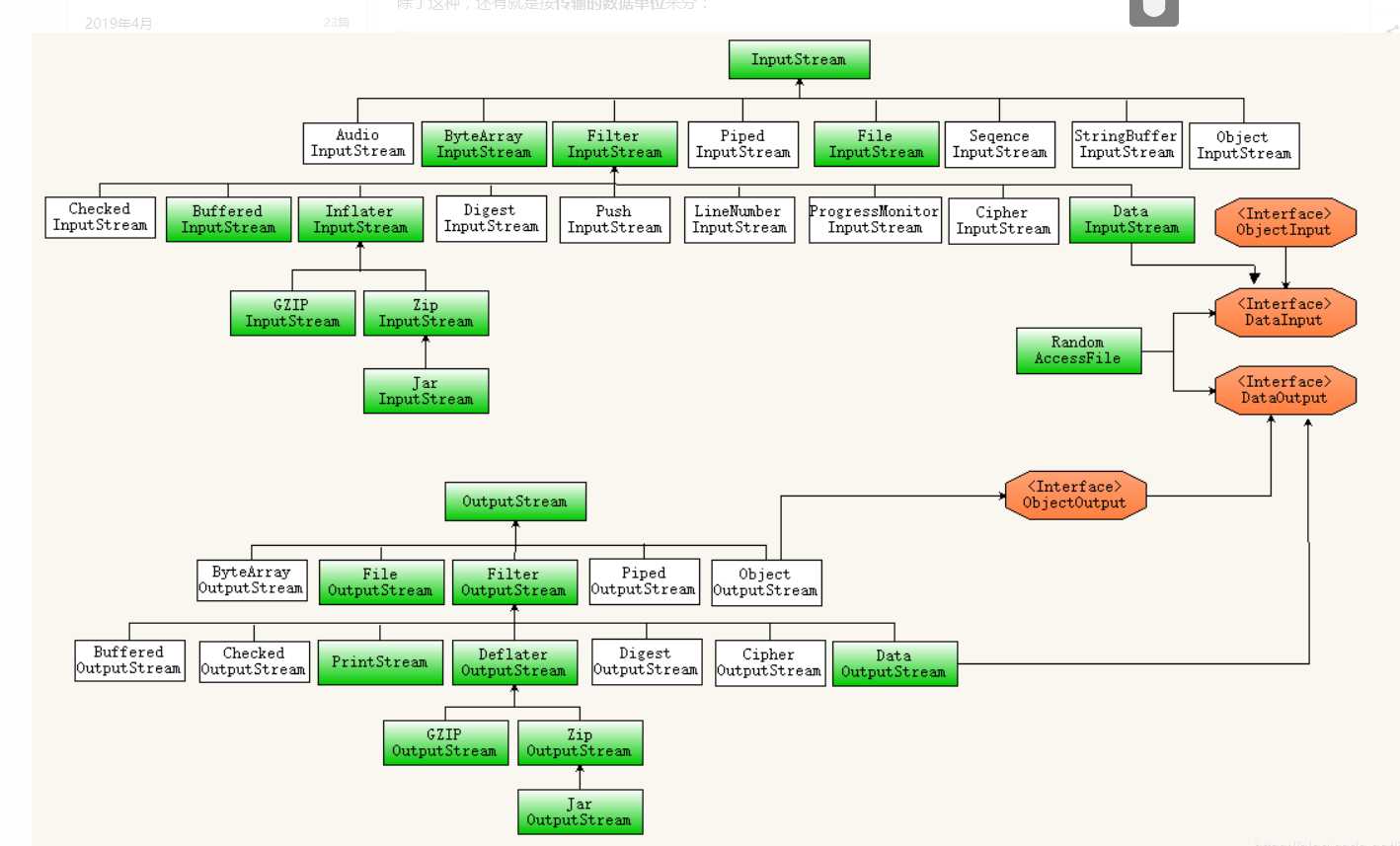
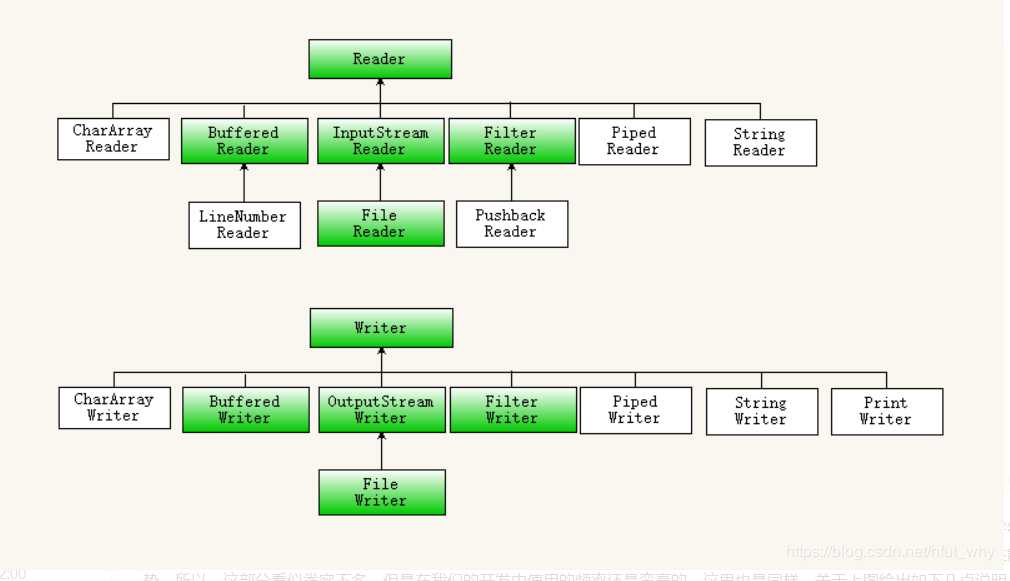
IO流概述
IO流用来处理设备之间的数据传输
Java对数据的操作是通过流的方式
Java用于操作流的对象都在IO包中 java.io
IO流分类
1:按照数据流向 站在内存角度
输入流 读入数据
输出流 写出数据
2:按照数据类型
字节流 可以读写任何类型的文件 比如音频 视频 文本文件
字符流 只能读写文本文件
什么情况下使用哪种流呢?
如果数据所在的文件通过windows自带的记事本打开并能读懂里面的内容,就用字符流。其他用字节流。
IO流基类概述
1.字节流的抽象基类:
InputStream ,OutputStream。
2.字符流的抽象基类:
Reader , Writer。
注:由这四个类派生出来的子类名称都是以其父类名作为子类名的后缀。
如:InputStream的子类FileInputStream。
如:Reader的子类FileReader。构造方法
FileOutputStream(File file)
FileOutputStream(String name)
案例演示
FileOutputStream写出数据
注意事项:
创建字节输出流对象了做了几件事情?
1.系统资源创建a.txt文件
2.建了一个fos对象
3.fos对象指向这个文件
为什么一定要close()?
1.系统释放关于管理a.txt文件的资源
2.Io流对象变成垃圾,等待垃圾回收器对其回收
FileOutputStream的三个write()方法
public void write(int b):写一个字节 超过一个字节 砍掉前面的字节
public void write(byte[] b):写一个字节数组
public void write(byte[] b,int off,int len):写一个字节数组的一部分 缓冲区IO流类BufferedInputStream,BufferedOutputStream分别是FilterInputStream和FilterOutputStream的子类。
缓冲思想
字节流一次读写一个数组的速度明显比一次读写一个字节的速度快很多,
这是加入了数组这样的缓冲区效果,java本身在设计的时候,
也考虑到了这样的设计思想(装饰设计模式后面讲解),所以提供了字节缓冲区流
BufferedOutputStream的构造方法
OutputStreamWriter的构造方法
OutputStreamWriter(OutputStream out):根据默认编码(GBK)把字节流的数据转换为字符流
OutputStreamWriter(OutputStream out,String charsetName):根据指定编码把字节流数据转换为字符流
方法概述
public void write(int c) 写一个字符
public void write(char[] cbuf) 写一个字符数组
public void write(char[] cbuf,int off,int len) 写一个字符数组的 一部分
public void write(String str) 写一个字符串
public void write(String str,int off,int len) 写一个字符串的一部分
InputStreamReader的构造方法
InputStreamReader(InputStream is):用默认的编码(GBK)读取数据
InputStreamReader(InputStream is,String charsetName):用指定的编码读取数据方法概述
public int read() 一次读取一个字符
public int read(char[] cbuf) 一次读取一个字符数组 如果没有读到 返回-1
案例演示:字符流的2种读数据的方式FileReader和FileWriter的出现
转换流的名字比较长,而我们常见的操作都是按照本地默认编码实现的,
所以,为了简化我们的书写,转换流提供了对应的子类。
FileWriter
FileReader
案例演示: FileWriter和FileReader复制文本文件
字符流便捷类: 因为转换流的名字太长了,并且在一般情况下我们不需要制定字符集,
于是java就给我们提供转换流对应的便捷类
转换流 便捷类
OutputStreamWriter ---子类----> FileWriter
InputStreamReader ---子类----> FileReader案例演示: BufferedWriter写出数据 高效的字符输出流
案例演示: BufferedReader读取数据 高效的字符输入流
高效的字符流
高效的字符输出流: BufferedWriter
构造方法: public BufferedWriter(Writer w)
高效的字符输入流: BufferedReader
构造方法: public BufferedReader(Reader e)数据输入输出流 DataInputStream,DataOutputStream
内存操作流
打印流
序列化流
随机访问流
Properties
数据输入流概述:
数据输入流(DataInputStream和DataOutputStream)是继承父类字节流(FileOutputStream和FilterInputStream)拥有父类的功能,所以这里我们学习一下它特有的功能(即可以存储基本数据类型)
内存操作流的概述
1.操作字节数组
ByteArrayOutputStream
构造方法:
ByteArrayOutputStream()
创建一个新的 byte 数组输出流。不指定大小的话缓冲区会随着数据的不断写入而自动增长
ByteArrayOutputStream(int size)
创建一个新的 byte 数组输出流,它具有指定大小的缓冲区容量(以字节为单位)。
举例:
ByteArrayOutputStream bos = new ByteArrayOutputStream();
bos.write("你好".getBytes());
方法:
使用toByteArray()可以将bos转换成数组
使用toString()可以把bos转换成字符串
ByteArrayInputStream
构造方法:
ByteArrayInputStream(byte[] buf)
创建一个 ByteArrayInputStream,使用 buf 作为其缓冲区数组。
ByteArrayInputStream(byte[] buf, int offset, int length)
创建 ByteArrayInputStream,使用 buf 作为其缓冲区数组。
举例:
ByteArrayInputStream bis = new ByteArrayInputStream(bytes);
此流关闭无效,所以无需关闭
2.操作字符数组
CharArrayWrite
CharArrayReader
跟上面一样只不过操作的是字符底层是通过字符数组来进行存储的
4.操作字符串
StringWriter
StringReader
一样只不过操作的是字符串底层是通过字符串数组来进行存储的
打印流分为:
PrintStream 字节打印流(使用最多)
PrintWriter 字符打印流
打印流的特点
1.打印流只能操作目的地,不能操作数据源(不能进行读取数据)
2.可以操作任意数据类型的数据 调用print() 方法可以写任意数据类型
3.如果我们启用自动刷新,那么在调用println、printf 或 format 方法中的一个方法的时候,会完成自动刷新
4.通过以下构造创建对象 能够启动自动刷新 然后调用println、printf 或 format 方法中的一个方法的时候,会完成自动刷新
public PrintWriter(OutputStream out, boolean autoFlush) 第二个参数为ture就是启动 自动刷新
public PrintWriter(Writer out, boolean autoFlush) 第二个参数为ture就是表明启动自动刷新
5.这个流可以直接对文件进行操作(可以直接操作文件的流: 就是构造方法的参数可以传递文件或者文件路径)
往文件里打印:
PrintStream printStream = new PrintStream(new File("e.txt"));
printStream.println(200);
往屏幕打印:
PrintStream out = System.out;这个可以往屏幕打印
out.println(200);这个就是等价与System.out.println("out = " + out);
随机访问流概述
RandomAccessFile概述 最大特点 能读能写
RandomAccessFile类不属于流,是Object类的子类。但它融合了InputStream和OutputStream的功能。
支持对随机访问文件的读取和写入。
RandomAccessFile的父类是Object , 这个流对象可以用来读取数据也可以用来写数据.可以操作任意数据类型的数据.
我们可以通过getFilePointer方法获取文件指针,并且可以通过seek方法设置文件指针
构造方法:
RandomAccessFile(File file, String mode)
创建从中读取和向其中写入(可选)的随机访问文件流,该文件由 File 参数指定。mode参数是选择读写模式
RandomAccessFile(String name, String mode)
创建从中读取和向其中写入(可选)的随机访问文件流,该文件具有指定名称。
常用方法:
public final String readLine() 从此文件读取文本的下一行。
public long getFilePointer() 读取偏移量
更多方法清查文档进行使用
序列化和反序列化:
ObjectOutputStream
ObjectInputStream
详细用法参考文档
解决序列化时候的黄色警告线问题
我们的一个类可以被序列化的前提是需要这个类实现Serializable接口,就需要给这个类添加一个标记.在完成序列化以后,序列化文件中还存在一个标记,然后在进行反序列化的时候,会验证这个标记和序列化前的标记是否一致,如果一致就正常进行反序列化,如果不一致就报错了. 而现在我们把这个类做了修改,将相当于更改了标记,而导致这两个标记不一致,就报错了.
解决问题: 只要让这个两个标记一致,就不会报错了吧
怎么让这两个标记一致呢? 不用担心,很简单,难道你们没有看见黄色警告线吗? alt+enter, 生成出来
private static final long serialVersionUID = -7602640005373026150L;
使用transient关键字声明不需要序列化的成员变量
private transient int age ;可以阻止成员变量的序列化使用transient
构造方法:
Properties()
创建一个无默认值的空属性列表。
Properties(Properties defaults)
创建一个带有指定默认值的空属性列表。
主要方法:
public Object setProperty(String key, 这个和put方法一样
String value)
public String getProperty(String key, 这个和集合get方法差不多就是有个默认值,没有的话就会去默认值
String defaultValue)
public void store(OutputStream out,
String comments) 把集合中的键值对存储到文件中
public void load(InputStream inStream) 把文件中的键值对存入集合中
注意:
Properties是集合那么他就和集合很多相似。
SequenceInputStream
表示其他输入流的逻辑串联。
它从输入流的有序集合开始,
并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,
依次类推,直到到达包含的最后一个输入流的文件末尾为止
构造方法
SequenceInputStream(InputStream s1, InputStream s2)
通过记住这两个参数来初始化新创建的 SequenceInputStream(将按顺序读取这两个参数,先读取 s1,然后读取 s2),
以提供从此 SequenceInputStream 读取的字节。
构造方法
SequenceInputStream(Enumeration<? extends InputStream> e)
通过记住参数来初始化新创建的 SequenceInputStream,该参数必须是生成运行时类型为 InputStream 对象的 Enumeration 型参数。
举例:
FileInputStream file = new FileInputStream("歌曲合并.mp3");
FileInputStream file1 = new FileInputStream("许巍-歌曲大联唱.mp3");
Vector<FileInputStream> objects = new Vector<>();
objects.add(file);
objects.add(file1);
Enumeration<FileInputStream> elements = objects.elements();
SequenceInputStream sequenceInputStream = new SequenceInputStream(elements);
FileOutputStream fileOutputStream = new FileOutputStream("xion.mp3");
int len=0;
byte[] bytes = new byte[1024*1024*8];
while ((len=sequenceInputStream.read(bytes))!=-1){
fileOutputStream.write(bytes);
fileOutputStream.flush();
}
fileOutputStream.close();
sequenceInputStream.close();
ZipOutputStream 压缩流
void putNextEntry(ZipEntry e)
开始写入新的 ZIP 文件条目并将流定位到条目数据的开始处。
ZipInputStream 解压流
ZipEntry getNextEntry()
读取下一个 ZIP 文件条目并将流定位到该条目数据的开始处。
类 ZipEntry 此类用于表示 ZIP 文件条目。
String getName() 返回条目名称。
boolean isDirectory() 如果为目录条目,则返回 true。
原文:https://www.cnblogs.com/project-zqc/p/11809499.html