在对象中添加一个引用计数器,当有地方引用这个对象的时候,引用技术器得值就+1,当引用失效的时候,计数器得值就-1
算法缺点:循环引用无法回收。
2)可达性分析法
GCroot结点开始向下搜索,路径称为引用链,当对象没有任何一条引用链链接的时候,就认为这个对象是垃圾,并进行回收。
那么什么是GCroot呢(虚拟机在哪查找GCroot)。
目前主流JVM采用的垃圾判定算法就是可达性分析法。
存在的问题:
下面是java内存常规划分
下面是堆内存的划分
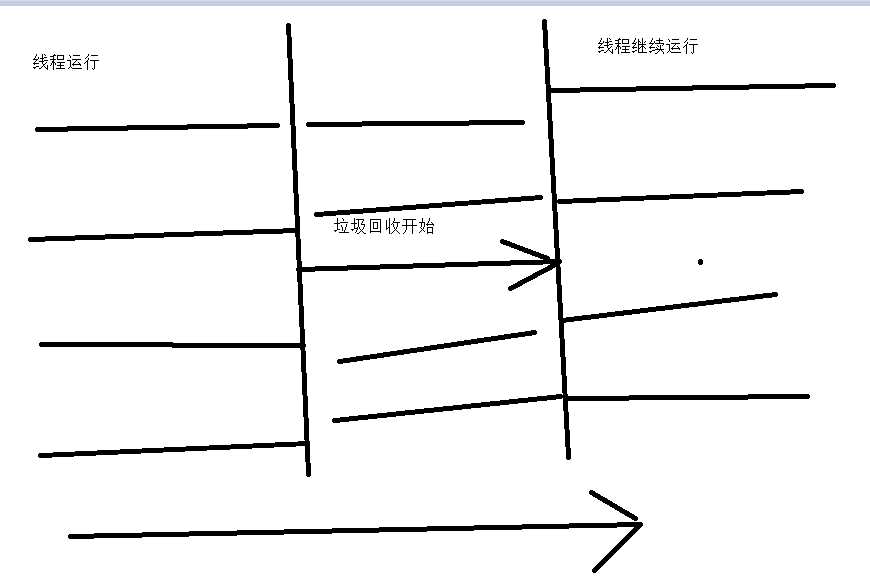
下面就是过程:
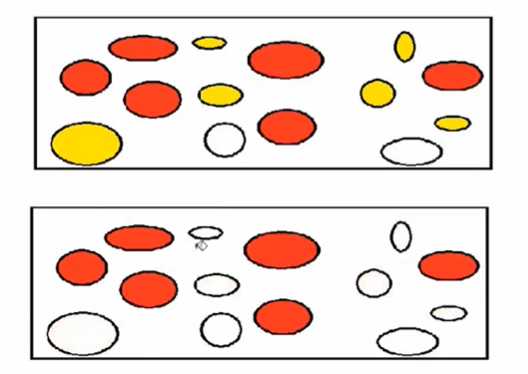
被标记的黑色就是需要回收的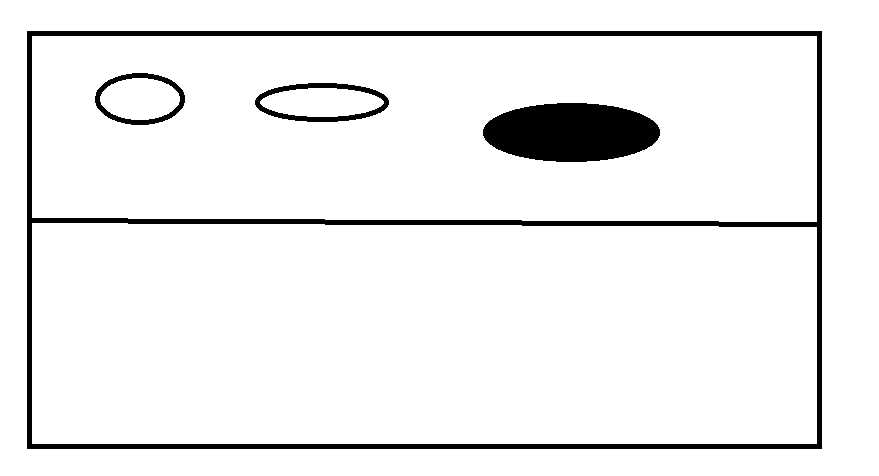
将白色区域复制下面,然后清空上面的
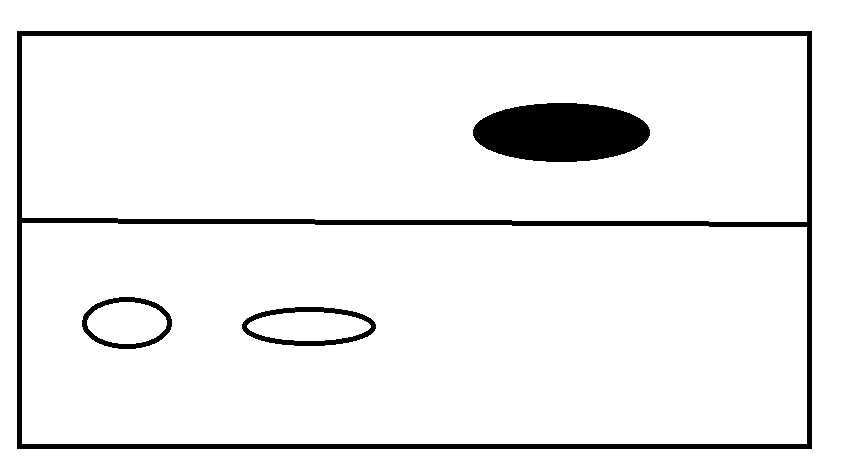
这样就完成了内存的连续分配,但是引来一个问题。
每次只能使用一半的内存。是不是有点少。。
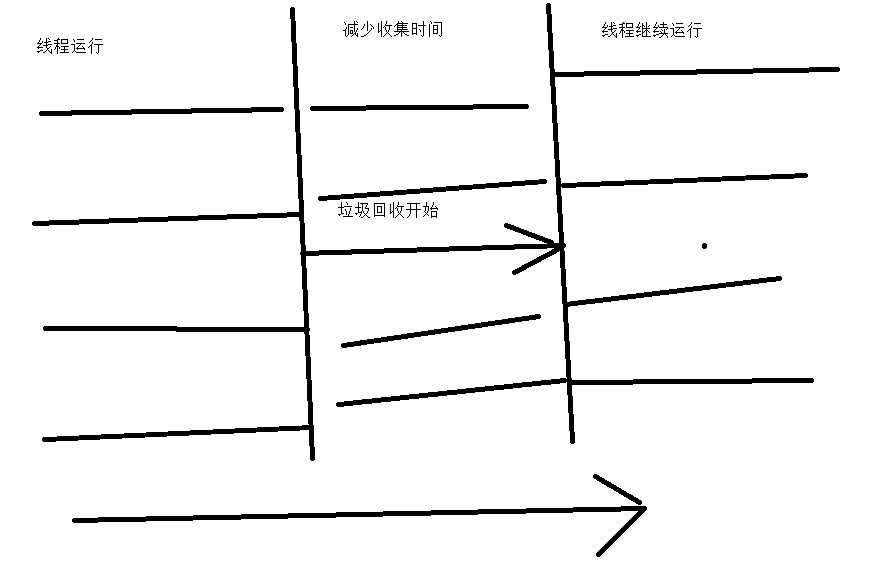
为了解决这个问题,我们对内存就进行了划分。
我们对内存分为了三块区域,survivor和Eden的内存占比为1:8。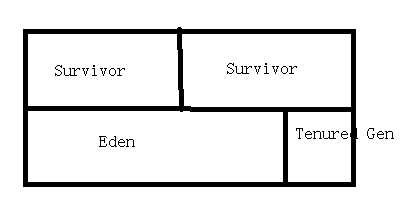
这里我们即提高了效率,又减少了内存分配。复制算法,我们需要将上面的思路,将Eden中需要回收的对象放到Survivor,然后清除。
也就是俩个Survivor中进行复制与清除。
如果Survivor不够放,那就扔到老年代里,或者其他方法,反正有内存担保。
复制算法主要针对新生代内存收集方法。
标记-整理算法主要针对的是老年代内存收集方法。
主要步骤:标记-整理-清除
如下图所示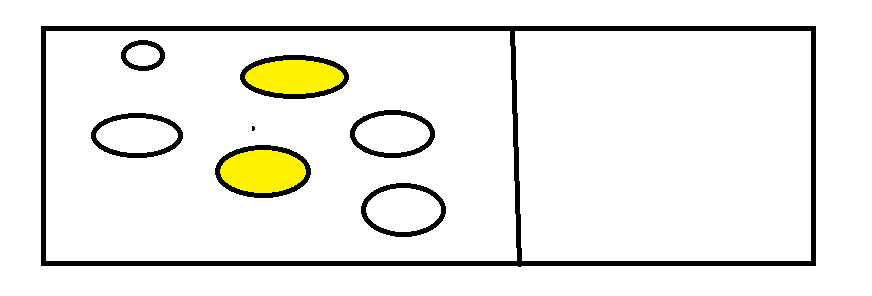
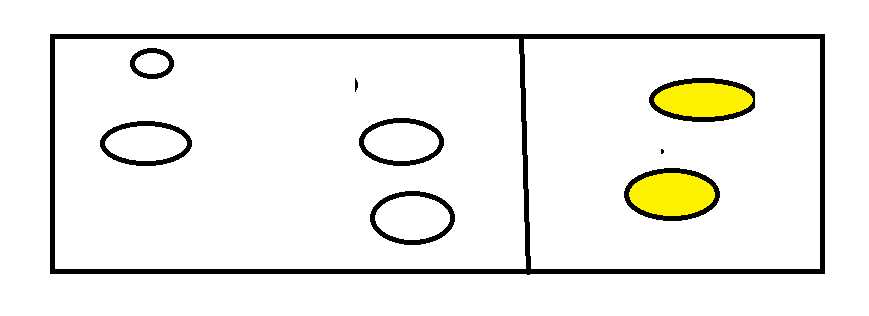
然后将右面的进行删除计科达到回收效果。
分代收集算法是根据内存的分代选择不同的算法。
对于新生代,一般选择复制算法。
对于老年代,一般选择标记-整理-清除算法。
显而易见,这是上面俩种算法的优点糅合在一起的应用。
特点:
运行机制如下所示
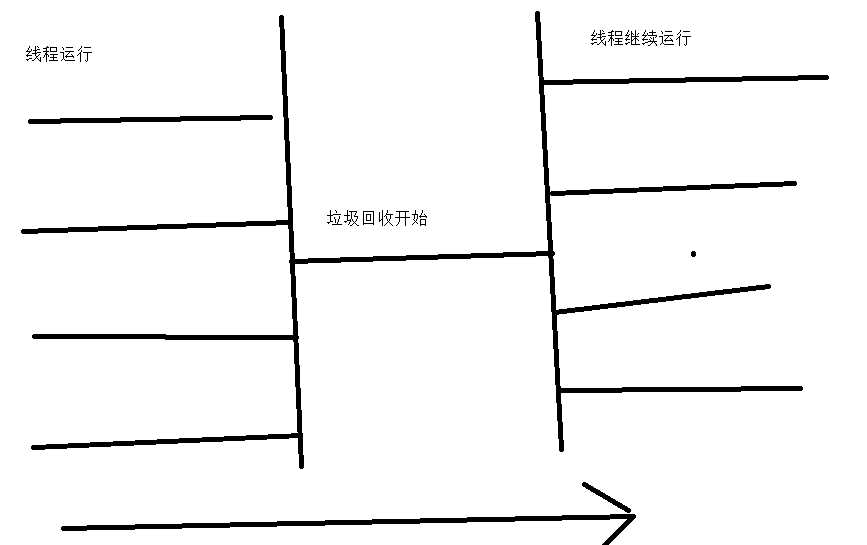
缺点:慢
用处:在客户端上运行还是比较有效。没有线程的开销,所以在客户端还是比较好用的。
特点:
实现原理都是复制算法。
缺点:
主用算法:复制算法(新生代收集器)
吞吐量 = (执行用户代码消耗的时间)/(执行用户代码的时间)+ 垃圾回收时所占用的时间
优点:吞吐量优化(CPU用于运行用户代码的时间与CPU消耗的总时间的比值)
关于控制吞吐量的参数如下
-XX:MaxGCPauseMills #垃圾收集器的停顿时间
-XX:GCTimeRatio #吞吐量大小
当停顿时间过小时,内存对应变小,回收的频率增大。因此第一个参数需要设置的合理才比较好。
第二个参数值越大,吞吐量越大,默认是99,(垃圾回收时间最多只能占到1%)
总的来说:客户端可用,服务端最好不用。
采用算法:标记清除算法。
CMS是一个并发的收集器。
目标是:减少延迟,增加响应速度
执行效果如下所示:
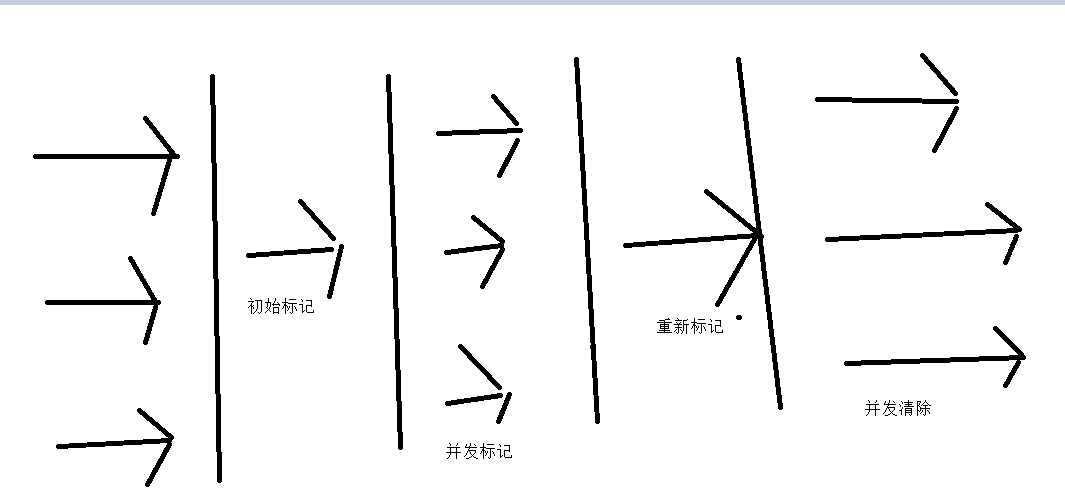
最牛的垃圾收集器。
原文:https://www.cnblogs.com/jvStarBlog/p/11566950.html