1.设有 NFA M=( {0,1,2,3}, {a,b},f,0,{3} ),其中 f(0,a)={0,1} f(0,b)={0} f(1,b)={2} f(2,b)={3}
画出状态转换矩阵,状态转换图,并说明该NFA识别的是什么样的语言。
 |
a |
b |
|
0 |
0,1 |
0 |
|
1 |
Φ |
2 |
|
2 |
Φ |
3 |
|
3 |
Φ |
Φ |
图一 状态转换矩阵
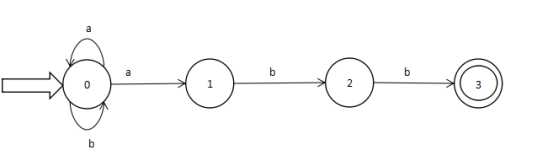
图二 状态转换图
该NFA识别 : L(M)= (a | b) * abb
2.将1的NFA确定化
NFA 确定化为 DFA
子集法:
f(q,a)={q1,q2,…,qn},状态集的子集
将{q1,q2,…,qn}看做一个状态A,去记录NFA读入输入符号之后可能达到的所有状态的集合。
步骤:
1).根据NFA构造DFA状态转换矩阵
①确定DFA的字母表,初态(NFA的所有初态集)
②从初态出发,经字母表到达的状态集看成一个新状态
③将新状态添加到DFA状态集
④重复23步骤,直到没有新的DFA状态
2).画出DFA
3).看NFA和DFA识别的符号串是否一致。
|
|
a |
b |
|
|
A |
0 |
{01} |
0 |
|
B |
{01} |
{01} |
2 |
|
C |
2 |
Φ |
3 |
|
D |
3 |
Φ |
Φ |
图三
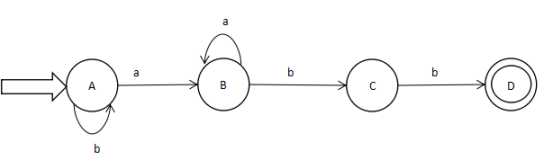
图4
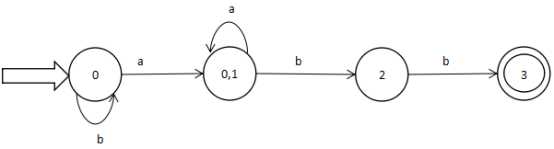
图5
L(M)= b*aa*bb
NFA和DFA识别的符号串是一致。
原文:https://www.cnblogs.com/a131452/p/11762829.html