一、简介
6V:
1.volume:数据量大;
2.variety:数据的种类多样性(结构化、半结构化、非结构化)
3.velocity:处理速度快、实时、多进程、数据流
4.Value:价值密度低
5.veracity:真实性、可靠性
6.valence:连通性,关联性
7.Vitality:动态性
8.Visualization:可视化
9.Validity:合法性
大数据和其他技术的关联
大数据和云计算:云计算给大数据提供了很好的数据处理条件
大数据和人工智能:相辅相成,大数据处理和计算海量数据供给机器学习,计算机通过自然语言处理和人工智能建立模型。
二、hadoop生态圈
a.概念:Hadoop是Apache提供的一个开源的、可靠的、可扩展的系统架构,可以利用分布式架构来进行海量数据的存储以及计算。
需要注意的是Hadoop处理的是离线数据,即在数据已知以及不要求实时性的场景下使用。
b.版本:
1. Hadoop1.0:只包含HDFS以及MapReduce两个模块
2. Hadoop2.0:完全不同于1.0的架构,包含HDFS、MapReduce以及Yarn三个模块
3. Hadoop3.0:包含HDFS、MapReduce、Yarn、Ozone以及Submarine五个模块
c.模块
1. Common:在Hadoop1.0中,包含HDFS、MapReduce和其他项目公共内容,从Hadoop2.0开始,HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
2. HDFS:用于分布式环境下数据的存储
3. Yarn:Hadoop2.0版本中出现,用于进行资源管理和任务调度的框架
4. MapReduce:从Hadoop2.0开始,基于Yarn,用于在海量数据的场景下进行并行计算
5. Ozone:基于HDFS进行对象的存储
6. Submarine:基于Hadoop进行机器学习的引擎
d.相关组件
1. HBase: 类似Google BigTable的分布式NoSQL列数据库。(HBase和Avro已经于2010年5月成为顶级 Apache 项目)
2. Hive:数据仓库工具,由Facebook贡献
3. Zookeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献
4. Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
5. Pig: 大数据分析平台,为用户提供多种接口
6. Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群
7. Sqoop:于在Hadoop与传统的数据库间进行数据的传递
三、hadoop在企业中的应用
a.百度使用Hadoop构建了数据处理平台,Hadoop集群中的节点个数超过了2W个,每天处理的数据量可以达到20PB。
1. 网页的分析处理
2. 用户的访问行为的分析处理,以建立用户画像
3. 用户推荐系统的数据分析和处理
4. 在线广告的点击分析和流量分析
b.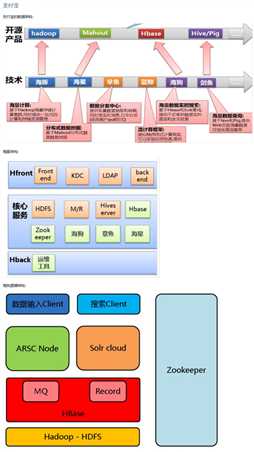
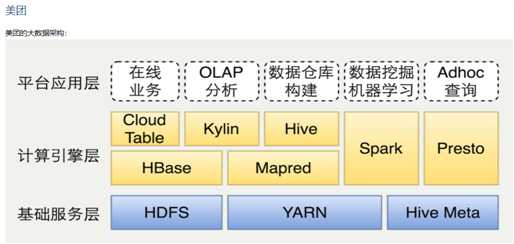
原文:https://www.cnblogs.com/zym627270054/p/11577485.html