1、正则表达式:
简单的说,正则表达式就是一套处理字符串的规则和方法,以行为单位对字符串进行处理,通过特殊的符号的辅助,我们可以快速的过滤,替换某些特定的字符串。
正则表达式可以快速的过滤出我们需要的内容。配合三剑客使用。
2、正则表达式实际就是一些特殊字符,赋予了他特定的含义。
(1)^word 搜索以word开头的
(2)word$ 搜索以word结尾的
(3). 代表且只能代表任意一个字符
. 具有的含义,代表当前目录、隐藏文件的标识、使一个配置文件生效。
(4)\ 转义
(5)* 表示重复0个或多个前面的一个字符。
(6).* 匹配所有字符(任意字符多个)
^.* 以任意字符开头的
(7)[] 括号里的内容都可以匹配
(8)[^word] 匹配不包含 ^后任意字符的内容
(9)\{n,m\} 重复 n 到 m 次,前一个重复的字符。如果用 egrep 可以去掉斜线。
\{,m\} 重复至多 m 次,前一个重复的字符。如果用 egrep 可以去掉斜线。
\{n,\} 重复至少 n 次,前一个重复的字符。如果用 egrep 可以去掉斜线。
\{n\} 重复 n 次,前一个重复的字符。如果用 egrep 可以去掉斜线。
需要对{}进行转义,所以在每个大括号前面加上 \
3、举例说明:
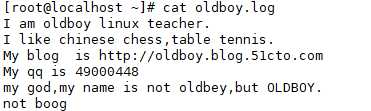
(1)过滤 M 开头的

(2)不区分大小写输出。 -i
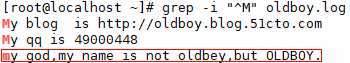
(3)过滤以 m 结尾的,$ 放在后面。
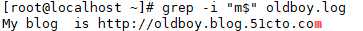
(4)将带 . 的文件进行过滤输出并加行号显示。 -n 显示行号; . 匹配任意一个字符,需要用 \ 进行转义。

(5)过滤“49000448”号码,使用 * 进行0次或多次匹配。

* 将前面的0匹配了0次或多次。
(6)使用 [] 过滤。
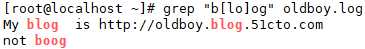
[] 里的内容都可以匹配,匹配 l 或者 o,匹配到的是 blog 或 boog。
(7)匹配不带有 oldboy 任意一个字符的行;括号里的任意一个字符都匹配。
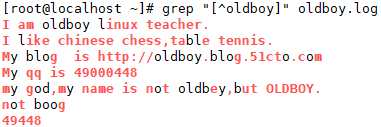
(8)使用分组的情况过滤 qq 号码;

对前面的 0 匹配 2-3 次。
对前面的 0 匹配至多 5 次。0 - 5 次

对前面的 0 匹配至少 3 次。
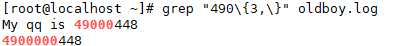
================================================================
扩展的正则表达式: egrep 或 grep -E
(1)+ 重复一个或一个以上前面的内容
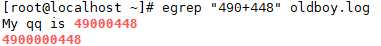
(2)? 0个或一个前面的字符
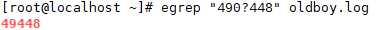
匹配前面的字符 0 次或一次。
(3)| 用或的方式查找多个符合的字符串

查找文件下为有 3306 或 1521 的文件
(4)() 找出 “用户组” 字符串

查找带 lo 组或者 oo 组的内容
================================================================
原文:https://www.cnblogs.com/wqs-Time/p/11586804.html