用Python爬取51job里面python相关职业、工作地址和薪资。
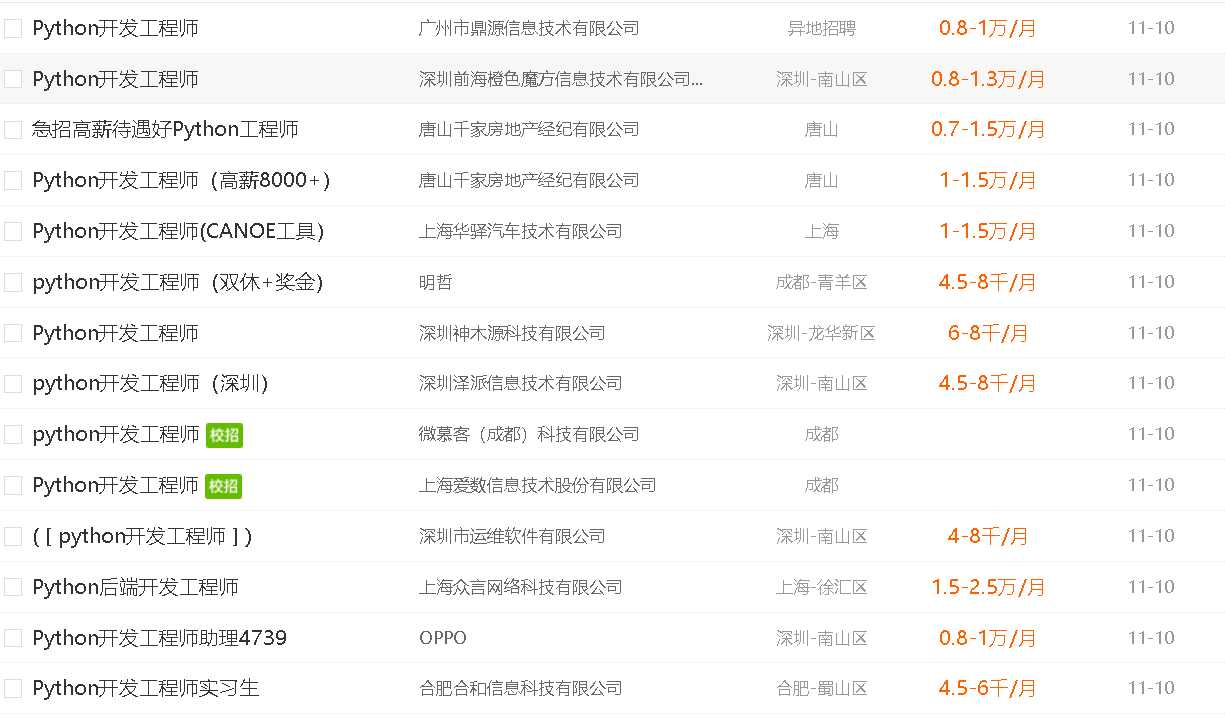
51job上的信息
程序代码
from bs4 import BeautifulSoup from urllib.request import urlopen header ={ "Connection": "keep-alive", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36", "Accept":" text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Accept-Encoding": "gzip,deflate", "Accept-Language": "zh-CN,zh;q=0.8"}; html = urlopen("https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=").read().decode(‘GBK‘) soup = BeautifulSoup(html,"html.parser") titles=soup.select("p[class=‘t1‘] a")#挑选所需信息所在的标签 salaries=soup.select("span[class=‘t4‘]") di=soup.select("span[class=‘t3‘]") for i in range(len(titles)): print("{:30}{:10}{}".format(titles[i].get(‘title‘),di[i+1].get_text(),salaries[i+1].get_text()))
运行结果

原文:https://www.cnblogs.com/ngxt/p/11831629.html