案例分析:假设有一个生产场景,两台服务器A、B在实时产生日志数据,日志数据类型主要为access.log、nginx.log和web.log。现在需要将A、B两台服务器产生的日志数据access.log、nginx.log和web.log采集汇总到C服务器上,并统一收集上传到HDFS上保存。
此案例将 node02 和 node03 分别作为A服务器和B服务器进行第一阶段的日志数据采集,将 node01 作为C服务器进行日志数据汇总并上传到 HDFS。
$ cd /export/softwares
#上传安装包
$ rz
#将安装包解压到/export/servers 目录下
$ tar -zxvf apache-flume-1.8.0-bin.tar.gz -C ../servers
$ cd /export/servers
#重命名解压的文件名
$ mv apache-flume-1.8.0-bin flume
$ cd /export/servers/flume/conf
$ mv flume-env.sh.template flume-env.sh
# $ vim flume-env.sh 或者用 notepad++
# 修改 JAVA_HOME
export JAVA_HOME=/export/servers/jdk1.8.0_141
# 在文档底部添加以下内容:
export FLUME_HOME=/export/servers/flume
export PATH=:$FLUME_HOME/bin:$PATH
# 刷新配置文件
$ source /etc/profile
$ scp -r /export/servers/flume/ node02:/export/servers/
$ scp -r /export/servers/flume/ node03:/export/servers/
# 刷新配置文件
$ scp /etc/profile node02:/etc/profile
$ scp /etc/profile node03:/etc/prof
# define agent
a1.sources=r1 r2 r3
a1.sinks=k1
a1.channels=c1
# desc (first) source:r1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /root/logs/access.log
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=static
a1.sources.r1.interceptors.i1.key=type
a1.sources.r1.interceptors.i1.value=access
#desc (second) source:r2
a1.sources.r2.type=exec
a1.sources.r2.command=tail -F /root/logs/nginx.log
a1.sources.r2.interceptors=i2
a1.sources.r2.interceptors.i2.type=static
a1.sources.r2.interceptors.i2.key=type
a1.sources.r2.interceptors.i2.value=nginx
#desc source:r3
a1.sources.r3.type=exec
a1.sources.r3.command=tail -F /root/logs/web.log
a1.sources.r3.interceptors=i3
a1.sources.r3.interceptors.i3.type=static
a1.sources.r3.interceptors.i3.key=type
a1.sources.r3.interceptors.i3.value=web
# desc channel:c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=2000000
a1.channels.c1.transactionCapacity=100000
# desc sink:k1
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=node01
a1.sinks.k1.port=41414
# desc source channel sink
a1.sources.r1.channels=c1
a1.sources.r2.channels=c1
a1.sources.r3.channels=c1
a1.sinks.k1.channel=c1
# desc agent
a1.sources=r1
a1.sinks=k1
a1.channels=c1
# desc source:r1
a1.sources.r1.type=avro
a1.sources.r1.bind=node01
a1.sources.r1.port=41414
# desc interceptors
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
# desc channel:c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=20000
a1.channels.c1.transactionCapacity=10000
# desc sink:k1
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://node01:8020/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix=events
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
# file_num
a1.sinks.k1.hdfs.rollCount=0
#file_time
a1.sinks.k1.hdfs.rollInterval=0
#file_size
a1.sinks.k1.hdfs.rollSize=10485760
# HDFS_NUM
a1.sinks.k1.hdfs.batchSize=20
# HDFS_TIMEOUT
a1.sinks.k1.hdfs.callTimeout=30000
# source sink channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
# 在 node01 上执行以下命令 $ cd/export/servers/hadoop-2.6.0-cdh5.14.0 $ sbin/start-dfs.sh $ sbin/start-yarn.sh # 通过 jps 查看当前进程,应该有6个进程 NameNode DataNode ResourceManager SecondaryNameNode NodeManager Jps #通过 jps 查看 node02、node03 的进程,应该有3个 DataNode NodeManager Jps
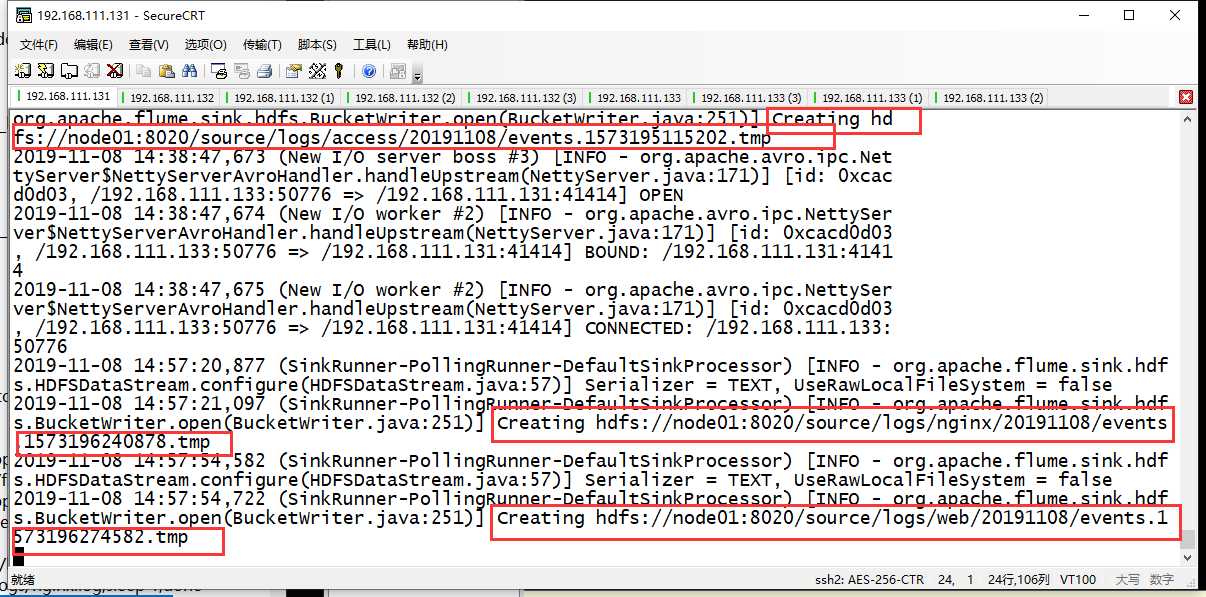
# 先在 node01 上启动 Flume 系统 $ cd /export/servers/flume $ bin/flume-ng agent -c conf -f conf/avro-hdfs_logCollection.conf -name a1 -Dflume.root.logger=INFO,console # 然后在 node02、node03 上启动 $ cd /export/servers/flume $ bin/flume-ng agent -c conf -f conf/exec-avro_logCollection.conf -name a1 -Dflume.root.logger=INFO,console
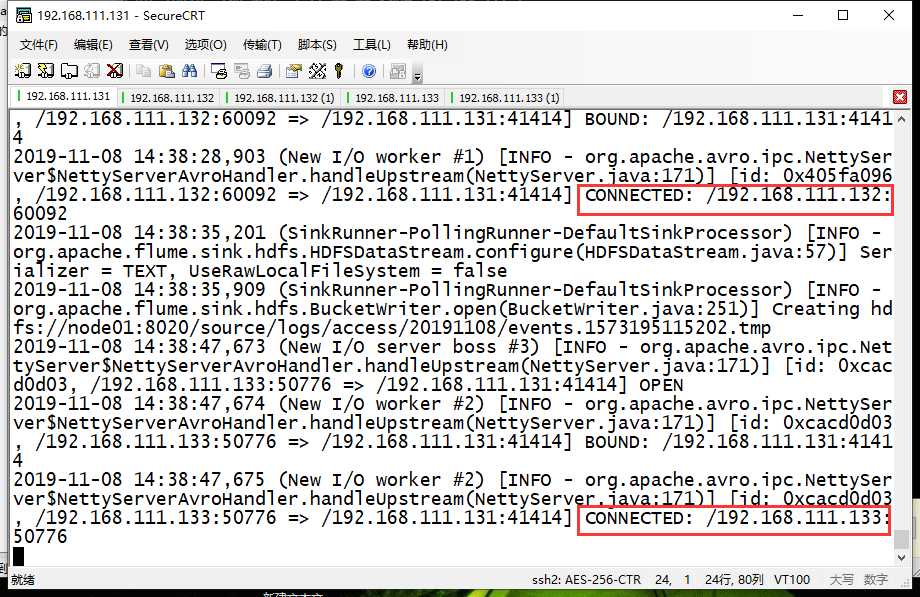
# 先检查 /root/logs 是否存在,如不存在,自行在三台机器上创建 $ mkdir /root/logs # 在 node02、node03 上分别克隆3个会话窗口,并且在打开的3个窗口中分别执行如下指令,用来产生日志数据 $ while true;do echo "access access ..." >>/root/logs/access.log;sleep 1;done $ while true;do echo "nginx nginx ..." >>/root/logs/nginx.log;sleep 1;done $ while true;do echo "web web ..." >>/root/logs/web.log;sleep 1;done
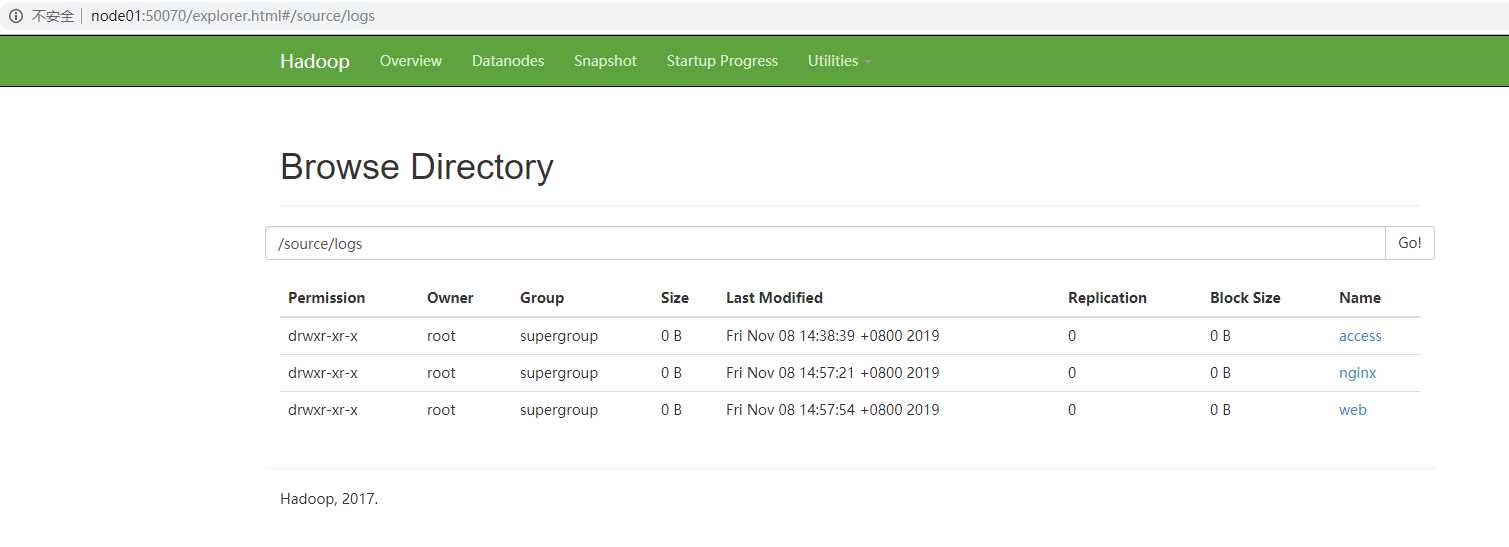
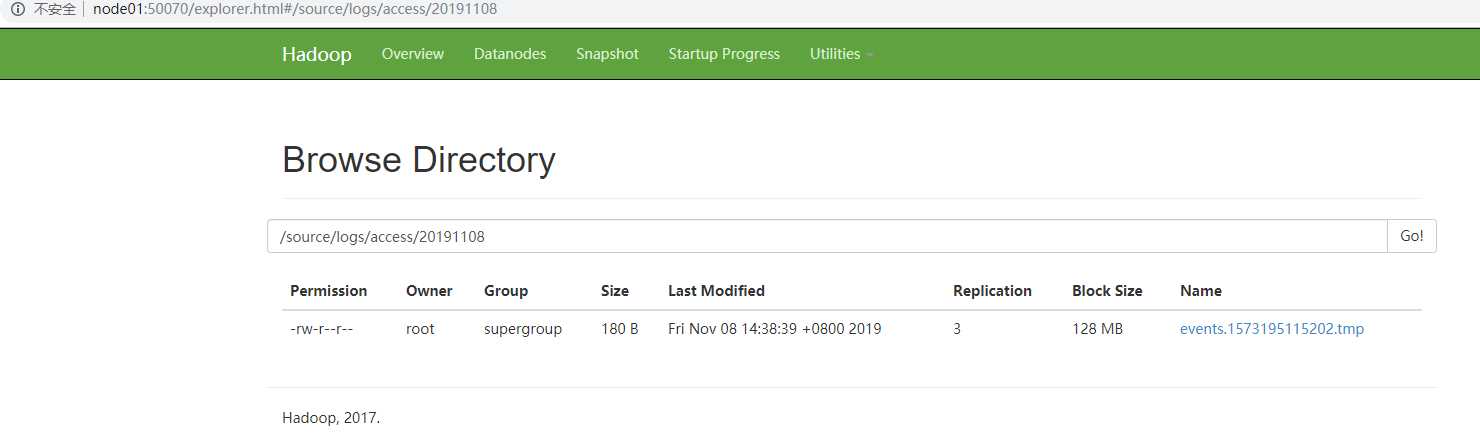
# 网址 node01:50070
原文:https://www.cnblogs.com/aurora1123/p/11827382.html