CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索引、压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更快的交互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析引擎。
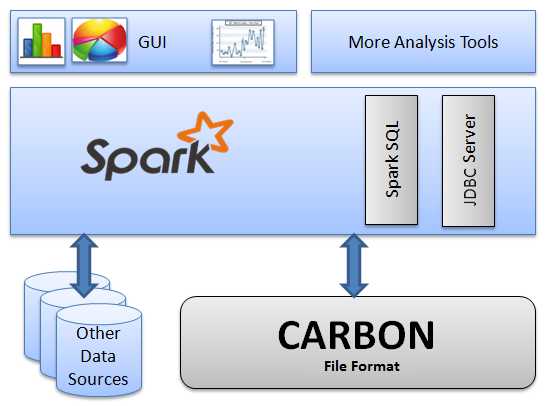
使用CarbonData的目的是对大数据即席查询提供超快速响应。从根本上说,CarbonData是一个OLAP引擎,采用类似于RDBMS中的表来存储数据。用户可将大量(10TB以上)的数据导入以CarbonData格式创建的表中,CarbonData将以压缩的多维索引列格式自动组织和存储数据。数据被加载到CarbonData后,就可以执行即席查询,CarbonData将对数据查询提供秒级响应。
CarbonData将数据源集成到Spark生态系统,用户可使用Spark SQL执行数据查询和分析。也可以使用Spark提供的第三方工具JDBCServer连接到Spark SQL。
CarbonData作为Spark内部数据源运行,不需要额外启动集群节点中的其他进程,CarbonData Engine在Spark Executor进程之中运行。
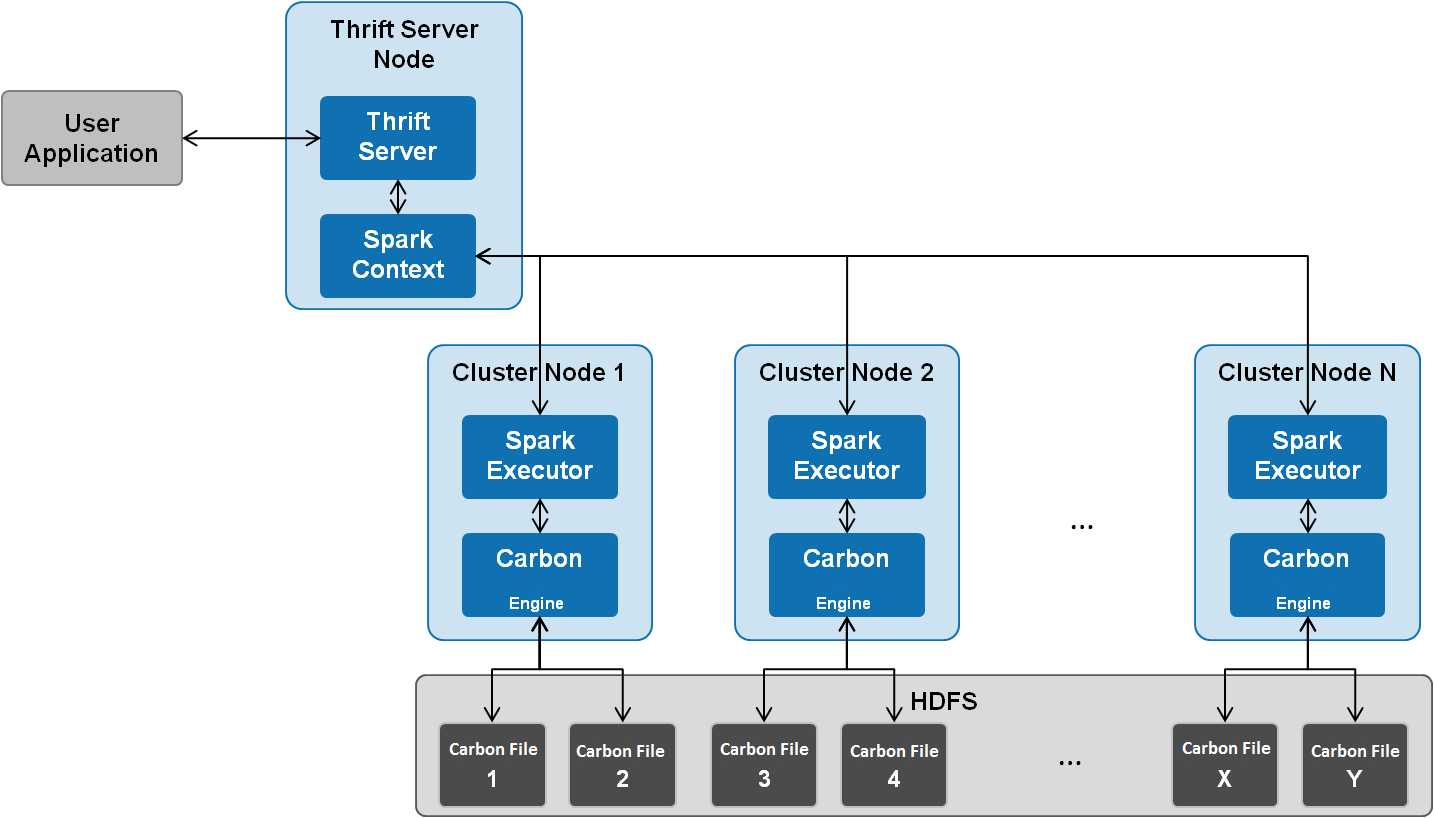
存储在CarbonData Table中的数据被分成若干个CarbonData数据文件,每一次数据查询时,CarbonData Engine模块负责执行数据集的读取、过滤等实际任务。CarbonData Engine作为Spark Executor进程的一部分运行,负责处理数据文件块的一个子集。
Table数据集数据存储在HDFS中。同一Spark集群内的节点可以作为HDFS的数据节点。
本章节描述CarbonData主要规格。
|
实体 |
测试值 |
测试环境 |
|---|---|---|
|
表数 |
10000 |
3个节点,每个executor 4个CPU核,20GB。Drive内存5GB, 3个 Executor。 总列数:107 String:75 Int:13 BigInt:7 Timestamp:6 Double:6 |
|
表的列数 |
2000 |
3个节点,每个executor 4个CPU核,20GB。Drive内存5GB, 3个 Exec |
|
原始CSV文件大小的最大值 |
200GB |
17 个cluster节点, 每个executor 150 GB ,25个CPU核。Driver 内存 10 GB 17 个Executor。 |
|
每个文件夹的CSV文件数 |
100 个文件夹, 每个文件夹10个文件,每个文件大小 50MB。 |
3个节点,每个executor 4个CPU核,20GB。Drive内存5GB, 3个 Executor。 |
|
加载文件夹数 |
10000 |
3个节点,每个executor 4个CPU核,20GB。Drive内存5GB, 3个 Executor。 |
|
一列中字典的cardinality值 |
1 Million |
在表创建期间,对high cardinality字典列使用NO_DICTIONARY_EXCLUDE标志参数。 如果cardinality大于50000,建议不要使用字典。 |
数据加载所需的内存取决于以下因素:
加载包含1000万条记录和300列的8 GB CSV文件的数据,每行大小约为0.8KB的8GB CSV文件的数据 需要约为10GB的executor执行内存,也就是说,“carbon.sort.size” 配置为“100000”,所有其他前面的配置保留默认值。
|
实体 |
测试值 |
|---|---|
|
二级索引表数量 |
10 |
|
二级索引表中的组合列的列数 |
5 |
|
二级索引表中的列名长度(单位:字符) |
120 |
|
二级索引表名长度(单位:字符) |
120 |
|
表中所有二级索引表的表名+列名的累积长度*(单位:字符) |
3800** |
本章节介绍CarbonData所有配置的详细信息。
|
参数 |
默认值 |
描述 |
|---|---|---|
|
carbon.storelocation |
/user/hive/warehouse/carbon.store |
定位CarbonData创建存储并以自有格式写入数据的位置。建议不要修改默认路径。 说明:
存储位置应位于HDFS上。 |
|
carbon.ddl.base.hdfs.url |
hdfs://hacluster/opt/data |
此属性用于从HDFS基本路径配置HDFS相对路径,在“fs.defaultFS”中进行配置。在“carbon.ddl.base.hdfs.url”中配置的路径将被追加到在“fs.defaultFS”中配置的HDFS路径中。如果配置了这个路径,则用户不需要通过完整路径加载数据。 例如:如果CSV文件的绝对路径是“hdfs://10.18.101.155:54310/data/cnbc/2016/xyz.csv”,其中,路径“hdfs://10.18.101.155:54310”来源于属性“fs.defaultFS”并且用户可以把“/data/cnbc/”作为“carbon.ddl.base.hdfs.url”配置。 当前,在数据加载时,用户可以指定CSV文件为“/2016/xyz.csv”。 |
|
carbon.badRecords.location |
- |
指定Bad records的存储路径。此路径为HDFS路径。默认值为Null。如果启用了bad records日志记录或者bad records操作重定向,则该路径必须由用户进行配置。 |
|
carbon.bad.records.action |
fail |
以下是bad records的四种行为类型: FORCE:通过将bad records存储为NULL来自动更正数据。 REDIRECT:Bad records被写入原始CSV文件而不是被加载。 IGNORE:Bad records既不被加载也不被写入原始CSV文件。 FAIL:如果找到任何bad records,则数据加载失败。 |
|
carbon.data.file.version |
3 |
如果该参数值设置为1或2,则CarbonData支持旧的格式的数据加载。如果该参数值设置为3,则CarbonData只支持新的格式的数据加载。 |
|
carbon.update.sync.folder |
/tmp/carbondata |
modifiedTime.mdt文件路径,可以设置为已有路径或新路径。 说明:
如果设置为已有路径,需确保所有用户都可以访问该路径,且该路径具有777权限。 |
|
参数 |
默认值 |
描述 |
|---|---|---|
|
数据加载配置 |
||
|
carbon.sort.file.buffer.size |
10 |
在排序过程中使用的文件读取缓冲区大小。单位为MB。 最小值=1,最大值=100。 |
|
carbon.graph.rowset.size |
100000 |
数据加载图步骤之间交换的行集大小。 最小值=500,最大值=1000000 |
|
carbon.number.of.cores.while.loading |
2 |
数据加载时所使用的核数。配置的核数越大压缩性能越好。如果CPU资源充足可以增加此值。 |
|
carbon.sort.size |
100000 |
内存排序的数据大小。 |
|
carbon.enableXXHash |
true |
用于hashkey计算的hashmap算法。 |
|
carbon.number.of.cores.block.sort |
7 |
数据加载时块排序所使用的核数。 |
|
carbon.max.driver.lru.cache.size |
-1 |
在driver端加载数据所达到的最大LRU缓存大小。以MB为单位,默认值为-1,表示缓存没有内存限制。只允许使用大于0的整数值。 |
|
carbon.max.executor.lru.cache.size |
-1 |
在executor端加载数据所达到的最大LRU缓存大小。以MB为单位,默认值为-1,表示缓存没有内存限制。只允许使用大于0的整数值。如果未配置该参数,则将考虑参数“carbon.max.driver.lru.cache.size”的值。 |
|
carbon.merge.sort.prefetch |
true |
在数据加载过程中,从排序的临时文件中读取数据进行合并排序时,启用数据预取。 |
|
carbon.update.persist.enable |
true |
启用此参数将考虑持久化数据,减少UPDATE操作的执行时间。 |
|
enable.unsafe.sort |
true |
指定在数据加载期间是否使用非安全排序。非安全的排序减少了数据加载操作期间的垃圾回收(GC),从而提高了性能。默认值为“true”,表示启用非安全排序功能。 |
|
enable.offheap.sort |
true |
在数据加载期间启用堆排序。 |
|
offheap.sort.chunk.size.inmb |
64 |
指定需要用于排序的数据块的大小。最小值为1MB,最大值为1024MB。 |
|
carbon.unsafe.working.memory.in.mb |
512 |
指定非安全工作内存的大小。这将用于排序数据,存储列页面等。单位是MB。 数据加载所需内存: (“carbon.number.of.cores.while.loading”的值[默认值 = 6]) x 并行加载数据的表格 x (“offheap.sort.chunk.size.inmb”的值[默认值 = 64 MB] + “carbon.blockletgroup.size.in.mb”的值[默认值 = 64 MB] + 当前的压缩率[64 MB/3.5]) = ~900 MB 每表格 数据查询所需内存: (SPARK_EXECUTOR_INSTANCES. [默认值 = 2]) x ( carbon.blockletgroup.size.in.mb [默认值 = 64 MB] +“carbon.blockletgroup.size.in.mb”解压内容[默认值 = 64 MB * 3.5]) x (每个执行器核数[默认值 = 1]) = ~ 600 MB |
|
carbon.sort.inmemory.storage.size.in.mb |
512 |
指定要存储在内存中的中间排序数据的大小。达到该指定的值,系统会将数据写入磁盘。单位是MB。 |
|
sort.inmemory.size.inmb |
1024 |
指定要保存在内存中的中间排序数据的大小。达到该指定值后,系统会将数据写入磁盘。单位:MB。 如果配置了“carbon.unsafe.working.memory.in.mb”和“carbon.sort.inmemory.storage.size.in.mb”,则不需要配置该参数。如果此时也配置了该参数,那么这个内存的20%将用于工作内存“carbon.unsafe.working.memory.in.mb”,80%将用于排序存储内存“carbon.sort.inmemory.storage.size.in.mb”。 说明:
Spark配置参数“spark.yarn.executor.memoryOverhead”的值应该大于CarbonData配置参数“sort.inmemory.size.inmb”的值,否则如果堆外(off heap)访问超出配置的executor内存,则YARN可能会停止executor。 |
|
carbon.blockletgroup.size.in.mb |
64 |
数据作为blocklet group被系统读入。该参数指定blocklet group的大小。较高的值会有更好的顺序IO访问性能。 最小值为16MB,任何小于16MB的值都将重置为默认值(64MB)。 单位:MB。 |
|
enable.inmemory.merge.sort |
false |
指定是否启用内存合并排序(inmemorymerge sort)。 |
|
use.offheap.in.query.processing |
true |
指定是否在查询处理中启用offheap。 |
|
carbon.load.sort.scope |
local_sort |
指定加载操作的排序范围。支持两种类型的排序,batch_sort和local_sort。选择batch_sort将提升加载性能,但会降低查询性能。 |
|
carbon.batch.sort.size.inmb |
- |
指定在数据加载期间为批处理排序而考虑的数据大小。推荐值为小于总排序数据的45%。该值以MB为单位。 说明:
如果没有设置参数值,那么默认情况下其大约等于“sort.inmemory.size.inmb”参数值的45%。 |
|
enable.unsafe.columnpage |
true |
指定在数据加载或查询期间,是否将页面数据保留在堆内存中,以避免垃圾回收受阻。 |
|
carbon.insert.persist.enable |
false |
从源表到目标表的Insert操作正在进行时,无法在源表中加载或更新数据。要在Insert操作期间启用数据加载或更新,请将此参数设置为“true”。 |
|
carbon.use.local.dir |
false |
是否使用YARN本地目录加载多个磁盘的数据。设置为true,则使用YARN本地目录加载多个磁盘的数据,以提高数据加载性能。 |
|
carbon.use.multiple.temp.dir |
false |
是否使用多个临时目录存储临时文件以提高数据加载性能。 |
|
压缩配置 |
||
|
carbon.number.of.cores.while.compacting |
2 |
在压缩过程中用于写入数据所使用的核数。配置的核数越大压缩性能越好。如果CPU资源充足可以增加此值。 |
|
carbon.compaction.level.threshold |
4,3 |
该属性用于Minor压缩,决定合并segment的数量。 例如:如果被设置为“2,3”,则将每2个segment触发一次Minor压缩。“3”是Level 1压缩的segment个数,这些segment将进一步被压缩为新的segment。 有效值为0-100。 |
|
carbon.major.compaction.size |
1024 |
使用该参数配置Major压缩的大小。总数低于该阈值的segment将被合并。 单位为MB。 |
|
carbon.horizontal.compaction.enable |
true |
该参数用于配置打开/关闭水平压缩。在每个DELETE和UPDATE语句之后,如果增量(DELETE / UPDATE)文件超过指定的阈值,则可能发生水平压缩。默认情况下,该参数值设置为“true”,打开水平压缩功能,可将参数值设置为“false”来关闭水平压缩功能。 |
|
carbon.horizontal.update.compaction.threshold |
1 |
该参数指定segment内的UPDATE增量文件数的阈值限制。在增量文件数量超过阈值的情况下,segment内的UPDATE增量文件变得适合水平压缩,并压缩为单个UPDATE增量文件。默认情况下,该参数值设置为1。可以设置为1到10000之间的值。 |
|
carbon.horizontal.delete.compaction.threshold |
1 |
该参数指定segment的block中的DELETE增量文件数量的阈值限制。在增量文件数量超过阈值的情况下,segment特定block的DELETE增量文件变得适合水平压缩,并压缩为单个DELETE增量文件。 默认情况下,该参数值设置为1。可以设置为1到10000之间的值。 |
|
查询配置 |
||
|
carbon.number.of.cores |
4 |
查询时所使用的核数。 |
|
carbon.limit.block.distribution.enable |
false |
当查询语句中包含关键字limit时,启用或禁用CarbonData块分布。默认值为“false”,将对包含关键字limit的查询语句禁用块分布。此参数调优请参考性能调优的相关配置。 |
|
carbon.custom.block.distribution |
false |
指定是使用Spark还是CarbonData的块分配功能。默认情况下,其配置值为“false”,表明启用Spark块分配。若要使用CarbonData块分配,请将配置值更改为“true”。 |
|
carbon.infilter.subquery.pushdown.enable |
false |
如果启用此参数,并且用户在具有subquery的过滤器中触发Select查询,则执行子查询,并将输出作为IN过滤器广播到左表,否则将执行SortMergeSemiJoin。建议在IN过滤器子查询未返回太多记录时启用此参数。例如,IN子句子查询返回10k或更少的记录时,启用此参数将更快地给出查询结果。 示例:select * from flow_carbon_256b where cus_no in (select cus_no from flow_carbon_256b where dt>=‘20260101‘ and dt<=‘20260701‘ and txn_bk=‘tk_1‘ and txn_br=‘tr_1‘) limit 1000; |
|
carbon.scheduler.minRegisteredResourcesRatio |
0.8 |
启动块分布所需的最小资源(executor)比率。默认值为“0.8”,表示所请求资源的80%被分配用于启动块分布。 |
|
carbon.dynamicAllocation.schedulerTimeout |
5 |
此参数值指示调度器等待executors处于活动状态的最长时间。默认值为“5”秒,允许的最大值为“15”秒。 |
|
enable.unsafe.in.query.processing |
true |
指定在查询操作期间是否使用非安全排序。非安全排序减少查询操作期间的垃圾回收(GC),从而提高性能。默认值为“true”,表示启用非安全排序功能。 |
|
carbon.enable.vector.reader |
true |
为结果收集(result collection)启用向量处理,以增强查询性能。 |
|
二级索引配置 |
||
|
carbon.secondary.index.creation.threads |
1 |
该参数用于配置启动二级索引创建期间并行处理segments的线程数。当表的segments数较多时,该参数有助于微调系统生成二级索引的速度。该参数值范围为1到50。 |
|
carbon.si.lookup.partialstring |
true |
|
|
参数 |
默认值 |
描述 |
|---|---|---|
|
数据加载配置 |
||
|
carbon.sort.file.write.buffer.size |
10485760 |
排序过程用于文件写缓冲区的大小。单位:Byte。 |
|
carbon.lock.type |
HDFSLOCK |
该配置指定了表上并发操作过程中所要求的锁的类型。 有以下几种类型锁实现方式:
|
|
carbon.sort.intermediate.files.limit |
20 |
中间文件的最小数量。生成中间文件后开始排序合并。此参数调优请参考性能调优的相关配置。 |
|
carbon.csv.read.buffersize.byte |
1048576 |
CSV读缓冲区大小。 |
|
carbon.merge.sort.reader.thread |
3 |
用于读取中间文件进行最终合并的最大线程数。 |
|
carbon.concurrent.lock.retries |
100 |
指定获取并发操作锁的最大重试次数。该参数用于并发加载。 |
|
carbon.concurrent.lock.retry.timeout.sec |
1 |
指定获取并发操作的锁重试之间的间隔。 |
|
carbon.lock.retries |
3 |
指定除导入操作外其他所有操作尝试获取锁的次数。 |
|
carbon.lock.retry.timeout.sec |
5 |
指定除导入操作外其他所有操作尝试获取锁的时间间隔。 |
|
carbon.tempstore.location |
/opt/Carbon/TempStoreLoc |
临时存储位置。默认情况下,采用“System.getProperty("java.io.tmpdir")”方法获取。此参数调优请参考性能调优的相关配置中关于“carbon.use.local.dir”的描述。 |
|
carbon.load.log.counter |
500000 |
数据加载记录计数日志。 |
|
SERIALIZATION_NULL_FORMAT |
\N |
指定需要替换为NULL的值。 |
|
carbon.skip.empty.line |
false |
设置此属性将在数据加载期间忽略CSV文件中的空行。 |
|
合并配置 |
||
|
carbon.numberof.preserve.segments |
0 |
若用户希望从被合并的segment中保留一定数量的segment,可设置该属性参数。 例如:“carbon.numberof.preserve.segments”=“2”,那么合并的segement中将不包含最新的2个segment。 默认保留No segment的状态。 |
|
carbon.allowed.compaction.days |
0 |
合并将合并在配置的指定天数中加载的segment。 例如:如果配置值为“2”,那么只有在2天时间框架中加载的segment被合并。2天以外被加载的segment不会被合并。 该参数默认为禁用。 |
|
carbon.enable.auto.load.merge |
false |
在数据加载时启用压缩。 |
|
carbon.merge.index.in.segment |
true |
如果设置,则Segment内的所有Carbon索引文件(.carbonindex)将合并为单个Carbon索引合并文件(.carbonindexmerge)。 这增强了首次查询性能 |
|
查询配置 |
||
|
max.query.execution.time |
60 |
单次查询允许的最大时间。 单位为分钟。 |
|
carbon.enableMinMax |
true |
MinMax用于提高查询性能。设置为false可禁用该功能。 |
|
carbon.lease.recovery.retry.count |
5 |
需要为恢复文件租约所需的最大尝试次数。 最小值:1 最大值:50 |
|
carbon.lease.recovery.retry.interval |
1000 (ms) |
尝试在文件上进行租约恢复之后的间隔(Interval)或暂停(Pause)时间。 最小值:1000(ms) 最大值:10000(ms) |
|
全局字典配置 |
||
|
high.cardinality.identify.enable |
true |
如果该参数为“true”,将自动识别字典编码列中的high cardinality列,系统不在这些列上做全局字典编码。如果为“false”,则所有字典编码列都会做字典编码。 High cardinality列必须满足以下要求: 列的cardinality值 > “high.cardinality”的配置项值
|
|
high.cardinality.threshold |
1000000 |
确定是否为high cardinality列的阈值。 配置值需满足以下条件: 列的cardinality值 > “high.cardinality”的配置值 最小值为10000。 |
|
carbon.cutOffTimestamp |
1970-01-01 05:30:00 |
设置用于计算时间戳的起始日期,Java从“1970-01-01 00:00:00”开始计算毫秒数,该属性被用于定制时间的开始,例如“2000-01-01 00:00:00”。该日期必须为“carbon.timestamp.format”格式。 说明:
CarbonData可以从定义的截止时间开始将数据保存68年。例如,如果截止时间是1970-01-01 05:30:00,那么数据可以保存到2038-01-01 05:30:00。 |
|
carbon.timegranularity |
SECOND |
该属性用于设置数据粒度级别,例如,DAY,HOUR,MINUTE,或者SECOND。 |
|
参数 |
默认值 |
描述 |
|---|---|---|
|
spark.driver.memory |
512M |
指定用于driver端进程的内存,其中SparkContext已初始化。 说明:
在客户端模式下,不要使用SparkConf在应用程序中设置该参数,因为驱动程序JVM已经启动。要配置该参数,请在--driver-memory命令行选项或默认属性文件中进行配置。 |
|
spark.executor.memory |
1G |
指定每个执行程序进程使用的内存。 |
|
spark.sql.crossJoin.enable |
false |
如果查询包含交叉连接,请启用此属性,以便不会抛出错误,此时使用交叉连接而不是连接,可实现更好的性能。 |
在Spark Driver端的“spark-defaults.conf”文件中配置以下参数。
|
参数 |
配置值 |
描述 |
|---|---|---|
|
spark.driver.extraJavaOptions |
-Dcarbon.properties.filepath=/opt/client/Spark2x/spark/conf/carbon.properties |
默认值中“/opt/client/Spark2x/spark”为客户端的CLIENT_HOME,且该默认值是追加到参数“spark.driver.extraJavaOptions”其他值之后的,此参数用于指定Driver端的“carbon.properties”文件路径。 说明:
请注意“=”两边不要有空格。 |
|
spark.sql.session.state.builder |
org.apache.spark.sql.hive.CarbonACLInternalSessionStateBuilder |
指定会话状态构造器。 |
|
spark.carbon.sqlastbuilder.classname |
org.apache.spark.sql.hive.CarbonInternalSqlAstBuilder |
指定AST构造器。 |
|
spark.sql.catalog.class |
org.apache.spark.sql.hive.HiveACLExternalCatalog |
指定Hive的外部目录实现。启用Spark ACL时必须提供。 |
|
spark.sql.hive.implementation |
org.apache.spark.sql.hive.HiveACLClientImpl |
指定Hive客户端调用的实现。启用Spark ACL时必须提供。 |
|
spark.sql.hiveClient.isolation.enabled |
false |
启用Spark ACL时必须提供。 |
|
参数 |
配置值 |
描述 |
|---|---|---|
|
spark.driver.extraJavaOptions |
-Xloggc:${SPARK_LOG_DIR}/jdbcserver-omm-%p-gc.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:MaxDirectMemorySize=512M -XX:MaxMetaspaceSize=512M -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=20 -XX:GCLogFileSize=10M -XX:OnOutOfMemoryError=‘kill -9 %p‘ -Djetty.version=x.y.z -Dorg.xerial.snappy.tempdir=${BIGDATA_HOME}/tmp/spark2x/JDBCServer/snappy_tmp -Djava.io.tmpdir=${BIGDATA_HOME}/tmp/spark2x/JDBCServer/io_tmp -Dcarbon.properties.filepath=${SPARK_CONF_DIR}/carbon.properties -Djdk.tls.ephemeralDHKeySize=2048 |
默认值中${SPARK_CONF_DIR}需视具体的集群而定,且该默认值是追加到参数“spark.driver.extraJavaOptions”其他值之后的,此参数用于指定Driver端的“carbon.properties”文件路径。 说明:
请注意“=”两边不要有空格。 |
|
spark.sql.session.state.builder |
org.apache.spark.sql.hive.CarbonACLInternalSessionStateBuilder |
指定会话状态构造器。 |
|
spark.carbon.sqlastbuilder.classname |
org.apache.spark.sql.hive.CarbonInternalSqlAstBuilder |
指定AST构造器。 |
|
spark.sql.catalog.class |
org.apache.spark.sql.hive.HiveACLExternalCatalog |
指定Hive的外部目录实现。启用Spark ACL时必须提供。 |
|
spark.sql.hive.implementation |
org.apache.spark.sql.hive.HiveACLClientImpl |
指定Hive客户端调用的实现。启用Spark ACL时必须提供。 |
|
spark.sql.hiveClient.isolation.enabled |
false |
启用Spark ACL时必须提供。 |
本章节介绍创建CarbonData table、加载数据,以及查询数据的快速入门流程。该快速入门提供基于Spark Beeline客户端的操作。如果使用Spark shell,需将查询命令写在sc.sql()的括号中。
|
在对CarbonData进行任何一种操作之前,首先需要连接到CarbonData。 |
|
|
连接到CarbonData之后,需要创建CarbonData table用于加载数据和执行查询操作。 |
|
|
创建CarbonData table之后,可以从CSV文件加载数据到所创建的table中。 |
|
|
创建CarbonData table并加载数据之后,可以执行所需的查询操作,例如filters,groupby等。 |
或者
用户应该属于数据加载组,以完成数据加载操作。默认数据加载组名为“ficommon”。
在Spark Beeline被连接到JDBCServer之后,需要创建一个CarbonData table用于加载数据和执行查询操作。下面是创建一个简单的表的命令。
create table x1 (imei string, deviceInformationId int, mac string, productdate timestamp, updatetime timestamp, gamePointId double, contractNumber double) STORED BY ‘org.apache.carbondata.format‘ TBLPROPERTIES (‘DICTIONARY_EXCLUDE‘=‘mac‘, ‘DICTIONARY_INCLUDE‘=‘deviceInformationId‘, ‘SORT_COLUMNS‘=‘imei,mac‘);
命令执行结果如下:
+---------+--+ | result | +---------+--+ +---------+--+ No rows selected (1.551 seconds)
创建CarbonData table之后,可以从CSV文件加载数据到所创建的表中。
以从CSV文件加载数据到CarbonData Table为例
用所要求的参数运行以下命令从CSV文件加载数据。该表的列名需要与CSV文件的列名匹配。
LOAD DATA inpath ‘hdfs://hacluster/data/x1_without_header.csv‘ into table x1 options(‘DELIMITER‘=‘,‘, ‘QUOTECHAR‘=‘"‘,‘FILEHEADER‘=‘imei, deviceinformationid,mac, productdate,updatetime, gamepointid,contractnumber‘);
其中,“x1_without_header.csv”为示例的CSV文件,“x1”为示例的表名。
CSV样例内容如下:
13418592122,1001,28-6E-D4-89-16-D0,2017-10-23 15:32:30,2017-10-24 15:32:30,62.50,74.56 13418592123,1002,28-6E-D4-89-17-D0,2017-10-23 16:32:30,2017-10-24 16:32:30,17.80,76.28 13418592124,1003,28-6E-D4-89-16-D1,2017-10-23 17:32:30,2017-10-24 17:32:30,20.40,92.94 13418592125,1004,28-6E-D4-89-17-D1,2017-10-23 18:32:30,2017-10-24 18:32:30,73.84,8.58 13418592126,1005,28-6E-D4-89-16-D2,2017-10-23 19:32:30,2017-10-24 19:32:30,80.50,88.02 13418592127,1006,28-6E-D4-89-17-D2,2017-10-23 20:32:30,2017-10-24 20:32:30,65.77,71.24 13418592128,1007,28-6E-D4-89-16-D3,2017-10-23 21:32:30,2017-10-24 21:32:30,75.21,76.04 13418592129,1008,28-6E-D4-89-17-D3,2017-10-23 22:32:30,2017-10-24 22:32:30,63.30,94.40 13418592130,1009,28-6E-D4-89-16-D4,2017-10-23 23:32:30,2017-10-24 23:32:30,95.51,50.17 13418592131,1010,28-6E-D4-89-17-D4,2017-10-24 00:32:30,2017-10-25 00:32:30,39.62,99.13
命令执行结果如下:
+---------+--+ | Result | +---------+--+ +---------+--+ No rows selected (3.039 seconds)
创建CarbonData table并加载数据之后,可以执行所需的数据查询操作。以下为一些查询操作举例。
为了获取在CarbonData table中的记录数,可以运行以下命令。
select count(*) from x1;
为了获取不重复的deviceinformationid记录数,可以运行以下命令。
select deviceinformationid,count (distinct deviceinformationid) from x1 group by deviceinformationid;
为了获取特定deviceinformationid的记录,可以运行以下命令。
select * from x1 where deviceinformationid=‘10‘;
在执行数据查询操作后,如果查询结果中某一列的结果含有中文字等非英文字符,会导致查询结果中的列不能对齐,这是由于不同语言的字符在显示时所占的字宽不尽相同。
用户若需要在Spark-shell上使用CarbonData,需通过如下方式进行创建CarbonData Table,加载数据到CarbonData Table和在CarbonData中查询数据的操作。
spark.sql("CREATE TABLE x2(imei string, deviceInformationId int, mac string, productdate timestamp, updatetime timestamp, gamePointId double, contractNumber double) STORED BY ‘org.apache.carbondata.format‘")
spark.sql("LOAD DATA inpath ‘hdfs://hacluster/data/x1_without_header.csv‘ into table x2 options(‘DELIMITER‘=‘,‘, ‘QUOTECHAR‘=‘"‘,‘FILEHEADER‘=‘imei, deviceinformationid,mac, productdate,updatetime, gamepointid,contractnumber‘)")
spark.sql("SELECT * FROM x2").show()
CarbonData中的数据存储在table实体中。CarbonData table与RDBMS中的表类似。RDBMS数据存储在由行和列构成的表中。CarbonData table存储的也是结构化的数据,拥有固定列和数据类型。
CarbonData支持以下数据类型:
下表对所支持的数据类型及其各自的范围进行了详细说明。
|
数据类型 |
范围 |
|---|---|
|
Int |
4字节有符号整数,从-2,147,483,648到2,147,483,647 说明:
非字典列如果是Int类型,会在内部存储为BigInt类型。 |
|
String |
100000字符 说明:
如果在CREATE TABLE中使用CHAR或VARCHAR数据类型,则这两种数据类型将自动转换为String数据类型。 |
|
BigInt |
64-bit,从-9,223,372,036,854,775,808到9,223,372,036,854,775,807 |
|
SmallInt |
范围-32,768到32,767 |
|
Char |
范围A到Z&a到z |
|
Varchar |
范围A到Z&a到z&0到9 |
|
Boolean |
范围true或者false |
|
Decimal |
默认值是(10,0) ,最大值是(38,38) 说明:
当进行带过滤条件的查询时,为了得到准确的结果,需要在数字后面加上BD。例如,select * from carbon_table where num = 1234567890123456.22BD. |
|
Double |
64-bit,从4.9E-324到1.7976931348623157E308 |
|
TimeStamp |
NA,默认格式为“yyyy-MM-dd HH:mm:ss”。 |
|
Date |
DATE数据类型用于存储日历日期。 默认格式为“yyyy-MM-DD”。 |
使用CarbonData前需先创建表,才可在其中加载数据和查询数据。可通过Create Table命令来创建表。该命令支持使用自定义列创建表。
可通过指定各列及其数据类型来创建表。
命令示例:
CREATE TABLE IF NOT EXISTS productdb.productSalesTable (
productNumber Int,
productName String,
storeCity String,
storeProvince String,
productCategory String,
productBatch String,
saleQuantity Int,
revenue Int)
STORED BY ‘org.apache.carbondata.format‘
TBLPROPERTIES (
‘table_blocksize‘=‘128‘,
‘DICTIONARY_EXCLUDE‘=‘productName‘,
‘DICTIONARY_INCLUDE‘=‘productNumber‘);
上述命令所创建的表的详细信息如下:
|
参数 |
描述 |
|---|---|
|
productSalesTable |
待创建的表的名称。该表用于加载数据进行分析。 表名由字母、数字、下划线组成。 |
|
productdb |
数据库名称。该数据库将与其中的表保持逻辑连接以便于识别和管理。 数据库名称由字母、数字、下划线组成。 |
|
productName storeCity storeProvince procuctCategory productBatch saleQuantity revenue |
表中的列,代表执行分析所需的业务实体。 列名(字段名)由字母、数字、下划线组成。 |
|
table_blocksize |
CarbonData表使用的数据文件的block大小,默认值为1024,最小值为1,最大值为2048,单位为MB。 如果“table_blocksize”值太小,数据加载时,生成过多的小数据文件,可能会影响HDFS的使用性能。 如果“table_blocksize”值太大,数据查询时,索引匹配的block数据量较大,某些block会包含较多的blocklet,导致读取并发度不高,从而降低查询性能。 一般情况下,建议根据数据量级别来选择大小。例如:GB级别用256,TB级别用512,PB级别用1024。
|
|
DICTIONARY_EXCLUDE |
不生成字典。适用于high-cardinality列,系统默认的行为是为string类型的列做字典编码,但是,如果字典值过多,会导致字典转换操作成为性能瓶颈,反而降低了性能。一般情况下,列的cardinality高于5万,可以被认定为high-cardinality,应该使用DICTIONARY_EXCLUDE排除掉字典编码,该参数为可选参数。 说明:
|
|
DICTIONARY_INCLUDE |
对指定列生成字典。适用于非high-cardinality列,可以提升字典列上的groupby性能,为可选参数。一般情况下,DICTIONARY_INCLUDE包含的列的cardinality不应该高于5万。 |
根据命令创建表。
可使用DROP TABLE命令删除表。删除表后,所有metadata以及表中已加载的数据都会被删除。
运行如下命令删除表。
命令:
DROP TABLE [IF EXISTS] [db_name.]table_name;
一旦执行该命令,将会从系统中删除表。命令中的“db_name”为可选参数。如果没有指定“db_name”,那么将会删除当前数据库下名为“table_name”的表。
示例:
DROP TABLE productdb.productSalesTable;
通过上述命令,删除数据库“productdb”下的表“productSalesTable”。
从系统中删除命令中指定的表。删除完成后,可通过SHOW TABLES命令进行查询,确认所需删除的表是否成功被删除,详见SHOW TABLES。
CarbonData table创建成功后,可使用LOAD DATA命令在表中加载数据,并可供查询。触发数据加载后,数据以CarbonData格式进行编码,并将多维列式存储格式文件压缩后复制到存储CarbonData文件的HDFS路径下供快速分析查询使用。HDFS路径可以配置在carbon.properties文件中。具体请参考配置参考。
一个表一次只能触发一个数据加载。系统默认自动识别字典编码列中的high cardinality column,将不会为这些列生成全局字典,具体请参考配置参考。
数据文件的内容样例如下:
1001,pn1001,sc1001,sp1001,pc1001,pb1001,132,976 1002,pn1002,sc1002,sp1002,pc1002,pb1002,480,268 1003,pn1003,sc1003,sp1003,pc1003,pb1003,291,79 1004,pn1004,sc1004,sp1004,pc1004,pb1004,772,328 1005,pn1005,sc1005,sp1005,pc1005,pb1005,777,676 1006,pn1006,sc1006,sp1006,pc1006,pb1006,463,176 1007,pn1007,sc1007,sp1007,pc1007,pb1007,226,967 1008,pn1008,sc1008,sp1008,pc1008,pb1008,663,938 1009,pn1009,sc1009,sp1009,pc1009,pb1009,940,394 1010,pn1010,sc1010,sp1010,pc1010,pb1010,656,110
source /opt/ficlient/bigdata_env
source /opt/ficlient/Spark2x/component_env
kinit test_carbon
hadoop fs -put /opt/ficlient/test.csv /tmp
CREATE TABLE IF NOT EXISTS productSalesTable ( productNumber Int, productName String, storeCity String, storeProvince String, productCategory String, productBatch String, saleQuantity Int, revenue Int) STORED BY ‘org.apache.carbondata.format‘ TBLPROPERTIES ( ‘table_blocksize‘=‘128‘, ‘DICTIONARY_EXCLUDE‘=‘productName‘, ‘DICTIONARY_INCLUDE‘=‘productNumber‘);
LOAD DATA inpath ‘hdfs://hacluster/tmp/test.csv‘ into table productSalesTable options(‘DELIMITER‘=‘,‘, ‘QUOTECHAR‘=‘"‘,‘FILEHEADER‘=‘productNumber, productName,storeCity,storeProvince, productCategory,productBatch, saleQuantity,revenue‘);
OPTIONS是数据加载过程的必选参数。用户可在OPTIONS内根据需要填写DELIMITER、QUOTECHAR、ESCAPECHAR。
数据加载过程涉及读取,排序和以CarbonData存储格式编码日期等各个步骤的执行。每一个步骤将在不同线程中执行。数据加载完成后,将更新CarbonData存储metadata的状态(success/partial success)。
通过SHOW SEGMENTS命令可以查看以下加载详情。
select * from productSalesTable;
如果用户将错误数据加载到表中,或者数据加载后出现许多错误记录,用户希望修改并重新加载数据时,可删除对应的segment。可使用segment ID来删除segment,也可以使用加载数据的时间来删除segment。
删除segment操作只能删除未合并的segment,已合并的segment可以通过CLEAN FILES命令清除segment。
每个Segment都有与其关联的唯一Segment ID。使用这个Segment ID可以删除该Segment。
命令:
SHOW SEGMENTS FOR Table dbname.tablename LIMIT number_of_loads;
示例:
SHOW SEGMENTS FOR TABLE carbonTable;
上述命令可显示tablename为carbonTable的表的所有Segment信息。
SHOW SEGMENTS FOR TABLE carbonTable LIMIT 2;
上述命令可显示number_of_loads规定条数的Segment信息。
输出结果如下:
+-----------------+---------+--------------------+--------------------+---------+ |SegmentSequenceId| Status| Load Start Time| Load End Time|Merged To| +-----------------+---------+--------------------+--------------------+---------+ | 2| Success|2017-08-31 00:15:...|2017-08-31 00:15:...| | | 1|Compacted|2017-08-31 00:13:...|2017-08-31 00:14:...| 0.1| | 0.1| Success|2017-08-31 00:14:...|2017-08-31 00:14:...| | | 0|Compacted|2017-08-31 00:13:...|2017-08-31 00:13:...| 0.1| +-----------------+---------+--------------------+--------------------+---------+
SHOW SEGMENTS命令输出包括SegmentSequenceId、Status、Load Start Time、Load End Time。最新的加载信息在输出中第一行显示。
命令:
DELETE FROM TABLE tableName WHERE SEGMENT.ID IN (load_sequence_id1, load_sequence_id2, ....);
示例:
DELETE FROM TABLE carbonTable WHERE SEGMENT.ID IN (1,2,3);
详细信息,请参阅DELETE SEGMENT by ID。
用户可基于特定的加载时间删除数据。
命令:
DELETE FROM TABLE db_name.table_name WHERE SEGMENT.STARTTIME BEFORE date_value;
示例:
DELETE FROM TABLE carbonTable WHERE SEGMENT.STARTTIME BEFORE ‘2017-07-01 12:07:20‘;
上述命令可删除‘2017-07-01 12:07:20‘之前的所有segment。
有关详细信息,请参阅DELETE SEGMENT by DATE。
数据对应的segment被删除,数据将不能再被访问。可通过SHOW SEGMENTS命令显示segment状态,查看是否成功删除。
示例:
CLEAN FILES FOR TABLE table1;
该命令将从物理上删除状态为“Marked for delete”的Segment文件。
如果在“max.query.execution.time”规定的时间到达之前使用该命令,可能会导致查询失败。“max.query.execution.time”可在“carbon.properties”文件中设置,表示一次查询允许花费的最长时间。
频繁的数据获取导致在存储目录中产生许多零碎的CarbonData文件。由于数据排序只在每次加载时进行,所以,索引也只在每次加载时执行。这意味着,对于每次加载都会产生一个索引,随着数据加载数量的增加,索引的数量也随之增加。由于每个索引只在一次加载时工作,索引的性能被降低。CarbonData提供加载压缩。压缩过程通过合并排序各segment中的数据,将多个segment合并为一个大的segment。
已经加载了多次数据。
有Minor合并和Major合并两种类型。
在Minor合并中,用户可指定合并数据加载的数量。如果设置了参数“carbon.enable.auto.load.merge”,每次数据加载都可触发Minor合并。如果任意segment均可合并,那么合并将于数据加载时并行进行。
Minor合并有两个级别。
在Major合并中,许多segment可以合并为一个大的segment。用户将指定合并尺寸,将对未达到该尺寸的segment进行合并。Major合并通常在非高峰时段进行。
具体的命令操作,请参考ALTER TABLE。
|
参数 |
默认值 |
应用类型 |
描述 |
|---|---|---|---|
|
carbon.enable.auto.load.merge |
false |
Minor |
数据加载时启用合并。 “true”:数据加载时自动触发segment合并合并。 “false”:数据加载时不触发segment合并合并。 |
|
carbon.compaction.level.threshold |
4,3 |
Minor |
对于Minor合并,该属性参数决定合并segment的数量。 例如,如果该参数设置为“2,3”,在Level 1,每2个segment触发一次Minor合并。在Level2,每3个Level 1合并的segment将被再次合并为新的segment。 合并策略根据实际的数据大小和可用资源决定。 有效值为0-100。 |
|
carbon.major.compaction.size |
1024mb |
Major |
通过配置该参数可配置Major合并。低于该阈值的segment之和将被合并。 例如,如果该阈值是1024MB,且有5个大小依次为300MB,400MB,500MB,200MB,100MB的segment用于Major合并,那么只有相加的总数小于阈值的segment会被合并,也就是300+400+200+100 = 1000MB的segment会被合并,而500MB的segment将会被跳过。 |
|
carbon.numberof.preserve.segments |
0 |
Minor/Major |
如果用户希望从被合并的segment中保留一定数量的segment,可通过该属性参数进行设置。 例如,“carbon.numberof.preserve.segments”=“2”,那么最新的2个segment将不会包含在合并中。 默认不保留任何segment。 |
|
carbon.allowed.compaction.days |
0 |
Minor/Major |
合并将合并在指定的配置天数中加载的segment。 例如,如果配置为“2”,那么只有在2天的时间框架中被加载的segment可以被合并。在2天以外被加载的segment将不被合并。 默认为禁用。 |
|
carbon.number.of.cores.while.compacting |
2 |
Minor/Major |
在合并过程中写入数据时所用的核数。配置的核数越大合并性能越好。如果CPU资源充足可以增加此值。 |
|
carbon.merge.index.in.segment |
true |
SEGMENT_INDEX |
如果设置为true,则一个segment中所有Carbon索引文件(.carbonindex)将合并为单个Carbon索引合并文件(.carbonindexmerge)。 这增强了首次查询性能。 |
建议避免对历史数据进行minor compaction,请参考如何避免对历史数据进行minor compaction?
如果用户需要快速从一个集群中将CarbonData的数据迁移到另外一个集群的CarbonData中,可以使用CarbonData的数据备份与恢复命令来完成该任务。使用此方法迁移数据,无需在新集群执行数据导入的过程,可以减少迁移的时间。
两个集群已安装Spark2x客户端。假设原始数据所在集群为A,需要迁移到集群B。
beeline
desc formatted 原始数据的表名称;
查看系统显示的信息中“Location”表示数据文件所在目录。
在集群B上传数据时,上传目录中需要存在与原始目录有相同的数据库以及表名目录。
例如,原始数据保存在“/user/carboncadauser/warehouse/db1/tb1”,则在新集群中数据可以保存在“/user/carbondatauser2/warehouse/db1/tb1”中。
REFRESH TABLE $dbName.$tbName;
$dbName和$tbName分别表示数据对应的数据库名称以及表名称。
REGISTER INDEX TABLE $tableName ON $maintable;
$tableName和$maintable分别表示索引表名称和表名称。
本章节根据超过50个测试用例总结得出建议,帮助用户创建拥有更高查询性能的CarbonData表。
|
Column name |
Data type |
Cardinality |
Attribution |
|---|---|---|---|
|
msisdn |
String |
3千万 |
dimension |
|
BEGIN_TIME |
bigint |
1万 |
dimension |
|
host |
String |
1百万 |
dimension |
|
dime_1 |
String |
1千 |
dimension |
|
dime_2 |
String |
500 |
dimension |
|
dime_3 |
String |
800 |
dimension |
|
counter_1 |
numeric(20,0) |
NA |
measure |
|
... |
... |
NA |
measure |
|
counter_100 |
numeric(20,0) |
NA |
measure |
针对此类场景,调优方法如下:
将常用于过滤的列放在sort_columns第一列。
例如,msisdn作为过滤条件在查询中使用的最多,则将其放在第一列,因为msisdn的Cardinality为3千万,所以不需要做字典编码。创建表的命令如下,其中采用msisdn作为过滤条件的查询性能将会很好。
create table carbondata_table(
msisdn String,
...
)STORED BY ‘org.apache.carbondata.format‘ TBLPROPERTIES (‘SORT_COLUMS‘=‘msisdn‘,‘DICTIONARY_EXCLUDE‘=‘msisdn,..‘,‘DICTIONARY_INCLUDE‘=‘...‘);
针对此类场景,调优方法如下:
为常用的过滤列创建索引。
例如,如果msisdn,host和dime_1是过滤经常使用的列,根据cardinality,sort_columns列的顺序是dime_1-> host-> msisdn…;因为msisdn和host的Cardinality超过百万,所以不需要创建字典编码。创建表命令如下,以下命令可提高dime_1,host和msisdn上的过滤性能和压缩率。
create table carbondata_table(
dime_1 String,
host String,
msisdn String,
dime_2 String,
dime_3 String,
...
)STORED BY ‘org.apache.carbondata.format‘
TBLPROPERTIES (‘SORT_COLUMS‘=‘dime_1,host,msisdn‘,‘DICTIONARY_EXCLUDE‘=‘msisdn,host..‘,‘DICTIONARY_INCLUDE‘=‘dime_1..‘);
针对此类场景,调优方法如下:
sort_columns按照cardinality从低到高的顺序排列,并对高Cardinality列不做字典编码。
创建表的命令如下:
create table carbondata_table(
Dime_1 String,
BEGIN_TIME bigint,
HOST String,
MSISDN String,
...
)STORED BY ‘org.apache.carbondata.format‘
TBLPROPERTIES (‘SORT_COLUMS‘=‘dime_2,dime_3,dime_1, BEGIN_TIME,host,msisdn‘ ‘DICTIONARY_EXCLUDE‘=‘MSISDN,HOST,..‘,‘DICTIONARY_INCLUDE‘=‘Dime_1,BEGIN_TIME..‘);
create index carbondata_table_index_msidn on tablecarbondata_table ( MSISDN String) as ‘org.apache.carbondata.format‘ TBLPROPERTIES (‘table_blocksize‘=‘128‘); create index carbondata_table_index_host on tablecarbondata_table ( host String) as ‘org.apache.carbondata.format‘ TBLPROPERTIES (‘table_blocksize‘=‘128‘);
在一个测试用例中,使用double来替换numeric (20, 0),查询时间从15秒降低到3秒,查询速度提高了5倍。创建表命令如下:
create table carbondata_table(
Dime_1 String,
BEGIN_TIME bigint,
HOST String,
MSISDN String,
counter_1 double,
counter_2 double,
...
counter_100 double,
)STORED BY ‘org.apache.carbondata.format‘
TBLPROPERTIES ( ‘DICTIONARY_EXCLUDE‘=‘MSISDN,HOST,IMSI‘,‘DICTIONARY_INCLUDE‘=‘Dime_1,END_TIME,BEGIN_TIME‘);
例如,每天将数据加载到CarbonData,start_time是每次加载的增量。对于这种情况,建议将start_time列放在sort_columns的最后,因为总是递增的值可以始终使用最小/最大索引。创建表命令如下:
create table carbondata_table(
Dime_1 String,
HOST String,
MSISDN String,
counter_1 double,
counter_2 double,
BEGIN_TIME bigint,
...
counter_100 double,
)STORED BY ‘org.apache.carbondata.format‘
TBLPROPERTIES ( ‘SORT_COLUMS‘=‘dime_2,dime_3,dime_1..BEGIN_TIME‘,‘DICTIONARY_EXCLUDE‘=‘MSISDN,HOST,IMSI‘,‘DICTIONARY_INCLUDE‘=‘Dime_1,END_TIME,BEGIN_TIME‘);
对于维度是否需要生成字典,建议在没有足够的内存的情况下,不要把高cardinality列当作字典列。对高cardinality列生成字典会影响加载性能,需要更多的内存。CarbonData的默认行为是:CarbonData会对第一次数据加载的cardinality进行判断,如果cardinality小于100万,则生成字典。
CarbonData的性能与配置参数相关,本章节提供了能够提升性能的相关配置介绍。
用于CarbonData查询的配置介绍,详情请参见表1和表2。
|
参数 |
spark.sql.shuffle.partitions |
|---|---|
|
所属配置文件 |
spark-defaults.conf |
|
适用于 |
数据查询 |
|
场景描述 |
Spark shuffle时启动的Task个数。 |
|
如何调优 |
一般建议将该参数值设置为执行器核数的1到2倍。例如,在聚合场景中,将task个数从200减少到32,有些查询的性能可提升2倍。 |
|
参数 |
SPARK_EXECUTOR_CORES SPARK_EXECUTOR_INSTANCES SPARK_EXECUTOR_MEMORY |
|---|---|
|
所属配置文件 |
spark-defaults.conf |
|
适用于 |
数据查询 |
|
场景描述 |
设置用于CarbonData查询的Executor个数、CPU核数以及内存大小。 |
|
如何调优 |
在银行方案中,为每个执行器提供4个CPU内核和15GB内存,可以获得良好的性能。这2个值并不意味着越多越好,在资源有限的情况下,需要正确配置。例如,在银行方案中,每个节点有足够的32个CPU核,而只有64GB的内存,这个内存是不够的。例如,当每个执行器有4个内核和12GB内存,有时在查询期间发生垃圾收集(GC),会导致查询时间从3秒增加到超过15秒。在这种情况下需要增加内存或减少CPU内核。 |
用于CarbonData数据加载的配置参数,详情请参见表3、表4和表5。
|
参数 |
carbon.number.of.cores.while.loading |
|---|---|
|
所属配置文件 |
carbon.properties |
|
适用于 |
数据加载 |
|
场景描述 |
数据加载过程中,设置处理数据使用的CPU core数量。 |
|
如何调优 |
如果有更多的CPU个数,那么可以增加CPU值来提高性能。例如,将该参数值从2增加到4,那么CSV文件读取性能可以增加大约1倍。 |
|
参数 |
carbon.use.local.dir |
|---|---|
|
所属配置文件 |
carbon.properties |
|
适用于 |
数据加载 |
|
场景描述 |
是否使用YARN本地目录进行多磁盘数据加载。 |
|
如何调优 |
如果将该参数值设置为“true”,CarbonData将使用YARN本地目录进行多表加载磁盘负载平衡,以提高数据加载性能。 |
|
参数 |
carbon.use.multiple.temp.dir |
|---|---|
|
所属配置文件 |
carbon.properties |
|
适用于 |
数据加载 |
|
场景描述 |
是否使用多个临时目录存储sort临时文件。 |
|
如何调优 |
设置为true,则数据加载时使用多个临时目录存储sort临时文件。此配置能提高数据加载性能并避免磁盘单点故障。 |
用于CarbonData数据加载和数据查询的配置参数,详情请参见表6。
|
参数 |
carbon.compaction.level.threshold |
|---|---|
|
所属配置文件 |
carbon.properties |
|
适用于 |
数据加载和查询 |
|
场景描述 |
对于minor压缩,在阶段1中要合并的segment数量和在阶段2中要合并的已压缩的segment数量。 |
|
如何调优 |
每次CarbonData加载创建一个segment,如果每次加载的数据量较小,将在一段时间内生成许多小文件,影响查询性能。配置该参数将小的segment合并为一个大的segment,然后对数据进行排序,可提高查询性能。 压缩的策略根据实际的数据大小和可用资源决定。如某银行1天加载一次数据,且加载数据选择在晚上无查询时进行,有足够的资源,压缩策略可选择为6、5。 |
#!/bin/bash nohup bin/spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 1 --executor-memory 1g --executor-cores 1 --conf spark.sql.shuffle.partitions=500 --conf spark.sql.auto.repartition=true --conf spark.shuffle.service.enabled=true --conf spark.executor.memoryOverhead=1g --conf spark.sql.autoBroadcastJoinThreshold=10485760 --class org.apache.carbondata.spark.thriftserver.CarbonThriftServer ../carbonlib/apache-carbondata-1.5.3-bin-spark2.3.2-hadoop2.7.2.jar >> ../logs/carbon_thrift.log 2>&1 &
./beeline -u jdbc:hive2://ip:10000
package com.taiji.streaming import java.io._ import java.text.SimpleDateFormat import java.util.Properties import java.util.concurrent.ConcurrentHashMap import com.taiji.utils.ConfigurationXml import org.apache.commons.lang.StringUtils import org.apache.curator.framework.CuratorFrameworkFactory import org.apache.curator.retry.ExponentialBackoffRetry import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.TopicPartition import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.rdd.RDD import org.apache.spark.sql.CarbonSession._ import org.apache.spark.sql._ import org.apache.spark.sql.types.{StringType, StructField, StructType} import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Seconds, StreamingContext, Time} import org.slf4j.LoggerFactory import scala.collection.mutable import scala.util.control.Breaks.{break, breakable} /** * sparkstreaming通过消费多个topic的数据进行分类存放。 * 目前测试发现此种方式是效率最高的每分钟可消费1000w左右的数据 * * spark 2.3.2 * kafka服务端版本是2.10 spark-streaming-kafka-0-10_2.11-2.3.2 * * 数据写入carbondata */ object CoreRealtimeStreaming { private val log = LoggerFactory.getLogger("coreStreaming") def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("Streaming") .config("spark.streaming.kafka.maxRatePerPartition", kafkaMaxRatePerPar) .config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // .config("spark.executor.memoryOverhead", 4096) // .config("spark.yarn.executor.memoryOverhead", 4096) .enableHiveSupport() .getOrCreateCarbonSession() val ssc = new StreamingContext(spark.sparkContext, Seconds(time.toLong)) spark.sql("use core") //创建carbon表 createCarbonTable(spark) val sc = spark.sparkContext val schemaPathBro = sc.broadcast(schemaPath) val configurationMap = ConfigurationXml.testParserXml(xmlPath) val colAndPosMap = ConfigurationXml.getColAndPosMap for (tp <- 0 until tpArray.size) { val topic = tpArray(tp) val groupId = topic.split("_topic", -1)(0) + "_group" val kafkaParams = Map[String, Object]( "bootstrap.servers" -> topic_brokers, "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "auto.offset.reset" -> "latest", "group.id" -> groupId, "enable.auto.commit" -> "false" ) log.info("consumer topic is: " + topic) val kafkaStream = createDirectKafkaStream(ssc, kafkaParams, topic, groupId) var offsetRanges = Array[OffsetRange]() val resourceRdd = kafkaStream.transform { rdd => offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //得到该 rdd 对应 kafka 的消息的 offset rdd }.map(rdd => { rdd.value() }) resourceRdd.foreachRDD((rdd, time: Time) => { if (!rdd.isEmpty()) { //根据配置文件构造schema val properties = getSchemaProperties(schemaPathBro.value) val fields = properties.getProperty(topic) val schema = StructType(fields.split(",", -1).map(t => { StructField(t, StringType, true) })) // 代码的具体逻辑 val correctBatchData = rdd.map(str => { val trksj = new SimpleDateFormat("yyyyMMdd").format(System.currentTimeMillis()) val appendStr = str + "\t" + trksj val dataStr = appendStr.split("\t", -1) Row.fromSeq(dataStr) }) val correctDf = spark.createDataFrame(correctBatchData, schema) val tableName = "bcp_" + topic.split("_topic", -1)(0) //默认存储位parquet //errorDataDf.write.mode(SaveMode.Append).partitionBy("TRKSJ").saveAsTable(tableName) //carbondata和partition不能同时使用,如下不支持分区 //errorDataDf.write.mode(SaveMode.Append).format("carbondata").partitionBy("TRKSJ").saveAsTable(tableName) CarbonSparkStreamingFactory.getStreamSparkStreamingWriter(spark, "default", tableName) .mode(SaveMode.Append) .writeStreamData(correctDf, time) } } //记录偏移量 storeOffsets(offsetRanges, groupId) }) } ssc.start() ssc.awaitTermination() spark.stop() } catch { case e: Exception => { log.error("CoreRealtimeStreaming is error. ", e) } } } def closeZkClient() { if (client != null) { client.close() } } val config = { val configFile = new File("config.xml") if (!configFile.exists || !configFile.isFile) System.exit(-1) val configInfo = new Properties try configInfo.loadFromXML(new FileInputStream(configFile)) catch { case e: IOException => log.error("config.xml Incorrect format!") System.exit(-1) } configInfo } val client = { val zkHost = config.getProperty("zk_host") if (zkHost == null || zkHost.length == 0) { log.error("zkHost is not config.") System.exit(-1) } val client = CuratorFrameworkFactory .builder .connectString(zkHost) .retryPolicy(new ExponentialBackoffRetry(1000, 3)) .namespace("kafka") .build() client.start() client } // offset 路径起始位置 val Globe_kafkaOffsetPath = "/consumers/streaming" // 路径确认函数 确认ZK中路径存在,不存在则创建该路径 def checkZKPathExists(path: String) = { if (client.checkExists().forPath(path) == null) { client.create().creatingParentsIfNeeded().forPath(path) } } // 保存 新的 offset def storeOffsets(offsetRange: Array[OffsetRange], groupName: String) = { for (o <- offsetRange) { val zkPath = s"${Globe_kafkaOffsetPath}/${groupName}/${o.topic}/${o.partition}" // 向对应分区第一次写入或者更新Offset 信息 log.info("Topic:" + o.topic + ", Partition:" + o.partition + ", Offset:" + o.untilOffset + " to zk") if (client.checkExists().forPath(zkPath) == null) { client.create().creatingParentsIfNeeded().forPath(zkPath) } client.setData().forPath(zkPath, o.untilOffset.toString.getBytes()) } } def getFromOffset(topic: String, groupName: String): (Map[TopicPartition, Long], Int) = { // Kafka 0.8和0.10的版本差别,0.10 为 TopicPartition 0.8 TopicAndPartition // 读取ZK中保存的Offset,作为Dstrem的起始位置。如果没有则创建该路径,并从 0 开始Dstream val zkTopicPath = s"${Globe_kafkaOffsetPath}/${groupName}/${topic}" // 检查路径是否存在 checkZKPathExists(zkTopicPath) // 获取topic的子节点,即 分区 val childrens = client.getChildren().forPath(zkTopicPath) import scala.collection.JavaConversions._ // 遍历分区 val offSets: mutable.Buffer[(TopicPartition, Long)] = for { p <- childrens } yield { // 遍历读取子节点中的数据:即 offset val offsetData = client.getData().forPath(s"$zkTopicPath/$p") // 将offset转为Long val offSet = java.lang.Long.valueOf(new String(offsetData)).toLong // 返回 (TopicPartition, Long) (new TopicPartition(topic, Integer.parseInt(p)), offSet) } println(offSets.toMap) if (offSets.isEmpty) { (offSets.toMap, 0) } else { (offSets.toMap, 1) } } def createDirectKafkaStream(ssc: StreamingContext, kafkaParams: Map[String, Object], topic: String, groupName: String): InputDStream[ConsumerRecord[String, String]] = { // get offset flag = 1 表示基于已有的offset计算 flag = 表示从头开始(最早或者最新,根据Kafka配置) val (fromOffsets, flag) = getFromOffset(topic, groupName) var kafkaStream: InputDStream[ConsumerRecord[String, String]] = null if (flag == 1) { // 加上消息头 //val messageHandler = (mmd:MessageAndMetadata[String, String]) => (mmd.topic, mmd.message()) println(fromOffsets) kafkaStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe(Array(topic), kafkaParams, fromOffsets)) println(fromOffsets) } else { kafkaStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe(Array(topic), kafkaParams)) } kafkaStream } def getSchemaProperties(path: String): Properties = { //保证读取出来的sql顺序与文件顺序一致 val properties = new Properties() // 使用InPutStream流读取properties文件 val bufferedReader = new BufferedReader(new FileReader(path)) properties.load(bufferedReader) properties } /** * create carbondata table * * @param spark sparksession */ def createCarbonTable(spark: SparkSession): Unit = { val objTags = "bcp_obj_tags" spark.sql( s""" | CREATE TABLE IF NOT EXISTS $objTags( | obj_lx String, | obj_val String, | tags String, | CJSJ int, | TRKSJ int) | STORED BY ‘carbondata‘ | TBLPROPERTIES( | ‘streaming‘=‘true‘, | ‘sort_columns‘=‘TRKSJ‘) | """.stripMargin) } }
原文:https://www.cnblogs.com/jsjnb/p/11776559.html