MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像
关系数据库的。他支持的数据结构非常松散,是类似 json 的 bson 格式,因此可以存储比较复杂的数据类
型。Mongo 最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以
实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。它的特点是高性能、易部署、易使用,存储数据非常方便
1.新建一个存放数据库的文件夹,注意:不能有中文和空格,建议不要放在 C盘.(E:\data\mongodbData)
2.启动 MongoDb 服务
mongod --dbpath 文件夹路径
//mongod --dbpath E:\data\mongodbData注意:以这种方式打开服务,这个cmd就不能关闭了,关闭之后,这个数据库自动关闭.
3.连接数据库
连接本地数据库:mongo
连接外部数据库:mongo ip地址:端口号
show dbs使用数据库和创建数据库都是这个语句,但是创建数据库的时候,虽然可以进入,但实际这个数据库仍然是没有的,只有在这里面插入了数据之后,才是真正创建了数据库
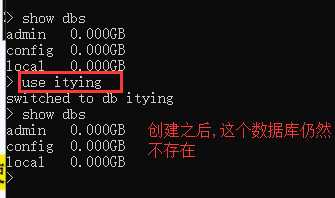
use ityingdb.dropDatabase();db.表名.drop()先use 数据库,然后删除当前数据库
show collections插入数据,随着数据的插入,数据库创建成功了,集合也创建成功了
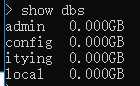
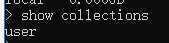
db.表名.insert({"name":"zhangsan"});
//db.user.insert({"name":"zhangsan","age":20})db.userInfo.find();
相当于:select* from userInfo;db.userInfo.distinct("name");
会过滤掉 name 中的相同数据
相当于:select distict name from userInfo;查询 age = 22 的记录:
db.userInfo.find({"age": 22});
相当于: select * from userInfo where age = 22;db.userInfo.find({age: {$gt: 22}});
相当于:select * from userInfo where age >22;db.userInfo.find({age: {$lt: 22}});
相当于:select * from userInfo where age <22;db.userInfo.find({age: {$gte: 25}});
相当于:select * from userInfo where age >= 25;db.userInfo.find({age: {$lte: 25}});db.userInfo.find({age: {$gte: 23, $lte: 26}});查询 name 中包含 mongo 的数据
db.userInfo.find({name: /mongo/});
//相当于%%
select * from userInfo where name like ‘%mongo%’;
//------------
查询 name 中以 mongo 开头的
db.userInfo.find({name: /^mongo/});
select * from userInfo where name like ‘mongo%’;db.userInfo.find({}, {name: 1, age: 1});
相当于:select name, age from userInfo;当然 name 也可以用 true 或 false,当用 ture 的情况下河 name:1 效果一样(name:true),如果用 false 就是排除 name,显示 name 以外的列信息。
db.userInfo.find({age: {$gt: 25}}, {name: 1, age: 1});
相当于:select name, age from userInfo where age >25;升序:db.userInfo.find().sort({age: 1});
降序:db.userInfo.find().sort({age: -1});db.userInfo.find({name: ‘zhangsan‘, age: 22});
相当于:select * from userInfo where name = ‘zhangsan’ and age = ‘22’;db.userInfo.find().limit(5);
相当于:selecttop 5 * from userInfo;db.userInfo.find().skip(10);
//查询除了前10条以外的全部
select * from userInfo where id not in (selecttop 10 * from userInfo);db.userInfo.find().limit(10).skip(5);
//跳过5条查询10条
可用于分页,limit 是 pageSize,skip 是第几页*pageSizedb.userInfo.find({$or: [{age: 22}, {age: 25}]});
相当于:select * from userInfo where age = 22 or age = 25;db.userInfo.findOne();
相当于:selecttop 1 * from userInfo
db.userInfo.find().limit(1);db.userInfo.find({age: {$gte: 25}}).count();
相当于:select count(*) from userInfo where age >= 20;
如果要返回限制之后的记录数量,要使用 count(true)或者 count(非 0)
db.users.find().skip(10).limit(5).count(true);
false:查询所有修改里面还有查询条件。你要该谁,要告诉 mongo。
db.student.update({"name":"小明"},{$set:{"age":16}});db.student.update({"score.shuxue":70},{$set:{"age":33}});默认update更新一条,若想更新所有符合条件的,使用{multi: true}
db.student.update({"sex":"男"},{$set:{"age":33}},{multi: true});db.student.update({"name":"小明"},{"name":"大明","age":16});复杂操作db.users.update({name: ‘Lisi‘}, {$inc: {age: 50}}, false, true);
相当于:update users set age = age + 50 where name = ‘Lisi’;db.users.update({name: ‘Lisi‘}, {$inc: {age: 50}, $set: {name: ‘hoho‘}}, false, true);
相当于:update users set age = age + 50, name = ‘hoho’ where name = ‘Lisi’;db.表名.remove({ "borough": "Manhattan" })
//默认会删除所有符合条件的
db.users.remove({age: 132});
//删除符合条件的第一条(顺序)
db.表名.remove({ "borough": "Queens" }, { justOne: true })
for(var i=0;i<100;i++){
db.user.insert({"title":"shop"+i})
}索引是对数据库表中一列或多列的值进行排序的一种结构,可以让我们查询数据库变得更快。MongoDB 的索引几乎与传统的关系型数据库一模一样,这其中也包括一些基本的查询优化技巧
为一个字段创建索引之后,使用这个字段进行查询的速度回增加很多
db.user.ensureIndex({"name":1})
//为user表中的name字段设置索引,数据多的时候,创建索引会有点慢db.user.getIndexes()
//获取user表的所有索引(默认只有表有索引)db.user.dropIndex({"name":1})
//删除name字段的索引db.user.ensureIndex({"username":1, "age":-1})
//数字 1 表示 username 键的索引按升序存储,-1 表示 age 键的索引按照降序方式存储。 该索引被创建后,基于 username 和 age 的查询将会用到该索引,或者是基于 username
的查询也会用到该索引,但是只是基于 age 的查询将不会用到该复合索引。因此可以说,
如果想用到复合索引,必须在查询条件中包含复合索引中的前 N 个索引列。然而如果查询
条件中的键值顺序和复合索引中的创建顺序不一致的话,MongoDB 可以智能的帮助我们调
整该顺序,以便使复合索引可以为查询所用。如:
db.user.find({"age": 30, "username": "stephen"})
//会动态调整为:db.user.find({"username": "stephen","age": 30 }):按照创建的索引的顺序db.user.ensureIndex({"username":1},{"name":"userindex"})
//这个索引的名字为:userindex随着集合的增长,需要针对查询中大量的排序做索引。如果没有对索引的键调用 sort,MongoDB 需要将所有数据提取到内存并排序。因此在做无索引排序时,如果数据量过大以致无法在内存中进行排序,此时 MongoDB 将会报错
在缺省情况下创建的索引均不是唯一索引。
{"unique":true}db.user.ensureIndex({"userid":1},{"unique":true})注意:
- 如果再次插入 userid 重复的文档时,MongoDB 将报错,以提示插入重复键。
- 如果插入的文档中不包含 userid 键,那么该文档中该键的值为 null,如果多次插入类似
的文档,MongoDB 将会报出同样的错误
- 若创建索引的时候,旧的数据没有这个字段或者这个字段数据重复,索引将创建失败.

如果在为已有数据的文档创建索引时,可以执行下面的命令,以使 MongoDB 在后台创建索引,这样的创建时就不会阻塞其他操作。但是相比而言,以阻塞方式创建索引,会使整个创建过程效率更高,但是在创建时 MongoDB 将无法接收其他的操
db.user.ensureIndex({"username":1},{"background":true}) //后台创建索引
db.user1.ensureIndex({"title":1},{"dropDups":true}) //创建唯一索引,(重复的不删除)explain 是非常有用的工具,会帮助你获得查询方面诸多有用的信息。只要对游标调用该方法,就可以得到查询细节。explain 会返回一个文档,而不是游标本身。如:
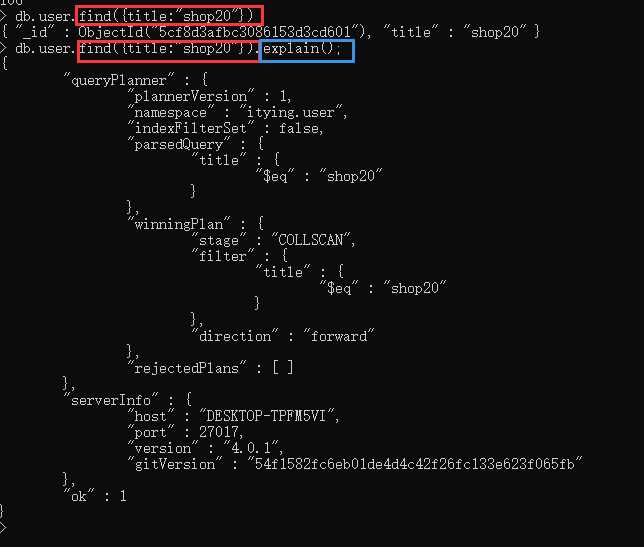
explain 会返回查询使用的索引情况,耗时和扫描文档数的统计信息。
db.表名.find().explain( "executionStats" )
关注输出的如下数值:explain.executionStats.executionTimeMillis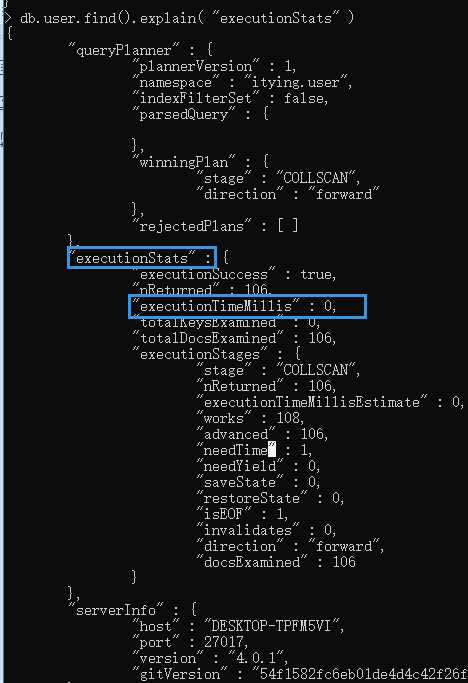
原文:https://www.cnblogs.com/ziyue7575/p/11593428.html