教材学习内容总结
-
实验楼部分
- X86 寻址方式经历三代:
-
1 DOS时代的平坦模式,不区分用户空间和内核空间,很不安全
2 8086的分段模式
3 IA32的带保护模式的平坦模式
- 二进制文件可以用od 命令查看,也可以用gdb的x命令查看。有些输出内容过多,我们可以使用 more或less命令结合管道查看,也可以使用输出重定向来查看
-
od code.o | more
od code.o > code.txt
- gcc -S xxx.c -o xxx.s 获得汇编代码,也可以用 objdump -d xxx 反汇编; 函数前两条和后两条汇编代码,所有函数都有,建立函数调用栈帧
-
64位机器上想要得到32代码:gcc -m32 -S xxx.c
MAC OS中没有objdump, 有个基本等价的命令otool
Ubuntu中 gcc -S code.c (不带-O1) 产生的代码更接近教材中代码(删除"."开头的语句)
-
PPT部分
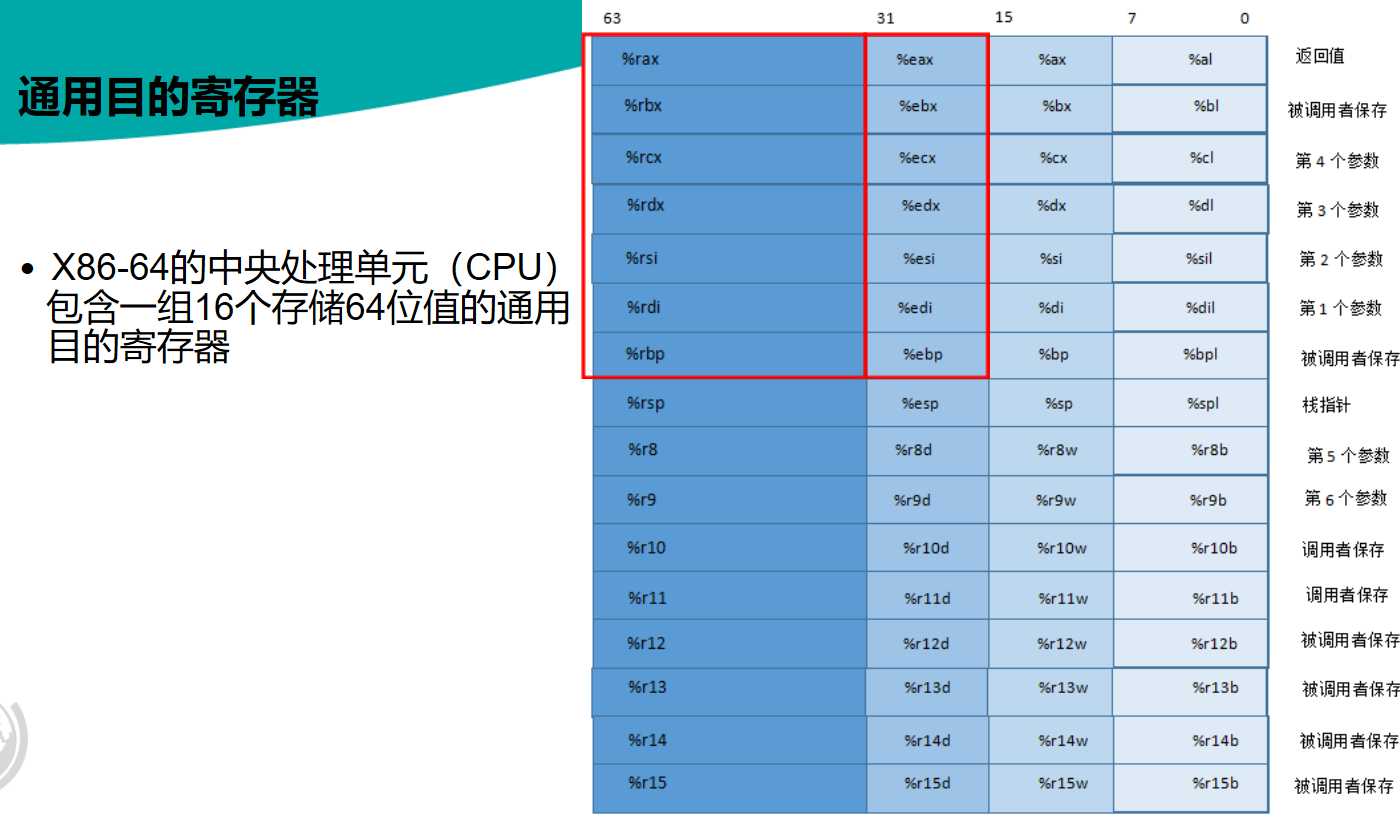
- x86-64的CPU包含一组16个存储64位的通用目的寄存器,如图:
- MOV中的一些常见的数据传送指令
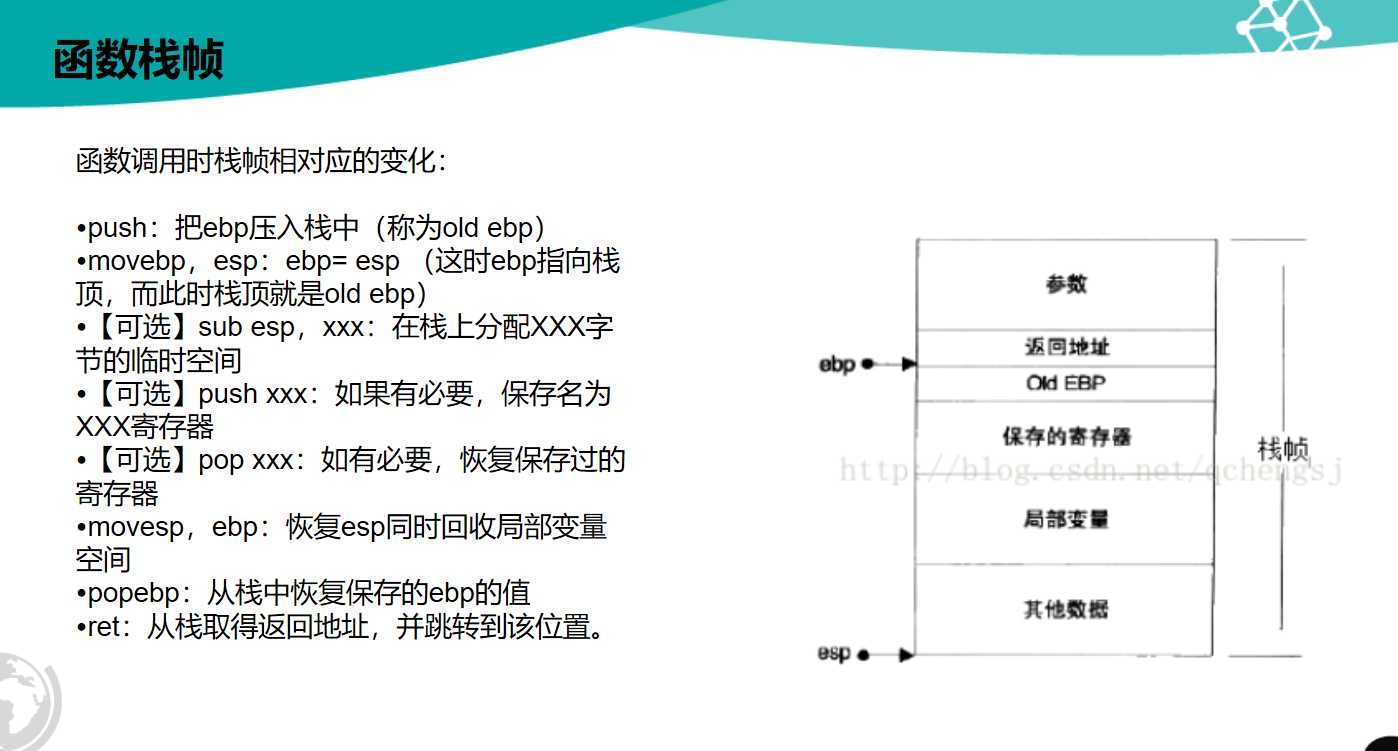
- 函数调用时栈帧相对应的变化
-
操作部分
-
①
- 对教材P114的C语言文件 mstore.c 使用命令 gcc -Og -S mstore.c 可产生其对应的汇编文件 mstore.s 但是不做进一步操作;使用命令 gcc -Og -c mstore.c 可产生其目标代码文件 mstore.o ,但由于其是二进制格式,所以无法直接查看
- 使用命令 objdump -d mstore.o 可反汇编查看机器代码的内容
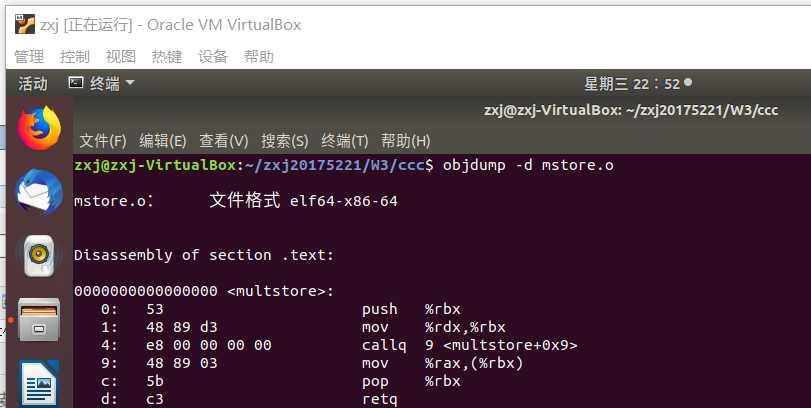
- 左边是14个十六进制字节值,被分成若组,每组都是一条指令,右边是等价的汇编语言
- 我们再查看 mstore.s 的内容(突然忘记怎么打印文本内容,百度后参考了Linux常用基本命令(cat),重新学习了下)
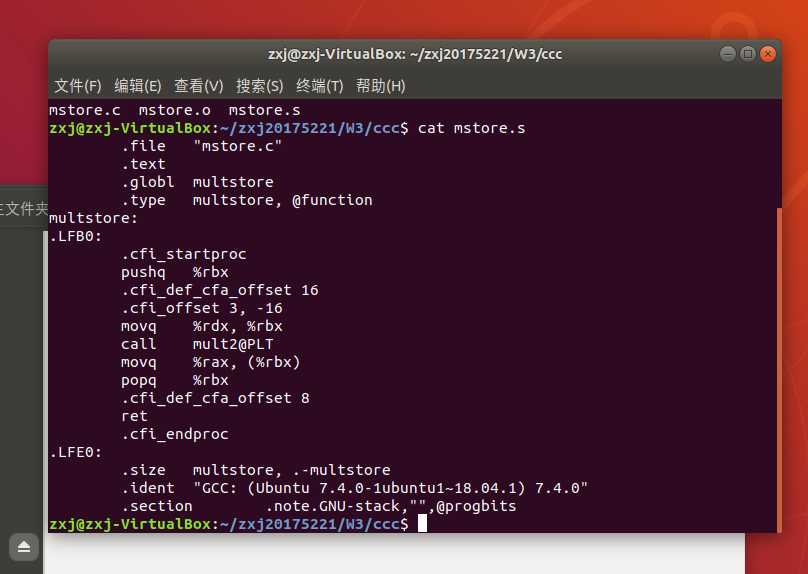
- 所有以 ‘.’ 开头的行都是指导汇编器和链接器工作的伪指令,我们通常可以忽略这些行
-
②
-
将实验楼的代码简单修改如下
-
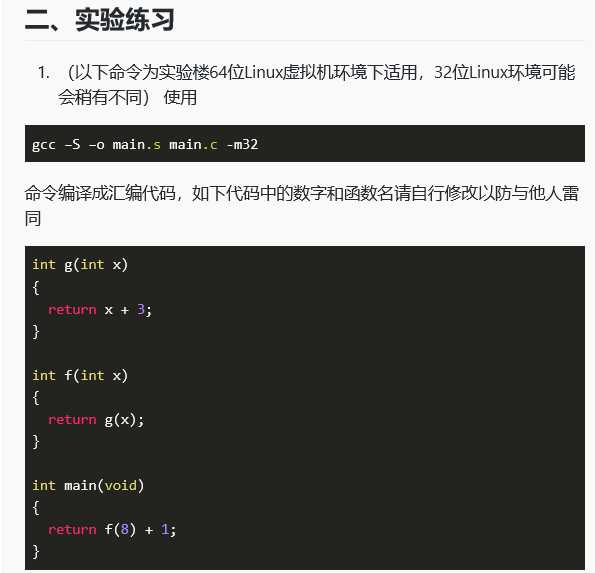
-
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int step1(int x)
{
return x + 3;
}
int step2(int x)
{
return step1(x);
}
int main(void)
{
printf("%d",step2(8) + 1);
return 0;
}
- 参考学习了GDB调试命令---反汇编相关,列出部分我觉得较为实用的调试命令:
-
反汇编命令:disas/disass/disassemble,例如:disas main,显示main函数对应的汇编代码
查看相关信息:info,例如:info line/registers/break,查看某个line的相关信息/各寄存器的值/所有断点
开始执行:r
设置断点:b, 格式:b *内存地址
单步步过:ni
单步步入:si
显示某寄存器的值:display 例如:display /x $eax
查看变量值:p 格式: p 变量名
-
下边将对修改过的代码进行简单的GDB反汇编调试,并加入我个人的理解(有误请指)
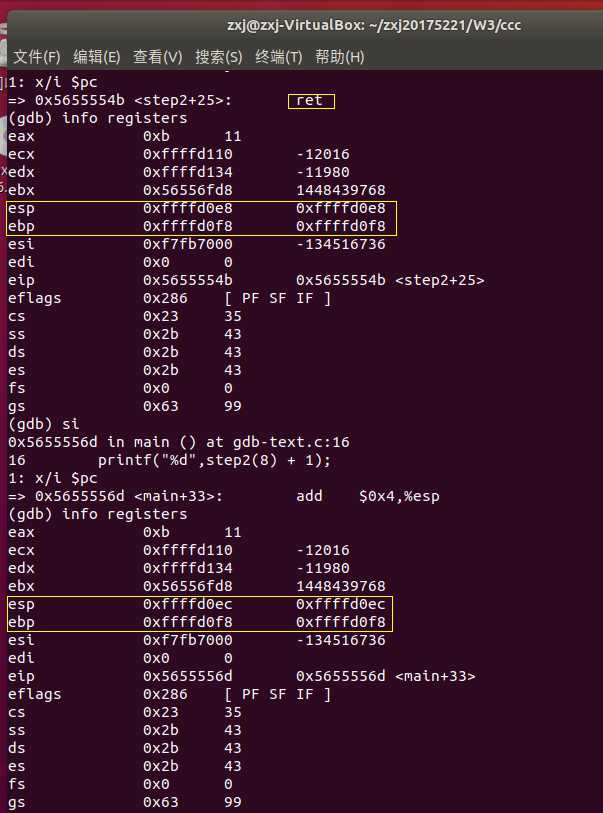
- 进入GDB调试,首先在main处设置一个断点,运行到main时, disas main 查看main的汇编代码, info registers 查看各寄存器的值
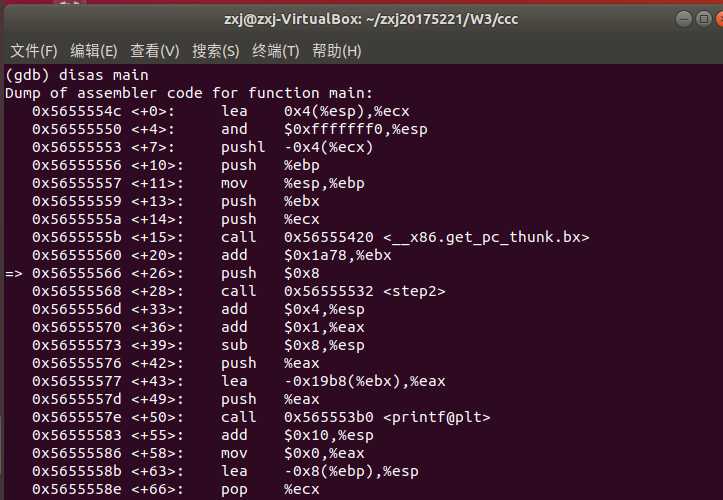
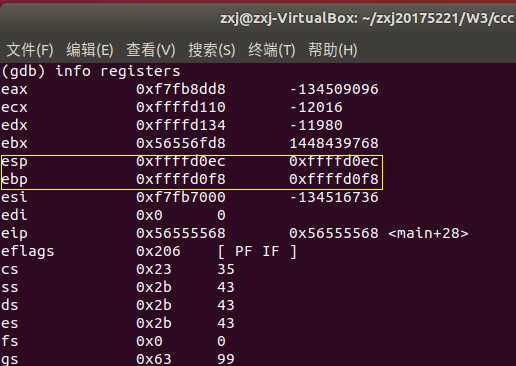
- 注意到此时堆栈指针值为 0xffffd0ec ,基址指针的值 0xffffd0f8
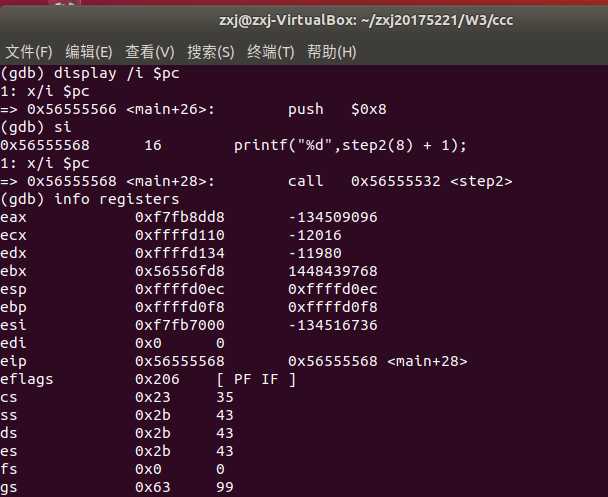
- 在分析之前先进行设置: display /i $pc ,这条命令可显示我们在单步调试时所执行的语句,记录每一步的$esp和$ebp。如下 call 指令将要调用子函数step2
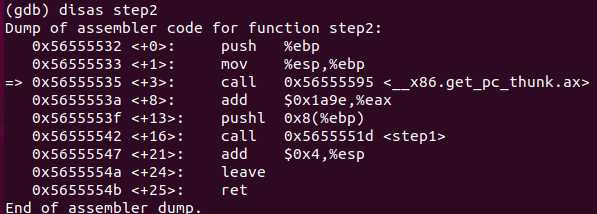
- 查看函数step2的汇编语句
- si 继续下一步,运行到函数step2处,发现栈顶发生变化,一句句理解:
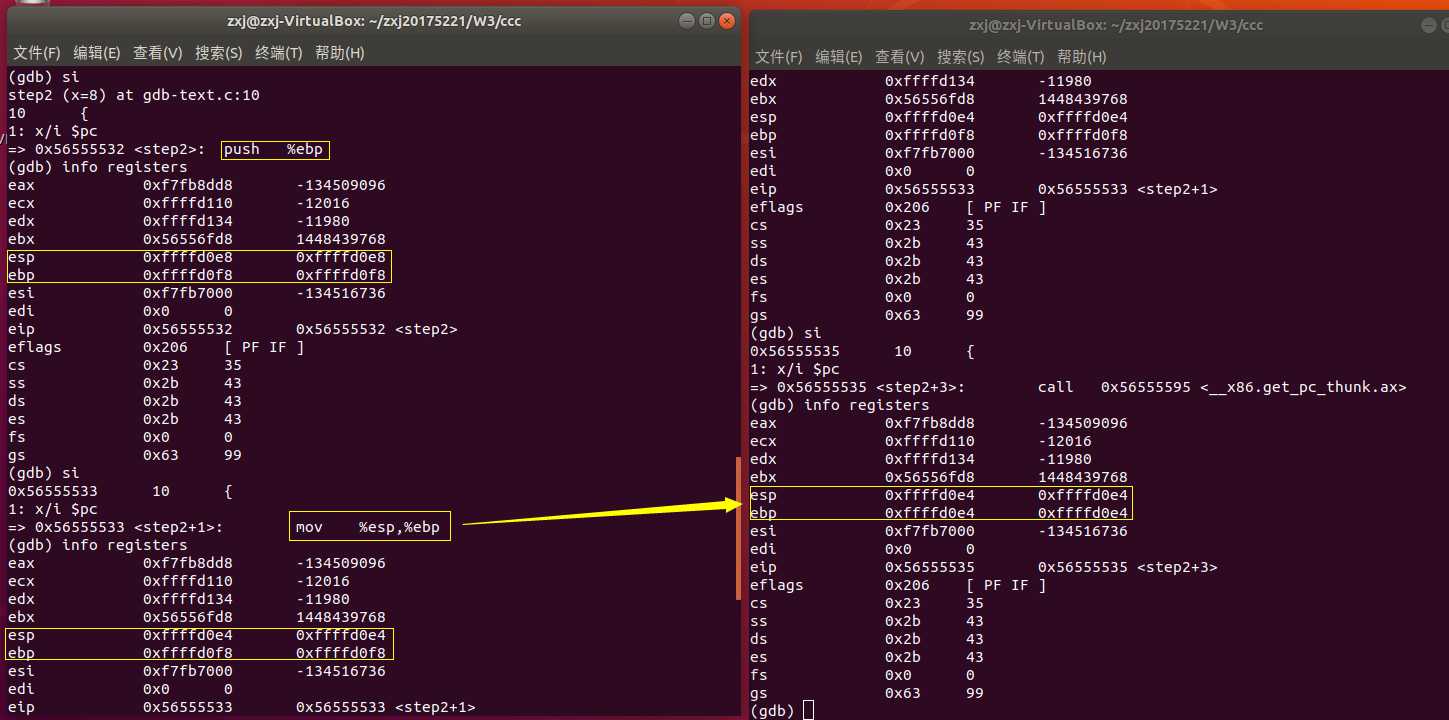
- 左边终端:此时执行的语句为 push %ebp ,意味着向栈里压入了一个东西,栈顶地址由 0xffffd0e8 变为 0xffffd0e4 ,减少了4字节。为什么是减法呢?因为是向低地址增长的
- 右边终端:此时执行的语句为 mov %esp,%ebp ,表示将栈顶指针的值赋给基址,所以二者的值相同,同为0xffffd0e4
- 注意到下一句将调用函数 <__x86.get_pc_thunk.ax> ,参考了深入了解GOT,PLT和动态链接,给出了如下解释:作用就是把esp(即返回地址)的值保存在eax(PIC寄存器)中, 在接下来寻址用
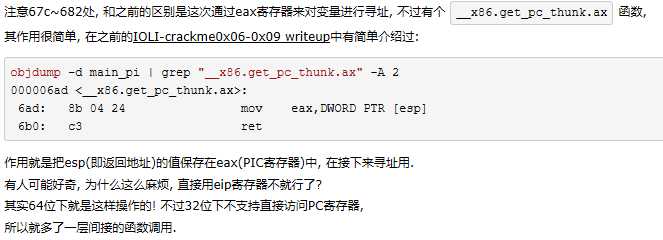
- <__x86.get_pc_thunk.ax> 获取地址,有 mov ret 等部分,其中esp参与运算,过程中值会变化。mov:将esp的值保存在eax中 ret:将参与运算的esp弹出返回,恢复到与ebp相同的值
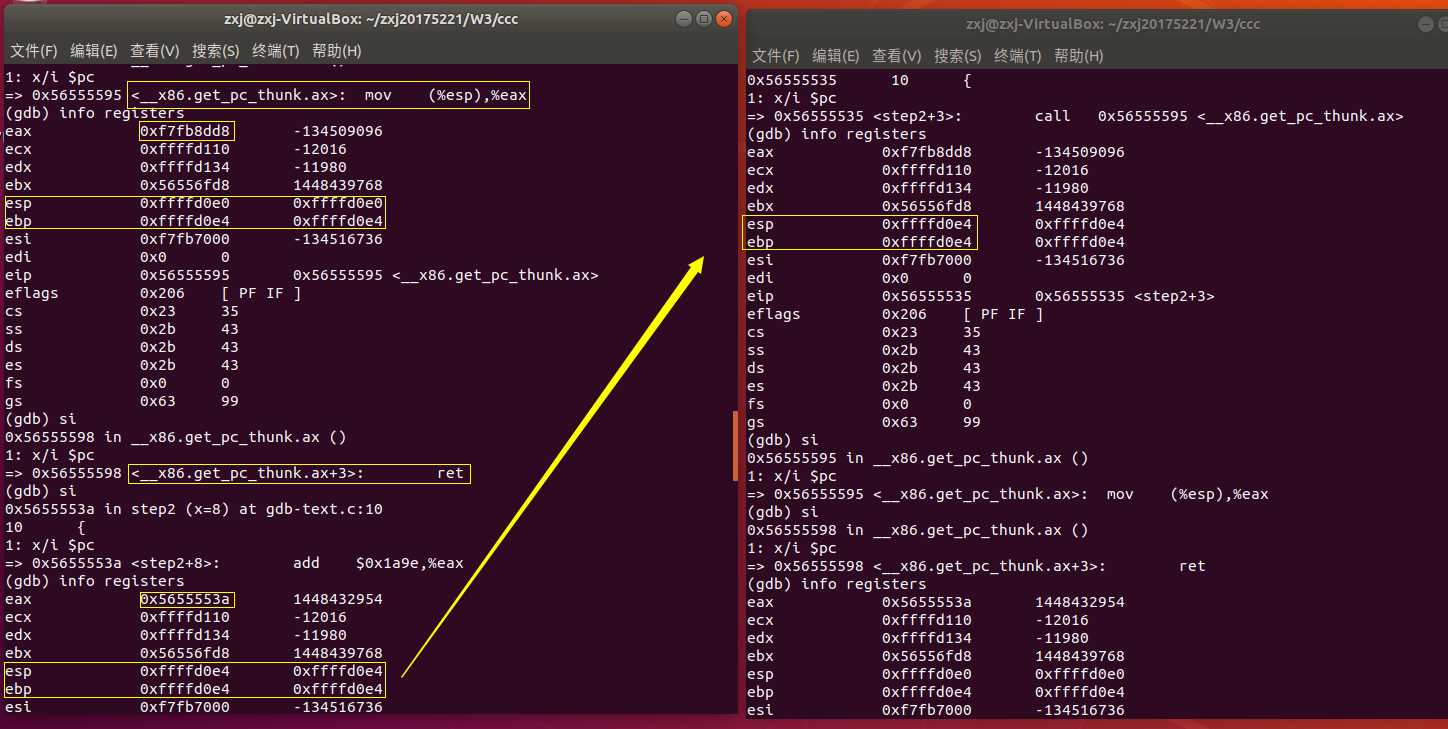
- 重点再来看一下出栈时的地址变化:
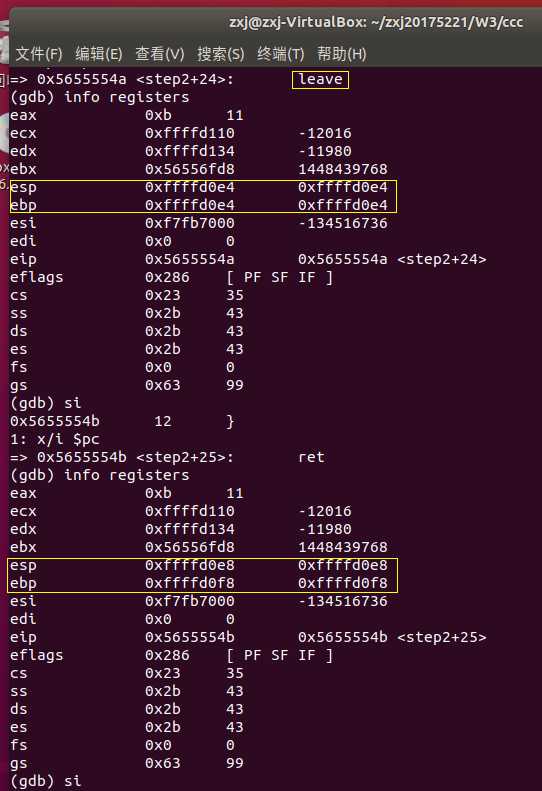
- 执行完 leave 后,ebp恢复为原来的值,这是为什么?ebp不是本应一直保存esp的初始地址吗?
- 或许是因为,虽然ebp的值起初是存在了栈中,但 leave将存在栈中的值弹了出来,赋给了变量ebp
- 而在执行完 ret 后,ebp出栈了,此时栈空,所以栈顶会变成初始的值。且与开始进栈时相反,出栈栈顶+4,即 0xffffd0e8+0x4=0xffffd0ec
- 这次的GDB调试,受限于所学,只是浅尝辄止,后边会继续努力
教材学习中的问题和解决过程
-
问题2解决方案:
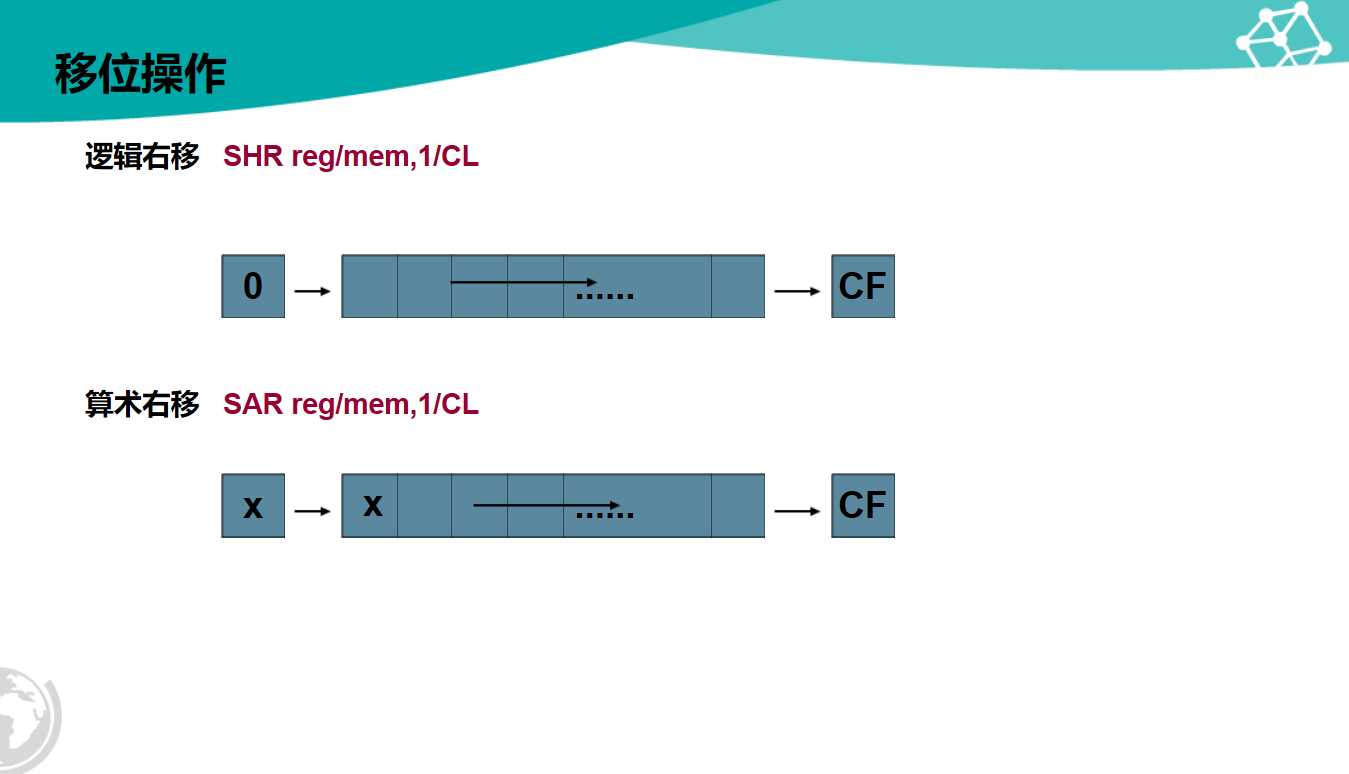
- 参考(逻辑右移和算术右移有什么区别):逻辑右移就是不考虑符号位,右移一位,左边补零即可;算术右移需要考虑符号位,右移一位,若符号位为1,就在左边补1;否则,就补0。所以算术右移也可以进行有符号位的除法,右移,n位就等于除2的n次方。
- 例如,8位二进制数11001101分别右移一位。
- 逻辑右移就是[0]1100110,算术右移就是[1]1100110
-
问题3:
- PPT中数据对齐一处有字节分配的情景,并没有按照最小字节分配,而是遵循了字节对齐的规则。那么,①字节对齐的意义何在?②是按照什么规则进行字节对齐的呢?

-
问题3解决方案:
- 参考了(字节对齐的意义):各个硬件平台对存储空间的处理不尽相同,比如一些CPU访问特定的变量必须从特定的地址进行读取,在这种架构下就必须进行字节对齐,否则读取不到数据或者读取到的数据是错误的。而字节对齐让CPU快速读取到相应的数据的同时,可以提高程序的效率。
- 字节对齐规则如下:
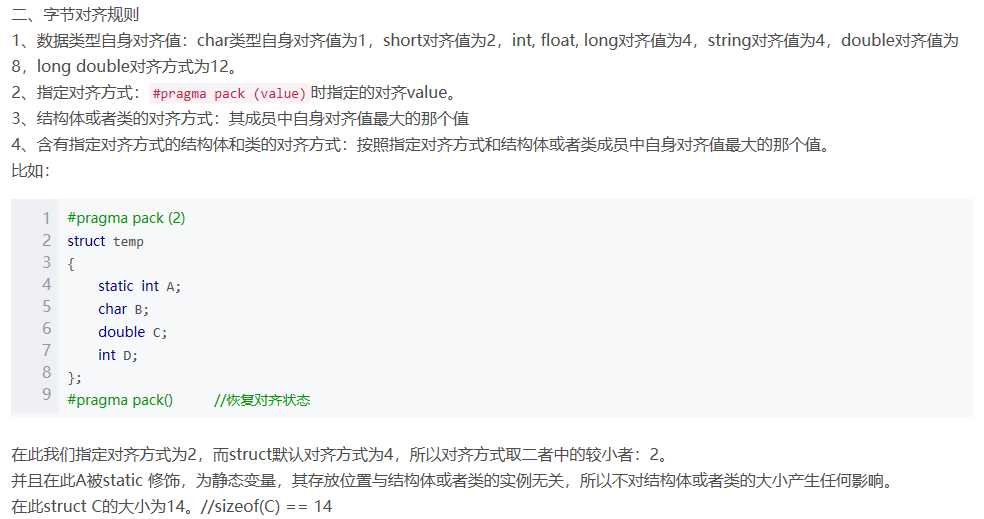
-
问题1:
- 在查看机器代码文件的内容时,我们除了按照教材那样使用命令 objdump -d mstore.o 外,还可以如何做
-
问题1解决方案:
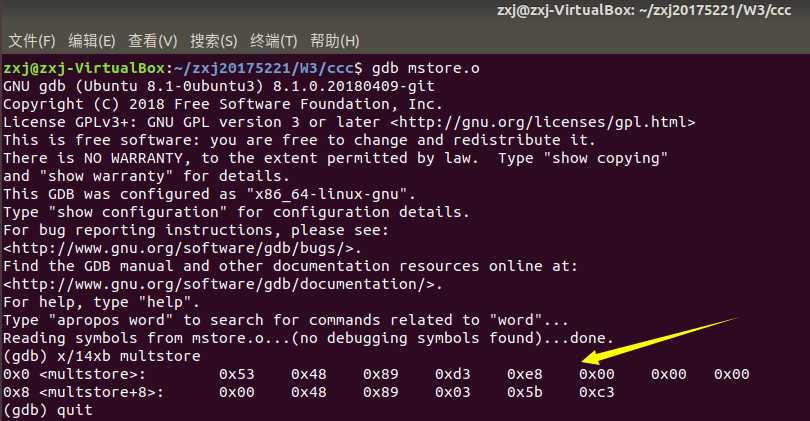
- 我们可以进入GDB调试模式,输入 (gdb) x/14xb multstore ,意思是显示从函数multstore 所处地址开始的14个十六进制格式表示的字节
- 我们还可以使用前边学习过的od命令来将显示内容以十六进制显示,并以每个字节为单位: od -tx1 mstore.o
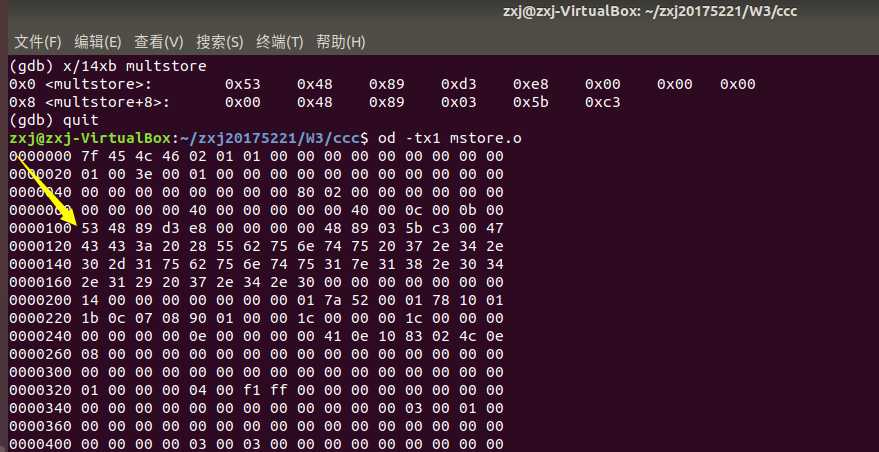
- 但对比来看,我们若是需要进行汇编分析,那还是 object dump 较为实用些
-
问题2:
- 在使用gdb反汇编命令调试程序时,出现了权限不够的提示
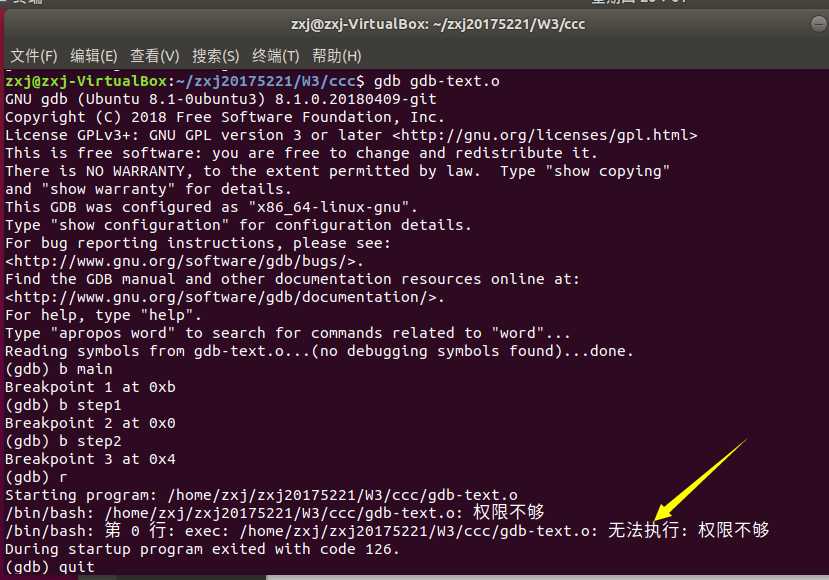
-
问题2解决方案:
- 参考了gdb调试run之后说权限不够,是因为 gdb-text.o 是没有链接的编译文件,没办法执行。需要重新编译-- 编译命令:gcc -g -o gdb-text gdb-text.c 调试命令:gdb -q gdb-text 。
-
问题3:
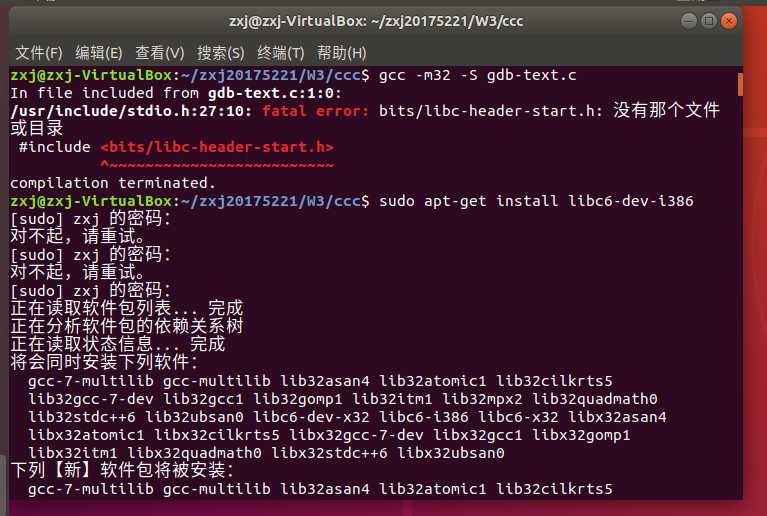
- 在转32位时报错
-
问题3解决方案:
- 参考了gcc -m32报错的解决办法,使用命令 sudo apt-get install libc6-dev-i386 安装操作系统支持包即可
心得体会
通过这次简单的GDB调试,才知道即使在c中短短的一个赋值语句,一个返回语句,在汇编语言中都可能包含着许多出栈,压栈,传参等操作。只是前人做了许多努力,我们现在才轻松了许多。但不代表我们就可以对汇编语言视若无睹,对汇编语言的学习,重点还是要加强对它的理解,多动手实践应用它
上周考试错题总结
无
学习进度条
| 目标 |
5000行 |
30篇 |
400小时 |
|
| 第一周 |
53/53 |
1/1 |
20/20 |
|
| 第二周 |
200/253 |
2/3 |
21/20 |
|
| 第三周 |
100/353 |
1/4 |
30/50 |
|
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。 耗时估计的公式 :Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
参考:软件工程软件的估计为什么这么难,软件工程 估计方法
-
计划学习时间:XX小时
-
实际学习时间:XX小时
-
改进情况:
(有空多看看现代软件工程 课件 软件工程师能力自我评价表)
参考资料
20175221 《信息安全系统设计基础》第5周学习总结
原文:https://www.cnblogs.com/zxja/p/11614028.html