Kafka+SparkStreaming+Hbase
由于数据大量的迁移,再加上业务的改动,新增了很多表,导致rerigon总数接近4万(36个节点)
CDH界面较多关于web服务器相应时间过长,和队列刷新速度较慢。
streaming界面,每隔一段时间就会需要较长的处理时间
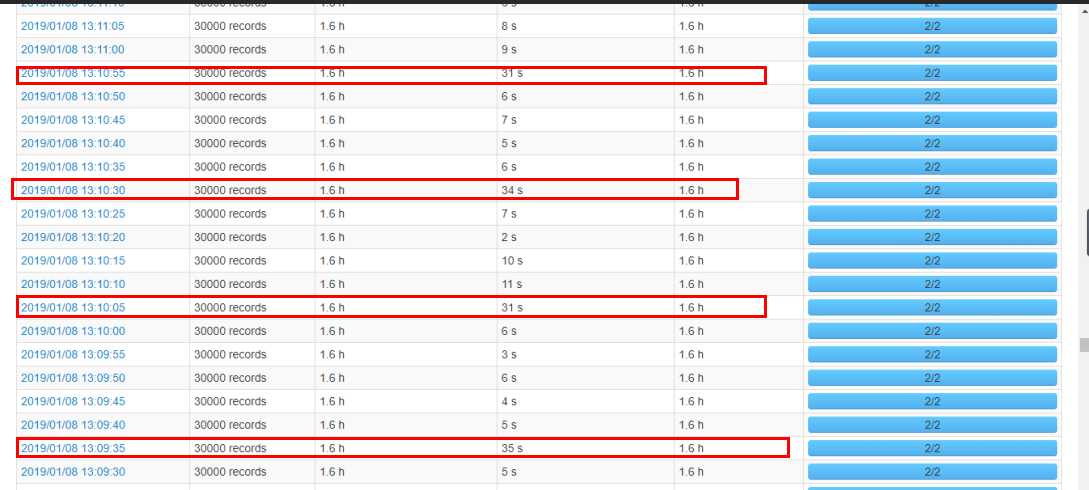
【1】
首先把一些业务不需要的表disable掉,region下线,最后还剩2.5万个线上region,随后CDH页面无异常信息了,并且streaming处理时间都比较正常了(四类业务表现都相同)
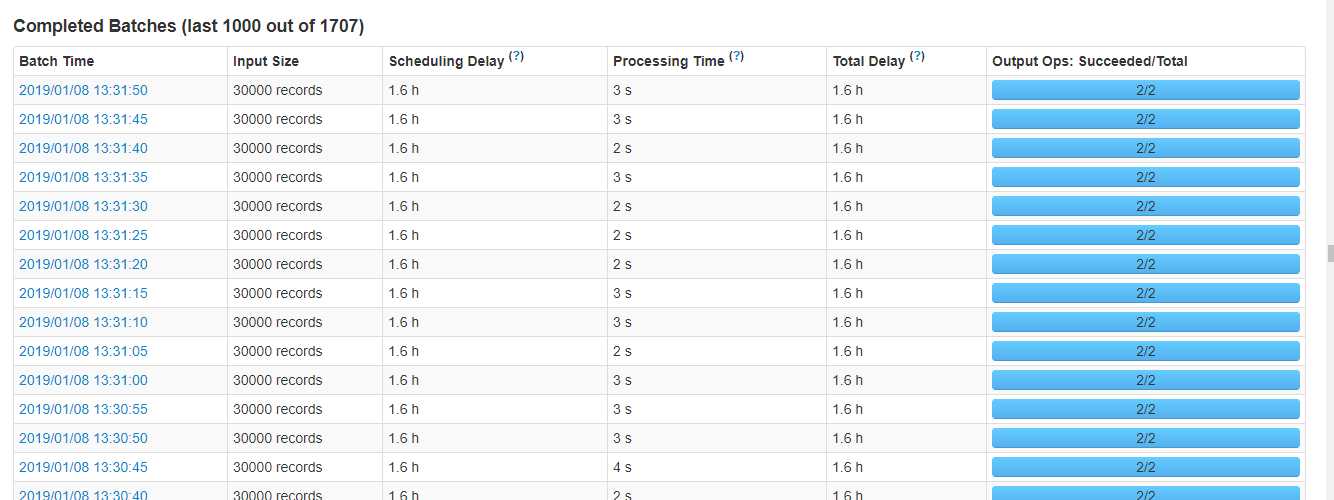
【2】
由于业务上每月都会有新表,所以以上的操作不能满足,经过研究,可以在保证表的请求量不高的情况下,把当前表的region合并,从而减少region数。而且Hbase集群目前已经停掉了region自动分裂,所以不会有在合并完之后再分裂的情况。
禁用分裂机制:

集群配置:
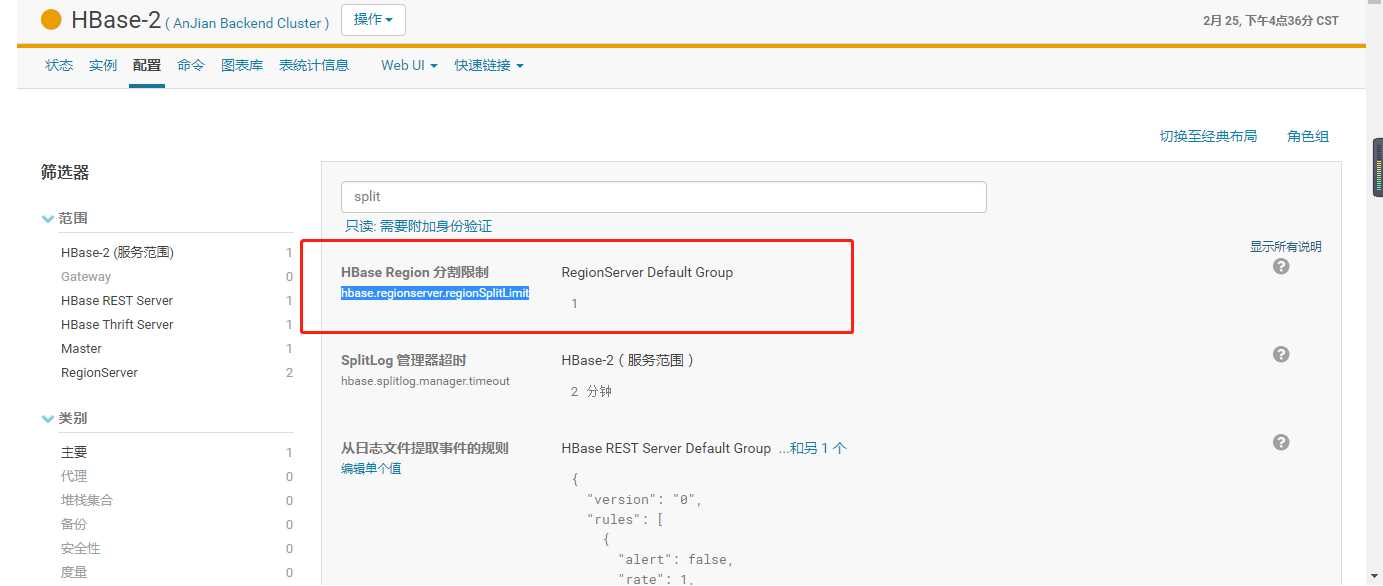
理论上讲,现在regionserver分配了64G内存,0.8的写入高水位线,也就是64*0.8=51.2G用作写,每个memstore占用128M,这么算的话理论上也就每个server400多个region的时候,不会造成过早的flush,总共下来400*36个,现在已经是超负荷运行了,所以还需要将Region进行合并。
合并代码:
public class Hbase_Merge {
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "zk1,zk2,zk3");
HBaseAdmin admin = new HBaseAdmin(conf);
List<HRegionInfo> regions = admin.getTableRegions(TableName.valueOf("TableName"));
Collections.sort(regions, new Comparator<HRegionInfo>() {
@Override
public int compare(HRegionInfo o1, HRegionInfo o2) {
return Bytes.compareTo(o1.getStartKey(),o2.getStartKey());
}
});
HRegionInfo regionInfo =null;
for (HRegionInfo r : regions){
int index =regions.indexOf(r);
if(index %2 == 0){
regionInfo = r;
}else{
System.out.println("start to merge two regions,NUM:"+index+" and "+(index+1) );
admin.mergeRegions(regionInfo.getEncodedNameAsBytes(),r.getEncodedNameAsBytes(),false);
System.out.println("merge two regions finished");
}
}
System.out.println("merge all regions finished");
}
}
最终Region数大量减少,Streaming任务也恢复正常。
IO高峰为合并region导致的,入Hbase的程序都将受到影响,Streaming批处理时间增长,中间还伴随着Region-In-Transition(此处影响不大)
建议:避开业务高峰期对Region合并
这些都是之前存到有道上了,搬到这里费了好大的劲,还得不断学习,哈哈
原文:https://www.cnblogs.com/changsblogs/p/11857544.html