在Python中,能够直接处理的数据类型有以下几种:
多采用16进制,由0x 前缀、0-9、a-f 组成。例:0xff00
科学计数法写法:1.23x10^9 ——> 1.23e+9
用 ‘ ‘/" "括起来的任意文本
(1)如果字符串内部既包含‘又包含",可以用转义字符\来标识,比如: ‘I\‘m \"OK\"!‘
为了简化,Python还允许用r‘‘表示‘‘内部的字符串默认不转义
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用‘‘‘...‘‘‘的格式表示多行内容
一个布尔值只有True、False两种值
and运算是与运算,只有所有都为True,and运算结果才是True ——短路逻辑or运算是或运算,只要其中有一个为True,or运算结果就是Truenot运算是非运算,它是一个单目运算符,把True变成False,False变成True 空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
Python中,有两种除法,一种除法是/:
/除法计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数
还有一种除法是//:
称为地板除,两个整数的除法仍然是整数
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
计算机内存中统一使用Unicode编码
要保存到硬盘或需要传输的时候,转换为UTF-8编码
ord(‘A‘)=65 —— 获取字符的整数表示
chr(66)=‘B‘ —— 把编码转换为对应的字符
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b‘ABC‘
要注意区分‘ABC‘和b‘ABC‘,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> ‘ABC‘.encode(‘ascii‘)
b‘ABC‘
>>> ‘中文‘.encode(‘utf-8‘)
b‘\xe4\xb8\xad\xe6\x96\x87‘str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b‘ABC‘.decode(‘ascii‘)
‘ABC‘
>>> b‘\xe4\xb8\xad\xe6\x96\x87‘.decode(‘utf-8‘)
‘中文‘由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
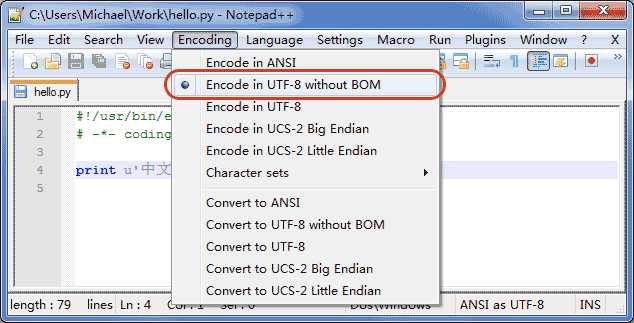
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
>>>print(‘%.2f ‘ %3.1415926)
>>>3.14
format() ——位置占位符
>>> ‘Hello, {0}, 成绩提升了 {1:.1f}%‘.format(‘小明‘, 17.125)
‘Hello, 小明, 成绩提升了 17.1%‘
x, y=4,5
if x<y:
small = x
else:
small = y
————>
small = x if x<y else y
small =(x if x<y and x<z) else (y if y<z else z)
当assert后条件为假,程序自动崩溃 ——AssertionError——反之忽略——【置入检查点】
原文:https://www.cnblogs.com/Aurakkk-8/p/11620300.html