---恢复内容开始---
1—本 基本 SELECT 语句
SELECT *|{[DISTINCT] column|expression [alias],...}
FROM table;
• SELECT 标识选择哪些列。
• FROM 标识从哪个表中选择。
选择全部列:SELECT * FROM departments;
选择特定的列:SELECT department_id, location_id FROM departments;
注 意:
• SQL 语言 大小写不敏感。
• SQL 可以写在一行或者多行
• 关键字不能被缩写也不能分行
• 各子句一般要分行写。
• 使用缩进提高语句的可读性。
列的别名
• 重命名一个列。
• 便于计算。
• 紧跟列名, 也可以在列名和别名之间加入关键字
‘ AS’ ,别名使用 双引号, 以便在别名中包含空
格或特殊的字符并区分大小写。
使用别名
SELECT last_name AS name, commission_pct comm
FROM employees;
SELECT last_name "Name", salary*12 "Annual Salary"
FROM employees;
字符串
• 字符串可以是 SELECT 列表中的一个字符,数字,日
期。
• 日期和字符只能在 单引号 中出现。
• 每当返回一行时,字符串被输出一次。
显示表结构:DESCRIBE employees
• 使用WHERE 子句,将不满足条件的行过滤掉
SELECT *|{[DISTINCT] column|expression [alias],...}
FROM table
[WHERE condition(s)];
• WHERE 随 子句紧随 FROM 子句。
比较运算操作符
= 等于 ( 不是 ==)
> 大于
>= 大于、等于
< 小于
<= 小于等于
<>不等于 ( 也可以是 !=)
其它比较运算符
BETWEEN...AND...在两个值之间 ( 包含边界)
IN(set)等于值列表中的一个
LIKE模糊查询
IS NULL空值
BETWEEN
使用 BETWEEN 运算来显示在一个区间内的值
SELECT last_name, salary
FROM employees
WHERE salary BETWEEN 2500 AND 3500;
IN
使用 IN运算显示列表中的值。
SELECT employee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (100, 101, 201);
LIKE
• 使用 LIKE 运算选择类似的值
• 选择条件可以包含字符或数字:
– % 代表零个或多个字符( ( 任意个字符) )。
– _ 代表一个字符。
SELECT first_name
FROM employees
WHERE first_name LIKE ‘S%‘;
NULL
使用 IS (NOT) NULL 判断空值。
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
逻辑运算
AND 逻辑并
OR 逻辑或
NOT 逻辑否
AND 要求并的关系为真
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000
AND job_id LIKE ‘%MAN%‘;
OR
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >= 10000
OR job_id LIKE ‘%MAN%‘;
OR 要求或关系为真。
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >= 10000
OR job_id LIKE ‘%MAN%‘;
ORDER BY 子句
• 使用 ORDER BY 子句排序
– ASC(ascend): 升序
– DESC( descend ): 降序
• ORDER BY 子句在SELECT 语句的 结尾
降序排序
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date DESC ;
按别名排序
SELECT employee_id, last_name, salary*12 annsal
FROM employees
ORDER BY annsal;
多个列排序
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC;
AVG ( 平均值)和 SUM ( 合计)函数
可以对 数值型数据使用AVG 和 SUM 函数。
SELECT AVG(salary), MAX(salary),
MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE ‘%REP%‘;
MIN (和 最小值)和 MAX ( 最大值)函数
可以对 任意数据类型的数据使用 MIN 和 MAX 函数。
COUNT ( 计数)函数
COUNT(*) 返回表中记录总数,适用于 任意数据类型。
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
COUNT ( 计数)函数
• COUNT(expr) 返回expr 不为空的记录总数 。
分组数据: GROUP BY 子句语法
可以使用GROUP BY
明确:WHERE 一定放在FROM
非法使用组函数
• 在 不能在 WHERE 子句中使用组函数。
• 在 可以在 HAVING 子句中使用组函数。
过滤分组: HAVING 子句
使用 HAVING 过滤分组:
1. 行已经被分组。
2. 使用了组函数。
3. 满足HAVING 子句中条件的分组将被显示
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
4 — 多表查询
笛卡尔集
• 笛卡尔集会在下面条件下产生:
– 省略连接条件
– 连接条件无效
– 所有表中的所有行互相连接
为了避免笛卡尔集, 可以在 WHERE 加入有
效的连接条件。
使用连接在多个表中查询数据
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2;
• 在 在 WHERE 子句中写入连接条件。
• 在表中有相同列时,在列名之前加上表名前缀
区分重复的列名
• 使用表名前缀在多个表中区分相同的列。
• 在不同表中具有相同列名的列可以用 表的别名
加以区分。
• 如果使用了表别名,则在select语句中需要使
用表别名代替表名
• 表别名最多支持32个字符长度,但建议越少越
好
使用 ON 子句创建连接
• 自然连接中是以具有相同名字的列为连接条件的。
• 用 可以使用 ON 子句指定额外的连接条件。
• 这个连接条件是与其它条件分开的。
• ON 子句使语句具有更高的易读性。
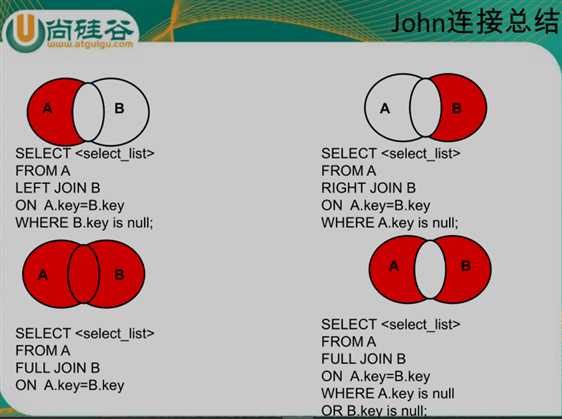
分类:
– 内连接 [inner] join on
– 外连接
• 左外连接 left [outer] join on
• 右外连接 right [outer] join on

原文:https://www.cnblogs.com/chq50/p/11585420.html