3> 有多个参数:位置参数。
def my_sum(a,b): print(a,b) res = a+b #result return res ret = my_sum(1,2) print(ret)
3.站在实参的角度上:
1> 按照位置传参。
2> 按照关键字传参。
3> 混着用可以:但是必须先按照位置传参,再按照关键字传参数。不能给同一个变量传多个值。
4.站在形参的角度上:
1> 位置参数:必须传,且有几个参数就传几个值。
2> 默认参数: 可以不传,如果不传就是用默认的参数,如果传了就用传的。
def classmate(name,sex=‘男‘): print(‘%s : %s‘%(name,sex)) classmate(‘大哥‘) classmate(‘二哥‘) classmate(‘三哥‘) classmate(‘小女‘,‘女‘)
5.只有调用函数的时候:
1> 按照位置传 : 直接写参数的值。
2> 按照关键字: 关键字 = 值。
6.定义函数的时候:
1> 位置参数 : 直接定义参数。
2> 默认参数,关键字参数 :参数名 = ‘默认的值‘。
3> 动态参数 : 可以接受任意多个参数。
参数名之前加*,习惯参数名args。
参数名之前加**,习惯参数名kwargs。
4> 顺序:位置参数,*args,默认参数,**kwargs。
1.关键字
def classmate(name,sex): print(‘%s : %s‘%(name,sex)) classmate(‘小弟‘,‘男‘) classmate(sex=‘男‘,name = ‘小弟‘) 2.默认参数,可通过实际传值进行更改 def classmate(name,sex=‘男‘): print(‘%s : %s‘%(name,sex)) classmate(‘小弟‘) classmate(‘小女孩‘,sex= ‘女‘) 3.位置传参 def sum(*args): n = 0 for i in args: n+=i return n print(sum(1,2)) print(sum(1,2,3)) print(sum(1,2,3,4)) 4.关键字传参 def func(**kwargs): print(kwargs) func(a = 1,b = 2,c =3) func(a = 1,b = 2) func(a = 1)
7.动态参数有两种:可以接受任意个参数
1> *args : 接收的是按照位置传参的值,组织成一个元组。
2> **kwargs: 接受的是按照关键字传参的值,组织成一个字典。
注意:args必须在kwargs之前。
def func(*args,default = 1,**kwargs): print(args,kwargs) func(1,2,3,4,5,default=2,a = ‘aaaa‘,b = ‘bbbb‘,)
8.动态参数的另一种传参方式(*****************)
def func(*args):#站在形参的角度上,给变量加上*,就是组合所有传来的值。 print(args) func(1,2,3,4,5) l = [1,2,3,4,5] func(*l) #站在实参的角度上,给一个序列加上*,就是将这个序列按照顺序打散 def func(**kwargs): print(kwargs) func(a=1,b=2) d = {‘a‘:1,‘b‘:2} #定义一个字典d func(**d)
9.函数的注释
def func(): ‘‘‘ 这个函数实现了什么功能 参数1: 参数2: :return: 是字符串或者列表的长度 ‘‘‘ pass
10.函数嵌套
内部函数可以使用外部函数的变量。
def f2(l1): f1(l1) for i in l1: print(i) def f1(l1): for i in l1: print(i) f2([1,2,3,4])
def max(a,b): return a if a>b else b def the_max(x,y,z): #函数的嵌套调用 c = max(x,y) return max(c,z) print(the_max(1,2,3)) a = 1 def outer(): a = 1 def inner(): a = 2 def inner2(): nonlocal a #声明了一个上面第一层局部变量 a += 1 #不可变数据类型的修改 inner2() print(‘##a## : ‘, a) inner() print(‘**a** : ‘,a) outer() print(‘全局 :‘,a)
11.函数的命名空间
1.命名空间有三种:
1>.内置命名空间 —— python解释器
就是python解释器一启动就可以使用的名字存储在内置命名空间中。
内置的名字在启动解释器的时候被加载进内存里。
2>.全局命名空间 —— 我们写的代码但不是函数中的代码
是在程序从上到下被执行的过程中依次加载进内存的。
放置了我们设置的所有变量名和函数名。
3>.局部命名空间 —— 函数
就是函数内部定义的名字。
当调用函数的时候才会产生这个名称空间随着函数执行的结束,这个命名空间就又消失了。
2.名字使用
1> 在局部:可以使用全局、内置命名空间中的名字
2> 在全局:可以使用内置命名空间中的名字,但是不能用局部中使用
3> 在内置:不能使用局部和全局的名字的
注:1> 在正常情况下,直接使用内置的名字,当我们在全局定义了和内置名字空间中同名的名字时,会使用全局的名字。
2> 当我自己有的时候 我就不找我的上级要了。如果自己没有,就找上一级要, 上一级没有再找上一级。如果内置的名字空间都没有就报错。
3> 多个函数应该拥有多个独立的局部名字空间,不互相共享。
3.func --> 函数的内存地址
函数名() 函数的调用。
函数的内存地址() 函数的调用。
12.作用域
1> 全局作用域 —— 作用在全局 —— 内置和全局名字空间中的名字都属于全局作用域 ——globals()。
2> 局部作用域 —— 作用在局部 —— 函数(局部名字空间中的名字属于局部作用域) ——locals()。
3> nonlocal 只能用于局部变量 找上层中离当前函数最近一层的局部变量。
注:1> 对于不可变数据类型 在局部可是查看全局作用域中的变量,但是不能直接修改。 如果想要修改,需要在程序的一开始添加global声明。 如果在一个局部(函数)内
2> 声明了一个global变量,那么这个变量在局部的所有操作将对全局的变量有效。
3> 声明了nonlocal的内部函数的变量修改会影响到 离当前函数最近一层的局部变。对全局无效。对局部也只是对最近的一层有影响。
a = 1 b = 2 def func(): x = ‘aaa‘ y = ‘bbb‘ print(locals()) print(globals()) func() print(globals()) print(locals()) #本地的 globals 永远打印全局的名字 locals 输出什么 根据locals所在的位置
13.函数名
1> 函数名就是内存地址。
2> 函数名可以赋值。
3> 函数名可以作为容器类型的元素。
4> 函数名可以作为函数的返回值。
5> 函数名可以作为函数的参数。
def func(): print(123) # func() #函数名就是内存地址 func2 = func #函数名可以赋值 func2() l = [func,func2] #函数名可以作为容器类型的元素 print(l) for i in l: i() def func(): print(123) def wahaha(f): f() return f #函数名可以作为函数的返回值 qqxing = wahaha(func) # 函数名可以作为函数的参数 qqxing()
14.习题
1.阅读代码,给出a,b,c的值
1> a=10 b=20 def test(a,b): print(a,b) c=test(b,a) print(c) 2> a=10 b=20 def test(a,b): a=3 b=5 print(a,b) c=test(b,a) print(c)
2.计算字符串中数字、字母、空格、其他等。
结果如下:
1>: 20 10 None 2>: 3 5 None
2. def count(s): dic={"num":0,"alpha":0,"space":0,"other":0} for i in s: if i.isdigit(): dic[‘num‘] += 1 elif i.isalpha(): dic[‘alpha‘] += 1 elif i.isspace(): dic[‘space‘] += 1 else: dic[‘other‘] +=1 return dic
测试输入: s=‘123 456dgfhhe sf **‘ print(count(s))
嵌套函数,内部函数调用外部函数的变量。
def outer(): a = 1 def inner(): print(a) inner() outer()
def outer(): a = 1 def inner(): print(a) return inner inn = outer() inn()
import urllib #模块 from urllib.request import urlopen ret = urlopen(‘http://www.xiaohua100.cn/index.html‘).read() print(ret) def get_url(): url = ‘http://www.xiaohua100.cn/index.html‘ ret = urlopen(url).read() print(ret) get_url() def get_url(): url = ‘http://www.xiaohua100.cn/index.html‘ def get(): ret = urlopen(url).read() print(ret) return get get_func = get_url() get_func()
1.装饰器形成的过程 : 最简单的装饰器 有返回值的 有一个参数 万能参数。
2.装饰器的作用:不想修改函数的调用方式 但是还想在原来的函数前后添加功能。
timmer就是一个装饰器函数,只是对一个函数 有一些装饰作用。
3.原则:开放封闭原则。
1> 开放:对扩展是开放的。
2> 封闭:对修改是封闭的。
4.语法糖 :@
5.装饰器的固定模式。
6.完美装饰器。
7.带参数装饰器。
8.多个装饰器装饰一个函数。
9.习题。
先学知识:
import time print(time.time())#获取当前时间
1> 最简单装饰器
import time def func(): time.sleep(0.01) print("你好呀")
def timer(f): #装饰器函数 def inner(): start=time.time() f() #被装饰函数 end=time.time() print(end-start) return inner func=timer(func) func()
2> 带返回值的
import time def timer(f): #装饰器函数 def inner(): start=time.time() ret=f() #被装饰函数 end=time.time() print(end-start) return ret return inner @timer #语法糖 装饰器函数名 def func(): #被装饰的函数 time.sleep(0.01) print("你好呀")
return ‘新年好‘ ret=func() print(ret)
3> 带一个参数的装饰器
import time def timer(f): #装饰器函数 def inner(a): start=time.time() ret=f(a) #被装饰函数 end=time.time() print(end-start) return ret return inner @timer #语法糖 装饰器函数名 def func(a): #被装饰的函数 time.sleep(0.01) print("你好呀",a) return ‘新年好‘ ret=func(1) print(ret)
4> 万能的装饰器
import time def timer(f): #装饰器函数 def inner(*args,**kwargs): start=time.time() ret=f(*args,**kwargs) #被装饰函数 end=time.time() print(end-start) return ret return inner @timer def func(a,b): time.sleep(0.01) print("你好呀",a,b) return ‘新年好‘ @timer def func1(a): time.sleep(0.01) print("你好呀",a) return ‘新年好‘ ret=func(1,2) ret=func(1,b=2) print(ret)
5> 装饰器的固定形式
def wrapper(f): #装饰器函数,f为被装饰的函数 def inner(*args,**kwargs): ‘‘‘被装饰函数之前要做的事‘‘‘ ret=f(*args,**kwargs) #被装饰函数 ‘‘‘被装饰函数之后要做的事‘‘‘ return ret return inner @wrapper def func(a,b): time.sleep(0.01) print("你好呀",a,b) return ‘新年好‘
6> 完美装饰器

from functools import wraps def wrapper(func): #func = holiday @wraps(func) def inner(*args,**kwargs): print(‘在被装饰的函数执行之前做的事‘) ret = func(*args,**kwargs) print(‘在被装饰的函数执行之后做的事‘) return ret return inner @wrapper #holiday = wrapper(holiday) def holiday(day): ‘‘‘这是一个放假通知‘‘‘ print(‘全体放假%s天‘%day) return ‘好开心‘ print(holiday.__name__) print(holiday.__doc__) ret = holiday(3) #inner print(ret)
注:print(wahaha.__name__) #查看字符串格式的函数名。
print(wahaha.__doc__) #document。
7> 带参数装饰器
@wrapper→@wrapper(argument)三层 嵌套函数 def outer(形参) : def wrapper(func): @wraps(func) def inner(*args,**kwargs): ‘‘‘被装饰函数之前的函数处理‘‘‘ ret=func(*args,**kwargs) ‘‘‘被装饰函数之后的函数处理‘‘‘ return ret return inner @outer(实参)
#应用于多个函数时,可通过参数来指定哪些程序开放执行 import time FLAGE = False def timmer_out(flag): def timmer(func): def inner(*args,**kwargs): if flag: start = time.time() ret = func(*args,**kwargs) end = time.time() print(end-start) return ret else: ret = func(*args, **kwargs) return ret return inner return timmer # timmer = timmer_out(FLAGE) @timmer_out(FLAGE) #wahaha = timmer(wahaha) def wahaha(): time.sleep(0.1) print(‘wahahahahahaha‘) @timmer_out(FLAGE) def xiaoxiaozi(): time.sleep(0.1) print(‘xiaoxiaozizizi‘) wahaha() xiaoxiaozi()
8> 多个装饰器装饰一个函数
@wrapper1 @wrapper2 装饰器先执行wrapper 2 在装饰函数之前的语句:先执行wrapper1中的。 在装饰函数之后的语句:先执行wrapper2中的。
def wrapper1(func): def inner1(): print(‘wrapper1 ,before func‘) ret = func() print(‘wrapper1 ,after func‘) return ret return inner1 def wrapper2(func): def inner2(): print(‘wrapper2 ,before func‘) ret = func() print(‘wrapper2 ,after func‘) return ret return inner2 def wrapper3(func): def inner3(): print(‘wrapper3 ,before func‘) ret = func() print(‘wrapper3 ,after func‘) return ret return inner3 @wrapper3 @wrapper2 @wrapper1 def f(): print(‘in f‘) return ‘哈哈哈‘ print(f()
9.习题
1.编写装饰器,为多个函数加上认证的功能,用户的账号和密码来源于文件。要求登陆成功一次,后续的函数都无须再输入用户名和密码。
2.编写装饰器,为多个函数加上记录调用功能,要求每次调用函数都将被调用的函数名称写入文件。
进阶作业:
1.编写下载网页内容的函数,要求功能是:用户传入一个url,函数返回下载页面的结果。
2.为题目1编写装饰器,实现缓存网页内容的功能。
具体:实现下载的页面存放于文件中,如果文件内有值(文件大小不为0),就优先从文件中读取网页内容,否则就去下载。
具体参考代码如下:
flag=False def wrapper(func): def inner(*args,**kwargs): global flag # if flag: ret=func(*args,**kwargs) return ret else: while 1: username=input("请输入用户名:") password=input("请输入密码:") li=[] with open("zhmm.txt",mode="r+",encoding="utf-8") as f: for line in f: li.append(line) if username==li[0].strip(‘\n‘) and password==li[1].strip(‘\n‘): print("登陆成功") flag=True ret=func(*args,**kwargs) return ret break else: print("密码错误,请重新登陆!") return inner @wrapper def f1(): print("123") @wrapper def f2(): print("456") f1() f2()
def decor(func): def inner(*args,**kwargs): with open(‘log‘,‘a‘,encoding=‘utf-8‘) as f: f.write(func.__name__+"\n") func(*args,**kwargs) return inner @decor def f1(): print("f1") @decor def f2(): print("f2") @decor def f3(): print("f3") f1() f2() f3() f2()
def get_webContent(url): html_sourceCode=urlopen(url).read() return html_sourceCode ret=get_webContent(‘http://www.baidu.com‘) print(ret) import os from urllib.request import urlopen def cache(func): def inner(*args,**kwargs): if os.path.getsize(‘web_content‘):#文件大小不为0时 with open(‘web_content‘,‘rb‘) as f: return f.read() ret=func(*args,**kwargs) with open("web_content",‘wb‘) as f: f.write(b‘****‘+ret) return ret return inner @cache def get_webContent(url): html_sourceCode=urlopen(url).read() return html_sourceCode ret=get_webContent(‘http://www.baidu.com‘) print(ret) ret=get_webContent(‘http://www.baidu.com‘) print(ret) ret=get_webContent(‘http://www.baidu.com‘) print(ret)
很少直接调用的方法,一般情况下,是通过其他方法触发的。
#简单的求和操作 print([1].__add__([2])) print([1]+[2])
1> 可迭代协议:含有__iter__方法。
#打印列表拥有的所有方法 print(dir([])) ret = set(dir([]))&set(dir({}))&set(dir(‘‘))&set(dir(range(10))) print(ret) #iterable,判断共有的方法
2> 判断迭代的方法:‘__iter__‘ in dir(数据类型)。
#判断数据类型中是否有__iter__()方法 print(‘__iter__‘ in dir(int)) print(‘__iter__‘ in dir(bool)) print(‘__iter__‘ in dir(list)) print(‘__iter__‘ in dir(dict)) print(‘__iter__‘ in dir(set)) print(‘__iter__‘ in dir(tuple)) print(‘__iter__‘ in dir(enumerate([]))) print(‘__iter__‘ in dir(range(1)))
3> 可迭代的一定可以被for循环。
#只要是能被for循环的数据类型 就一定拥有__iter__方法 print([].__iter__()) #一个列表执行了__iter__()之后的返回值就是一个迭代器 print(dir([])) print(dir([].__iter__())) print(set(dir([].__iter__())) - set(dir([])))#差分 print([1,‘a‘,‘bbb‘].__iter__().__length_hint__())#元素个数 l = [1,2,3] iterator = l.__iter__() print(iterator.__next__()) print(iterator.__next__()) print(iterator.__next__()) print(iterator.__next__())
1> 含有__iter__和__next__方法。
print(‘__iter__‘ in dir( [].__iter__())) print(‘__next__‘ in dir( [].__iter__())) from collections import Iterable from collections import Iterator print(isinstance([],Iterator)) print(isinstance([],Iterable)) class A: # def __iter__(self):pass def __next__(self):pass a = A() print(isinstance(a,Iterator)) print(isinstance(a,Iterable))
2> 迭代器一定可迭代,可迭代的不一定是迭代器。
3> 可迭代的通过调用__iter__()方法就可以得到迭代器。
1>方便使用,且只能取所有的数据取一次。
2>节省内存空间。
1> 可以被for循环的都是可迭代的。
2> 可迭代的内部都有__iter__方法。
3> 只要是迭代器一定可迭代。
4> 可迭代的.__iter__()方法就可以得到一个迭代器。
5> 迭代器中的__next__()方法可以一个一个的获取值。
注:1> 只有是可迭代对象的时候 才能用for。
2> 当我们遇到一个新的变量,不确定能不能for循环的时候,就判断它是否可迭代。
for i in l: pass iterator = l.__iter__() iterator.__next__()
1. 从容器类型中一个一个的取值,会把所有的值都取到。
2. 节省内存空间。
3. 迭代器并不会在内存中再占用一大块内存,而是随着循环每次生成一个。每次next每次给我一个。
1.本质就是迭代器。只要含有yield关键字的函数都是生成器函数。执行之后会得到一个生成器作为返回值。
2.生成器的表现形式。
1>生成器函数:含有yield关键字的函数就是生成器函数。
1.1>特点:
调用函数的之后函数不执行,返回一个生成器。
每次调用next方法的时候会取到一个值。
直到取完最后一个,在执行next会报错。
2>生成器表达式。
3.从生成器中取值的几个方法。
1> next。
2> for。
3> 数据类型的强制转换 : 占用内存。
4.send 获取下一个值的效果和next基本一致。
1> 只是在获取下一个值的时候,给上一yield的位置传递一个数据。
2> 使用send的注意事项:
第一次使用生成器的时候 是用next获取下一个值。
最后一个yield不能接受外部的值 。
5.生成器的表达式。
6.各种推导式。
1> [每一个元素或者是和元素相关的操作 for 元素 in 可迭代数据类型] #遍历之后挨个处理
2> [满足条件的元素相关的操作 for 元素 in 可迭代数据类型 if 元素相关的条件] #筛选功能
3> 列表推导式。
4> 字典推导式。
5> 集合推导式,自带结果去重功能。
注:yield不能和return共用且需要写在函数内。
1> 生成器函数
def generator(): print(1) yield ‘a‘ ret = generator()#返回一个生成器 print(ret) print(ret.__next__())#执行到yield停止
2>生成器的取值方法
def generator(): print(1) yield ‘a‘ print(2) yield ‘b‘ yield ‘c‘ g = generator() for i in g:#for循环本身就是迭代输出 print(i) ##ret = g.__next__() ##print(ret) ##ret = g.__next__() ##print(ret) ##ret = g.__next__() ##print(ret)
3>同一生成器两次调用,彼此之间无关联。
def wahaha(): for i in range(2000000): yield ‘娃哈哈%s‘%i g = wahaha() g1 = wahaha() print(g.__next__()) print(g1.__next__())
4>生成器可以接着上次执行的位置继续执行
def wahaha(): for i in range(2000000): yield ‘娃哈哈%s‘%i g = wahaha() count = 0 for i in g: count +=1 print(i) if count > 50: break print(‘*******‘,g.__next__()) for i in g: count +=1 print(i) if count > 100: break
5>send方法
def generator(): print(123) content = yield 1 print(‘=======‘,content) print(456) arg = yield 2 ‘‘‘‘‘‘ yield g1 = generator() g2 = generator() g1.__next__() g2.__next__()#执行到yield之前 print(‘***‘,generator().__next__())#执行到yield并将值1进行返回打印 print(‘***‘,generator().__next__()) g = generator() ret = g.__next__()#将返回值赋给ret,此时只执行到yield,但并未将返回值进行处理 print(‘***‘,ret)#返回值进行处理:打印 ret = g.send(‘hello‘) #send的效果和next一样,执行send前必须先执行一次__next__() print(‘***‘,ret)#执行yield左边的内容,即进行赋值,然后执行yield 1与yield 2之间的部分,并将返回值打印。 #最后一个yield是为了再执行send时,可以对传入的值进行操作,但并无返回值,仅是为了使程序停止。
6>预激生成器的装饰器
def init(func): #装饰器 def inner(*args,**kwargs): g = func(*args,**kwargs) #g = average() g.__next__() return g return inner @init def average(): sum = 0 count = 0 avg = 0 while True: num = yield avg sum += num # 10 count += 1 # 1 avg = sum/count avg_g = average() #===> inner ret = avg_g.send(10) print(ret) ret = avg_g.send(20) print(ret)
7>yield from方法
def generator(): a = ‘abcde‘ b = ‘12345‘ for i in a: yield i for i in b: yield i ##同下面的表达 ## yield a[0] ## yield a[1] ## yield a[2] ## yield a[3] ## yield a[4] ## yield b[0] ## yield b[1] ## yield b[2] ## yield b[3] ## yield b[4] def generator(): a = ‘abcde‘ b = ‘12345‘ yield from a yield from b g = generator() for i in g: print(i)
8>生成器表达式
g = (i for i in range(10)) print(g) #上下的执行结果相同 for i in g: print(i)
注:括号不一样。返回的值不一样 === 几乎不占用内存。
9>各种推导式
9.1>列表推导式
1>30以内所有能被3整除的数
ret = [i for i in range(30) if i%3 == 0] #完整的列表推导式 print(ret) #g = (i for i in range(30) if i%3 == 0)#生成器
2>30以内所有能被3整除的数的平方
ret = [i*i for i in (1,2,3,4) if i%3 == 0] #ret = (i*i for i in range(30) if i%3 == 0) print(ret)
3>找到嵌套列表中名字含有两个‘e’的所有名字
names = [[‘Tom‘, ‘Billy‘, ‘Jefferson‘, ‘Andrew‘, ‘Wesley‘, ‘Steven‘, ‘Joe‘], [‘Alice‘, ‘Jill‘, ‘Ana‘, ‘Wendy‘, ‘Jennifer‘, ‘Sherry‘, ‘Eva‘]] ret = [name for lst in names for name in lst if name.count(‘e‘) ==2] #ret = (name for lst in names for name in lst if name.count(‘e‘) ==2) print(ret)
9.2>字典推导式
1>将一个字典的key和value对调
mcase = {‘a‘: 10, ‘b‘: 34}
#{10:‘a‘ , 34:‘b‘}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
2>合并大小写对应的value值,将k统一成小写
mcase = {‘a‘: 10, ‘b‘: 34, ‘A‘: 7, ‘Z‘: 3}
#{‘a‘:10+7,‘b‘:34,‘z‘:3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase}
print(mcase_frequency)
3>集合推导式
squared = {x**2 for x in [1, -1, 2]}
print(squared)
10>习题
1.监听文件输入。
2.写生成器实现:有一个文件,从文件里分段读取内容,在读出来的内容前面加上一个‘***‘,再返回给调用者。
3.获取移动平均值(send的应用)
4.处理文件,用户指定要查找的文件和内容,将文件中包含要查找的每一行都输出到屏幕。
def tail(filename): f = open(filename,encoding=‘utf-8‘) while True: line = f.readline() if line.strip(): yield line.strip() g = tail(‘file‘) for i in g: if ‘python‘ in i: print(‘***‘,i)
##readline:行读取。 ##read(10):读取指定大小的内容。 def generator(): for i in range(20): yield ‘哇哈哈%s‘%i g = generator() #调用生成器函数得到一个生成器 print(list(g)) ret = g.__next__()#每一次执行g.__next__就是从生成器中取值,预示着生成器函数中的代码继续执行 print(ret)
#num:10 20 30 10 #avg:10 15 20 17.5 def average(): sum = 0 count = 0 avg = 0 while True: num = yield avg sum += num # 10 count += 1 # 1 avg = sum/count avg_g = average() avg_g.__next__() avg1 = avg_g.send(10) avg1 = avg_g.send(20) print(avg1)
def check_file(): with open("java.docx",encoding="utf-8") as f: for i in f: if "java" in i: yield i g=check_file() for i in g: print(i.strip())
11> 面试题
1. def demo(): for i in range(4): yield i g=demo() g1=(i for i in g) g2=(i for i in g1) print(list(g1))#执行完后g1取值完成,全部给了list,即列表有值,而g1空了 print(list(g2))#当执行这句时g1没有值了,所以g2无法取到值
2. def add(n,i): return n+i def test(): for i in range(4): yield i g=test() for n in [1,10,5]: g=(add(n,i) for i in g) ##等价于: ##n=1时 ##g=(add(n,i) for i in g) ##n=10 ##g=(add(n,i) for i in g) ##n=5 ##g=(add(n,i) for i in g) #g=(add(n,i) for i in (add(n,i) for i in add(n,i) for i in g))令n=5,g初始取[0,1,2,3]进行计算 print(list(g))#所有最后输出为15,16,17,18
1) bool:True 或 False
2) int
3) float
4) complex(复数)
1)bin(二进制)
2)oct(八进制)
3)hex(十六进制)
1) abs:绝对值
2) divmod:除余函数。x,y=divmod(a,b):a为被除数,b为除数,x为除的结果,y为余数。
3) round:小数精确round(小数,精确位数)
4) pow:幂运算(两个参数),三个参数:前两个幂运算与第三个进行取余
5) sum:求和。sum(iterable,start)
6) min:最小值。min(iterable,key,default)、min(*args,key,default)
7) max:最大值。max(iterable,key,default)、max(*args,key,default)
1)列表和元组(2):list,tuple
2)相关内置函数(2)
reversed()参数:序列,返回值:反序迭代器 l = [1,2,3,4,5] l.reverse() print(l) l = [1,2,3,4,5] l2 = reversed(l) print(l2)# 保留原列表,返回一个反向的迭代器
slice():切片 l = (1,2,23,213,5612,342,43) sli = slice(1,5,2) print(l[sli]) print(l[1:5:2])
3)字符串(9)
str format:格式化输出 print(format(‘test‘, ‘<20‘))#开辟20个字节的空间,并将test左对齐显 示。 print(format(‘test‘, ‘>40‘))#开辟40个字节的空间,并将test右对齐显示。 print(format(‘test‘, ‘^40‘))#开辟40个字节的空间,并将test居中显示。 bytes #转换成bytes类型 # gbk编码→utf-8编码 print(bytes(‘你好‘,encoding=‘GBK‘)) # unicode转换成GBK的 bytes print(bytes(‘你好‘,encoding=‘utf-8‘)) # unicode转换成utf-8的bytes bytearray #网络编程 只能传二进制 #照片和视频也是以二进制存储 #html网页爬取到的也是编码 b_array = bytearray(‘你好‘,encoding=‘utf-8‘) print(b_array) 切片 —— 字节类型 不占内存 print(b_array[0])#可按字节进行修改 ‘\xe4\xbd\xa0\xe5\xa5\xbd‘ 例如:修改字符串中的a,b s1 = ‘alexa‘ s2 = ‘alexb‘ 字节 —— 字符串 占内存 l = ‘ahfjskjlyhtgeoahwkvnadlnv‘ l2 = l[:10] memoryview:memory(bytes(‘hello,eva‘,encoding="utf-8"))。 ord:字符按照Unicode转数字 print(ord(‘好‘)) print(ord(‘1‘)) chr:数字按照Unicode转字符 print(chr(97)) ascii:只要是ASCII码中的内容就打印,不是就转成\u print(ascii(‘好‘)) print(ascii(‘1‘)) name = ‘egg‘ print(‘你好%r‘%name) repr:用于%r格式化输出 print(repr(‘1‘)) print(repr(1))
1)字典(dict)(1)
2)集合(set)(2)
set
frozenset
1) len:计算列表、元组、字典等的长度。
2) enumerate:枚举。
3) all:判断是否有bool值为false的值。
print(all([‘a‘,‘‘,123]))#一个为假整体为假 print(all([‘a‘,123])) print(all([0,123]))
4) any:是否有bool值为True的值。
print(any([‘‘,True,0,[]]))#一个为真整体为真
5) zip:返回一个迭代器,有种映射关系。
l = [1,2,3,4,5] l2 = [‘a‘,‘b‘,‘c‘,‘d‘] l3 = (‘*‘,‘**‘,[1,2]) d = {‘k1‘:1,‘k2‘:2} for i in zip(l,l2,l3,d): print(i)
6) filter(func,list等参数):#filter将第二个参数里的值逐个传入函数中,若return True,则说明满足,则装入迭代对象中,否则,滤掉这个值。
def is_odd(x): return x % 2 == 1 def is_str(s): return s and str(s).strip() ret1 = filter(is_odd, [1, 6, 7, 12, 17]) ret2 = filter(is_str, [1, ‘hello‘,‘‘,‘ ‘,None,[], 6, 7, ‘world‘, 12, 17]) print(ret1) print(ret2) for i in ret1: print(i) for i in ret2: print(i) #[i for i in [1, 4, 6, 7, 9, 12, 17] if i % 2 == 1]
#求出1-100之间开平方为整数的值 from math import sqrt def func(num): res = sqrt(num) return res % 1 == 0 ret = filter(func,range(1,101)) for i in ret: print(i)
7)map:
ret = map(abs,[1,-4,6,-8]) print(ret) for i in ret: print(i)
注:filter与map的区别:
1)filter 执行了filter之后的结果集合 小于等于 执行之前的个数。filter只管筛选,不会改变原来的值。
2)map 执行前后元素个数不变,值可能发生改变。
8)sorted:生成一个新列表,不改变原列表,占内存。
l = [1,-4,6,5,-10] l.sort(key = abs)#在原列表的基础上进行排序 print(l) print(sorted(l,key=abs,reverse=True))#生成了一个新列表,占内存,默认升序 print(l)#原列表没变 l = [‘ ‘,[1,2],‘hello world‘] new_l = sorted(l,key=len) print(new_l)
注:sort与sorted的区别:
1)sort 在原列表的基础上排序。
2)sorted 生成一个新列表,将排的序添加到新列表里,占内存。
格式:lambda 形参:返回值/表达式。
eg1.求和。
def add(x,y): return x+y add = lambda x,y:x+y print(add(1,2))
eg2.判断最大值。
dic={‘k1‘:10,‘k2‘:100,‘k3‘:30}
def func(key):
return dic[key]
print(max(dic,key=func)) #根据返回值判断最大值,返回值最大的那个参数是结果
print(max(dic,key=lambda key:dic[key]))
max([1,2,3,4,5,-6,-7],key=abs)
eg3.求绝对值。
ret = map(abs,[-1,2,-3,4]) for i in ret: print(i)
eg4.求平方和。
def func(x): return x**2 ret = map(func,[-1,2,-3,4]) for i in ret: print(i) ret = map(lambda x:x**2,[-1,2,-3,4])
eg5.多层传参计算。
d = lambda p:p*2 t = lambda p:p*3 x = 2 x = d(x) #x = 4 x = t(x) #x = 12 x = d(x) #x = 24 print(x)
1.用map来处理字符串列表,把列表中所有人都变成sb,比方alex_sb。
2.用filter函数处理数字列表,将列表中所有的偶数筛选出来。
3.随意写一个20行以上的文件,运行程序,先将内容读到内存中,用列表存储。接收用户输入页码,每页5条,仅输出当页的内容。
4.如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
portfolio = [
{‘name‘: ‘IBM‘, ‘shares‘: 100, ‘price‘: 91.1},
{‘name‘: ‘AAPL‘, ‘shares‘: 50, ‘price‘: 543.22},
{‘name‘: ‘FB‘, ‘shares‘: 200, ‘price‘: 21.09},
{‘name‘: ‘HPQ‘, ‘shares‘: 35, ‘price‘: 31.75},
{‘name‘: ‘YHOO‘, ‘shares‘: 45, ‘price‘: 16.35},
{‘name‘: ‘ACME‘, ‘shares‘: 75, ‘price‘: 115.65}
]
4.1.计算购买每支股票的总价。
4.2.用filter过滤出,单价大于100的股票有哪些?
题目示例代码:
1.
name=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,‘nezha‘] def func(item): return item+‘_sb‘ ret = map(func,name) #ret是迭代器 for i in ret: print(i) print(list(ret)) ret = map(lambda item:item+‘_sb‘,name) print(list(ret))
2.
num = [1,3,5,6,7,8] def func(x): if x%2 == 0: return True #由于在filter函数中,当传入参数使函数成立时,filter才返回真,即将这个值顺便保存。所以可以直接将判断条件作为返回值。 def func(x): return x%2==0 ret = filter(func,num) #ret是迭代器 print(list(ret)) ret = filter(lambda x:x%2 == 0,num) ret = filter(lambda x:True if x%2 == 0 else False,num) print(list(ret))
3.
with open(‘file‘,encoding=‘utf-8‘) as f: l = f.readlines() page_num = int(input(‘请输入页码 : ‘)) pages,mod = divmod(len(l),5) #求有多少页,有没有剩余的行数 if mod: # 如果有剩余的行数,那么页数加一 pages += 1 # 一共有多少页 if page_num > pages or page_num <= 0: #用户输入的页数大于总数或者小于等于0 print(‘输入有误‘) elif page_num == pages and mod !=0: #如果用户输入的页码是最后一页,且之前有过剩余行数 for i in range(mod): print(l[(page_num-1)*5 +i].strip()) #只输出这一页上剩余的行 else: for i in range(5): print(l[(page_num-1)*5 +i].strip()) #输出5行
4.1
ret = map(lambda dic : {dic[‘name‘]:round(dic[‘shares‘]*dic[‘price‘],2)},portfolio) print(list(ret))
4.2
ret = filter(lambda dic:True if dic[‘price‘] > 100 else False,portfolio) print(list(ret)) ret = filter(lambda dic:dic[‘price‘] > 100,portfolio) print(list(ret))
注意函数应用:min max filter map sorted —— lambda
1.现有两元组((‘a‘),(‘b‘)),((‘c‘),(‘d‘)),请使用python中匿名函数生成列表[{‘a‘:‘c‘},{‘b‘:‘d‘}]。
2.以下代码的输出是什么?请给出答案并解释。
def multipliers():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in multipliers()])
请修改multipliers定义是达到预期结果。
代码如下:
1.
#考察:匿名函数 ==> 内置函数 ret=zip(((‘a‘),(‘b‘)),((‘c‘),(‘d‘))) def func(tup): return {tup[0]:tup[1]} func=lambda tup:{tup[0]:tup[1]} res=map(func,ret) print(list(res))
2.执行结果为:[6,6,6,6]
multipliers()等价于[lambda x:i*x,lambda x:i*x,lambda x:i*x,lambda x:i*x]。m(2)调用了四次,而传入的为x=2。在调用时才计算,所以当调用时for循环已循环完毕,所以i=3.将return后的式子改成生成器就可以实现(lambda x:i*x for i in range(4))。即每调用一次,才执行一次for循环,这样在计算时,每次的i是不一样的。
1.定义:在函数中调用自身函数。
#RecursionError: maximum recursion depth exceeded while calling a Python object
注:递归的错误,超过了递归的最大深度。最大递归深度默认是997/998 —— 是python从内存角度出发做得限制。
2.设置递归深度
import sys sys.setrecursionlimit(1000000) n = 0 def story(): global n n += 1 print(n) story() story()
注:虽然递归深度可设置,但一般不选择设置,如果递归次数太多,就不适合使用递归来解决问题。
3.递归的优缺点
1)递归的缺点:占内存。
2)递归的优点:会让代码变简单。
注:
1)只要写递归函数,必须要有结束条件。
2) 返回值
不要只看到return就认为已经返回了。要看返回操作是在递归到第几层的时候发生的,然后返回给了谁。如果不是返回给最外层函数,调用者就接收不到。需要再分析,看如何把结果返回回来。
举例:
1.年龄到底多大?
def age(n): if n == 4: return 40 elif n >0 and n < 4: return age(n+1)+2 print(age(1))
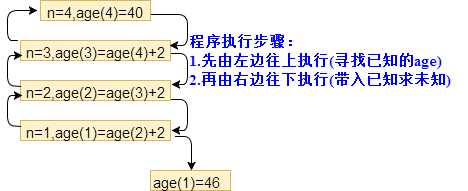
2.二分法递归找值
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] def find(l,aim,start = 0,end = None): end = len(l) if end is None else end mid_index = (end - start)//2 + start if start <= end: if l[mid_index] < aim: return find(l,aim,start =mid_index+1,end=end) elif l[mid_index] > aim: return find(l, aim, start=start, end=mid_index-1) else: return mid_index else: return ‘找不到这个值‘ ret= find(l,44) print(ret)
3.斐波那契数列(时间复杂度高)
def fib(n): if n==1 or n==2: return 1 else: return fib(n-1)+fib(n-2) print(fib(10))
4.阶乘
def jiecheng(n): if n==1: return 1 return jiecheng(n-1)*n jiecheng=lambda n:1 if n==1 else jiecheng(n-1)*n ret=jiecheng(5) print(ret) #jiecheng(5)→5*jiecheng(4)→5*4*jiecheng(3)→5*4*3*jiecheng(2)→5*4*3*2*jiecheng(1)
计算的方法:人脑复杂,计算机简单。
我们学习的算法 都是过去时,通过了解基础的算法,才能创造出更好的算法。
二分查找算法(必须处理有序的列表)
eg1.二分法找值
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] def find(l,aim,start = 0,end = None): end = len(l) if end is None else end mid_index = (end - start)//2 + start if start <= end: if l[mid_index] < aim: return find(l,aim,start =mid_index+1,end=end) elif l[mid_index] > aim: return find(l, aim, start=start, end=mid_index-1) else: return mid_index else: return ‘找不到这个值‘ ret= find(l,44) print(ret)
原文:https://www.cnblogs.com/rx-h/p/11767039.html
