1、概述:也称为K最近邻算法,原理为搜索最近的k个已知类别样本,用于未知类别样本的预测。
对于分布不均匀的几个样本结果可能会受k取值的影响,通常情况下k值一般取奇数
2、衡量相似性指标方式:欧式距离、曼哈顿距离、cos余弦值、杰卡德相似系数等等
3、过程:
4、避免k值设定出现过拟合(K值过小)和欠拟合(K值选择过大)现象
对于K值设定过大的情况,可以更改设定权重为距离的倒数。另外一种常用的方式为多重交叉验证,k取不同的值,在每个k值下执行m重交叉验证,最后选定平均误差最小的k值。
5、余弦相似度
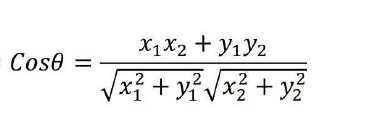
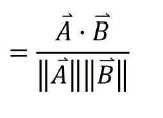
杰卡德相似系数(常用于用户推荐算法)值越大相似性越大
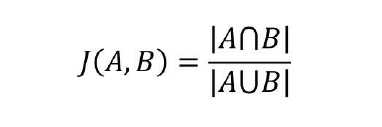
以上距离法构建样本时,一是需注意变量的数值化,若某个变量为离散型字符串,需要数值化处理(0,1,2...)。二是防止受数值变量的量纲影响,量纲可能影响距离,必要时需要进行转化,缩小归一化处理。
6、模型运行搜索方法
模型建立好以后常见的几种搜寻方法
暴力法搜索对于大样本数据集存在内存消耗大,运行速度慢等问题。
案例1(暴力搜寻法):
iris数据集预测,将样本分为2/3的训练解,和1/3的测试集,将测试集置于训练集中训练,比较返回样本点类型结果的准确率。
取K=3
import csv
import random
import math
import operator
def loadDataset(filename, split, trainingSet = [], testSet = []):
with open(filename, ‘rt‘) as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
print(len(dataset))
for x in range(len(dataset)-1): #0-149
for y in range(4): #0-3
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x]-instance2[x]), 2)
return math.sqrt(distance)
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
#testinstance
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
#distances.append(dist)
distances.sort(key=operator.itemgetter(1)) # 取元祖第一个域进行排序
neighbors = []
for x in range(k): #取distances数组前三项距离最小元祖里面的数组
neighbors.append(distances[x][0])
return neighbors
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet)))*100.0
def main():
#prepare data
trainingSet = []
testSet = []
split = 0.67
loadDataset(r‘irisdata.txt‘, split, trainingSet, testSet)
print (‘Train set: ‘ + repr(len(trainingSet)))
print (‘Test set: ‘ + repr(len(testSet)))
#generate predictions
predictions = []
k = 3
for x in range(len(testSet)): # 0 - 测试集长度
# trainingsettrainingSet[x]
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print (‘>predicted=‘ + repr(result) + ‘, actual=‘ + repr(testSet[x][-1]))
print (‘predictions: ‘ + repr(predictions))
accuracy = getAccuracy(testSet, predictions)
print(‘Accuracy: ‘ + repr(accuracy) + ‘%‘)
if __name__ == ‘__main__‘:
main()
结果预测准确率基本在90%以上。
7、KD搜寻法
关键点:
1)根节点如何选择 计算训练集每个变量的方差,取最大方差的变量
2)分割点如何选择
3)树停止生长的条件
原文:https://www.cnblogs.com/hqczsh/p/11745806.html