Hierarchical clustering-层次聚类
概念:层次聚类(hierarchical clustering)试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集的划分可以采用“自底向上”的聚合策略,也可以采用“自顶向下”的分拆策略。
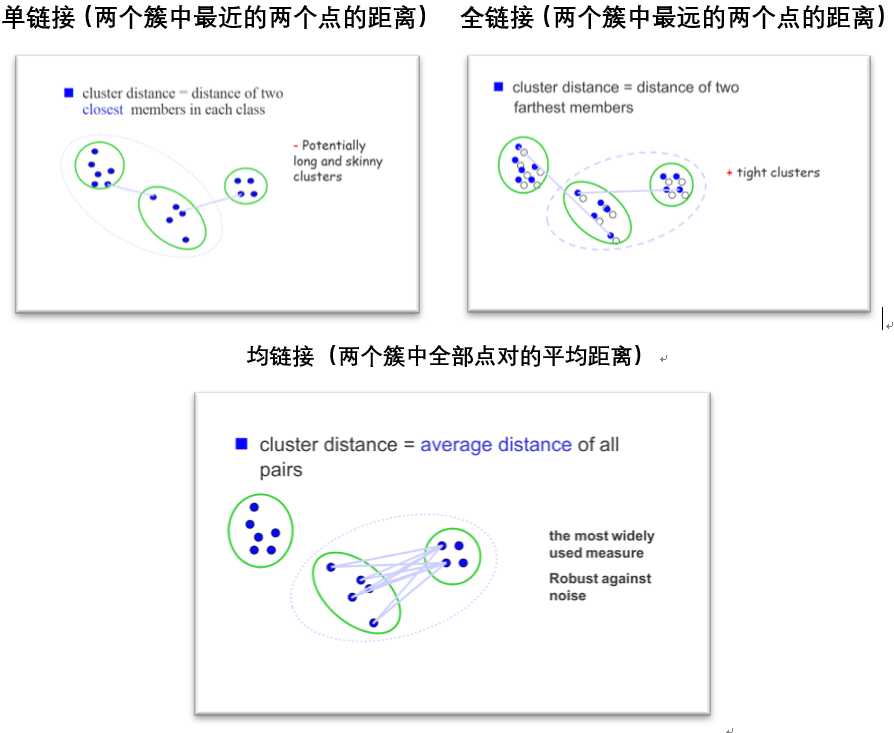
算法:AGNES(AGglomerative NESting)是一种采用自底向上聚合策略的层次聚类算法。它先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直至达到预设的聚类簇个数。这里的关键是如何计算聚类簇之间的距离。实际上,每个聚类簇是一个样本集合,因此,只需要采用关于集合的某种距离即可。通常采用三种距离dmin,dmax,davg,在AGNES算法中被相应地称为“单链接(single-linkage)”、“全链接(complete-linkage)”、“均链接(average-linkage)”算法。
代码示例:
#import the library that we need
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import adjusted_rand_score
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
#Use the Agglomerative algorithm and plot the adjusted_rand_score
#one line is linkage=‘avarage‘, the other is linkage=‘complete‘
#database is load_iris
def test_AgglomerativeClustering(*data):
X,y=data
linkages=[‘average‘,‘complete‘]
nums=range(1,50)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
markers="+o*"
for i,linkage in enumerate(linkages):
ARIs=[]
for num in nums:
clu=AgglomerativeClustering(n_clusters=num,linkage=linkage)#n_clusters:the number of clusters we want;linkage:the way to calculate the distance
predicts=clu.fit_predict(X)
ARIs.append(adjusted_rand_score(predicts,y))
ax.plot(nums,ARIs,marker=markers[i],label="linkage:%s"%linkage)
ax.set_xlabel("n_clusters")
ax.set_ylabel("ARI")
ax.legend(loc="best")
plt.show()
#main function
def main():
Data1=load_iris()
X=Data1.data
y=Data1.target
test_AgglomerativeClustering(X,y)
pass
if __name__==‘__main__‘:
main()
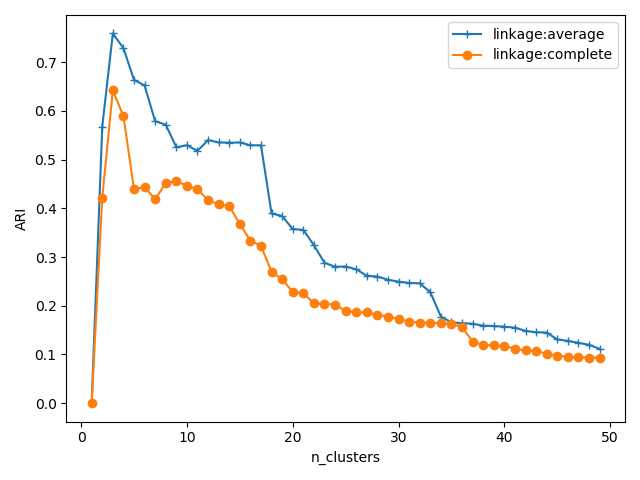
运行结果:
机器学习笔记:Hierarchical_clustering with scikit-learn(层次聚类)
原文:https://www.cnblogs.com/Ycc-LearningRate/p/11881338.html