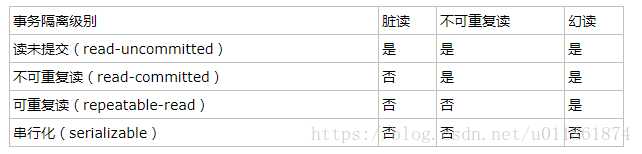
1.事务的隔离级别以及其区别
数据库在并发的情况下,可能会出现脏读,不可重复读,幻读等问题,为了避免以上问题,数据库事务增加隔离级别,来保证数据的准确性。隔离界别从低到高有四个级别:未提交读,提交读,可重复读,序列化

2.MyBatis的好处
1.与JDBC相比,减少了50%以上的代码量
2.MyBatis是最简单的持久化框架,小巧且易学
3.Mybatis灵活,SQL写在XML中,从程序代码中车底分离,降低耦合度,便于统一管理和优化,可重用
4.支持编写动态SQL语句
5.支持对象与数据库的ORM字段关系映射
3.MyBatis的缓冲池的优缺点
4.IOC是什么
IOC是Inversion of Control的缩写,控制反转。是Spring的核心,对于Spring框架来说,就是有Spring来负责控制对象的声明周期和对象间的关系,IOC的一个重点是在系统运行中,动态的向某个对象提供他所需要的其他对象。这个点是通过DI Dependency Injection,依赖注入来实现的,IOC的实现过程,可以划分为两个阶段
1.容器启动阶段:加载配置,分配配置信息,装配到BeanDefinition
2.Bean实例化阶段:实例化对象,装配依赖,生命周期回调,对象其他处理,注册回调接口
常用的两种注入方式 :
构造方式注入,这种注入方式的优点,对象在构造完成之后,即已进入就绪状态,可以马上使用,缺点是,当依赖对象比较多的时候,构造方法的参数列表会比较长,而通过反射构造对象的时候,对相同类型学的参数的处理会比较困难,维护和使用上也比较麻烦。而且在Java中,构造方法无法被继承,无法设置默认值,对于非必须的依赖处理,可能需要引入多的构造方法
setter方法注入,因为方法可以命名,所以setter方法注入在描述性要比构造方法注入好些,另外 setter方法可以被继承,运行设置默认值,而且有良好的IDE支持。缺点是对象无法在构造完成后进入就绪状态
Spring提供两种IOC容器:
BeanFactory:基础类型IOC容器,提供完整的IOC服务支持,如果没有特殊指定,默认采用延迟初始化政策。只有当客户端对象需要访问容器中的某个受管对象的时候,才对该受管对象进行初始化以及依赖注入操作。所以,相对来说,容器启动初期速度较快,所需要的资源有限。对资源有限,并且资源有限,并且功能要求不是很严格的场景,BeanFactory是比较合适的IOC容器
ApplicationContext。在BeanFactory基础上构建,是相对比较高级的容器实现,除了拥有BeanFactory的所有支持,还提供其他高级特性,比如时间发布,国际化信息支持等,ApplicationContext所管理的对象,在该类型容器启动之后,默认全部初始化并绑定完成,所以比BeanFactory要求更多的系统资源,启动时间略长,适合系统资源充足,要求更多功能的场景
5.Spring中增强的实现方
6.CGLIB和动态代理的区别
java动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理
cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理
1.如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
2.如果目标对象实现了接口,可以强制CGLIB实现AOP
3.如果目标对象没有实现了接口,必须此阿勇CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换
JDK动态代理和CGLIB字节码生成的区别
(1)JDK动态代理只能对实现了接口的类生成代理,而不能针对类
(2)CGLIB是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法,因为是继承,所以该类或方法最好不要声明成final
7.SpringBoot和Spring的区别
Spring Boot可以建立独立的Spring应用程序;
内嵌了如tomcat,jetty 和Undertow这样的容器,也就是说可以直接跑起来,用不着再做部署工作了。
无需再像Spring那样搞一堆繁琐的xml文件的配置
可以自动配置Spring
提供了一些现有的功能,如量度工具,表单数据验证以及一些外部配置这样的一些第三方功能
提供的POM可以简化Maven的配置
8.Redis怎么实现高并发
Redis通过主从架构,实现读写分离,主节点负责写,并将数据同步给其他从节点,从节点负责读,从而实现高并发
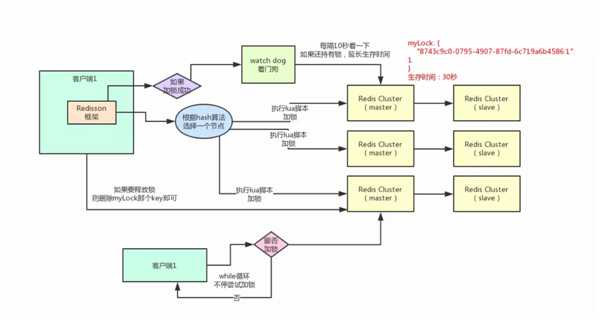
9.Redis分布式锁
10.JDBC是什么
JDBC代表Java数据库连接(Java Data Base Connectivity)它是用于java编程语言和数据库之间的数据库无关连接的标准Java api 换句话说 JDBC是用于在Java语言编程中与数据库连接的api
11.Java怎么实现多线程
3种方法:
继承Thread类
实现Runnable接口
实现Callable接口
比较:
实现Runnable接口相比继承Thread类有如下优势
1.可以避免由于Java的单继承性而带来的局限
2.增强程序的健壮性,代码能够被多个线程共享,代码域数据是独立的
3.适合多个相同程序代码的线程去处理统一资源的情况
4.线程池只能放入事先Runnable或Callable类线程,不能直接放入继承Thread类
实现Runnable接口和实现Callable接口的区别
1.实现Callable接口的任务线程能返回执行结果,而实现Runnable接口的任务线程不能返回结果
2.Callable接口的call方法允许抛出异常,而Runnable接口的run方法的异常只能内部消化
3.加入线程池运行,Runnable使用ExecutorService的execute方法,Callable使用submit方法 注:Callable接口支持返回执行结果,此时需要调用FutureTask.get()方法实现,此方法会阻塞主线程知道获取返回结果,当不调用此方法,主线程不会阻塞
12.线程的生命周期
新建(new),就绪(runnable),运行(running),阻塞(blocking),死亡(Dead)
13.Java的集合类有哪些
集合类主要负责报春,盛装其他数据,因此有将集合类称为容器类,本质是一种数据
结构,Java集合类通常分为Set,List,Map,Queue四大体系,Set代表无序的,不允许有重复元素的集合,List代表有序的,允许有重复元素的集合,Map代表具有映射关系的集合,Queue代表队列结合,Java集合类主要由两个接口派生来的Collection接口和Map接口
14.队列有哪些
Queue:基本上,一个队列就是一个先入先出的数据结构
阻塞队列 :
LinkedList:继承Deque
PriorityQueue:优先队列,使用的是最小堆的数据结构,堆元素进行了指定排序,不许插入控制,实现了AbstractQueue抽象类和Queue接口
ConcurrentLinkedQueue:基于链接节点的,数据安全的队列,实现了AbstractQueue抽象类和Queue接口
非阻塞队列
ArrayBlockingQueue:一个由数组支持的有界队列
LinkedBlockingQueue:一个由链接节点支持的可选有界队列
PriorityBlockingQueue:一个由优先级堆支持的无界优先级队列
DelayQueue:一个由优先级堆支持的,基于时间的调度队列
SynchronousQueue:一个利用BlockingQueue接口的简单聚集机制
15.LinkedList和ArrayList的区别
ArrayList和LinkedLis都是接口的实现类,因此都实现了list所有未实现的方法,知识实现的方式有所不同
ArrayList实现了List接口,它是以数组的方式来实现的,数组的特性是可以使用所有的方式来快速定位对象的位置,因此对于快速随机取得对象的需求,使用ArrayList实现执行效率上会比较好
LinkedLIst是采用链表的方式来实现List接口的,它本身有自己特定的方法addFirst,addLast,getFirst,removeFirst由于采用链表实现的,因此在进行insert和remove动作时在效率上要比ArrayLIst要好很多,适合实现堆栈和队列
16.设计模式有哪些
设计模式分为三大类
创建型模式:工厂方法模式,抽象工厂模式,单例模式,建造者模式,原型模式
结构型模式:适配器模式,装饰器模式,代理模式,外观模式,桥接模式,组合模式,享元模式
行为型模式:策略模式,模板方法模式,观察者模式,迭代子模式,责任链模式,命令模式,备忘录模式,状态模式,访问者模式,中介者模式,解释器模式
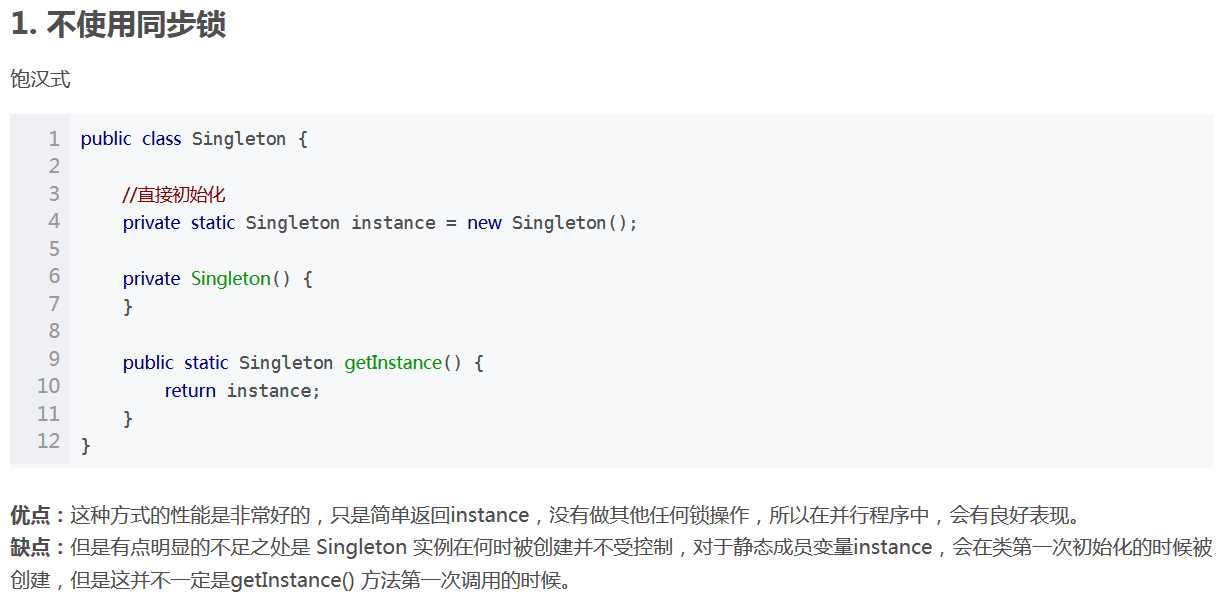
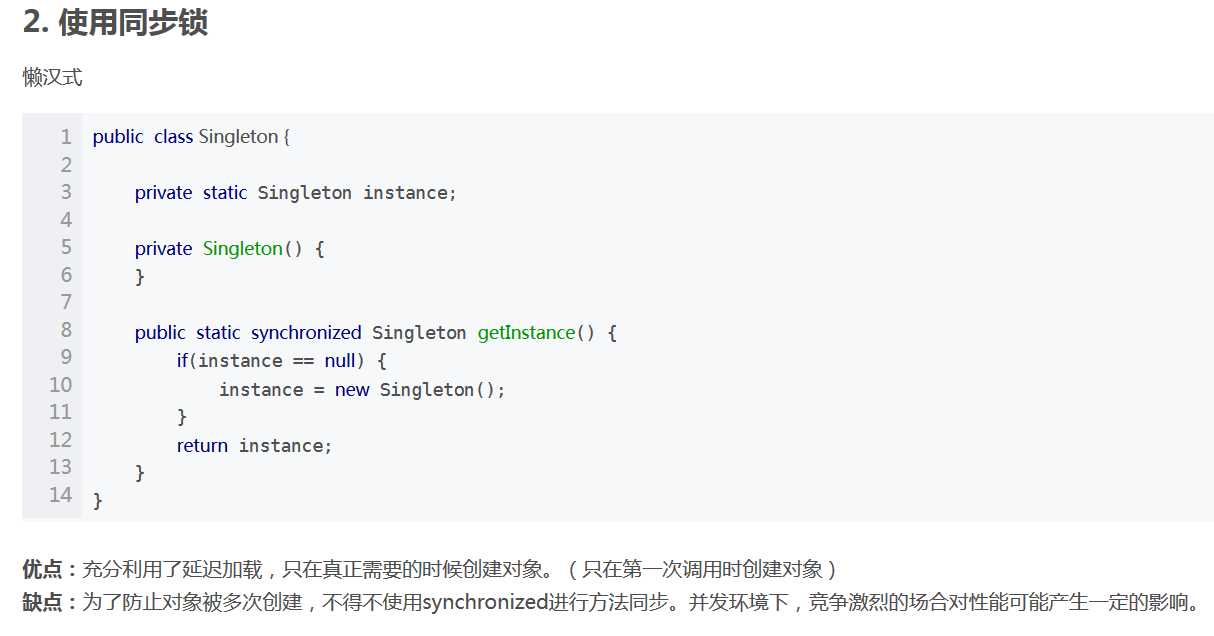
17.单例模式要注意的点和要怎么创建线程安全的单例
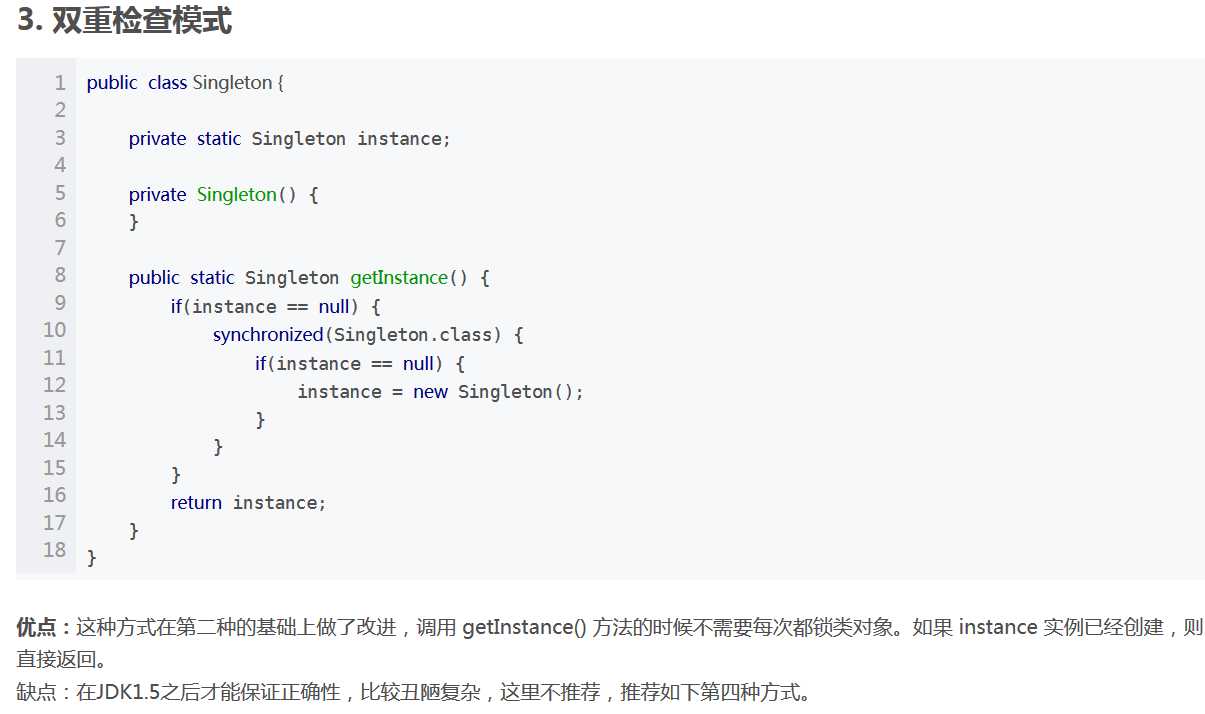

18.装饰者模式是什么?Java有没有这样的类和库
装饰器模式以客户端透明的方式扩展对象的功能
在装饰器模式中的角色有:
抽象构建角色:给出一个抽象接口,已规范准备接收附加责任的对象
具体构建角色:定义一个将要接收附加责任的类
装饰角色:持有一个构建对象的实例,并定义一个抽象构件接口一致的接口
具体装饰角色:负责给构件对象贴上附加的责任
装饰设计模式在Java I/O标准库的设计
由于JAVA I/O库需要很多性能的各种组合,如果这些性能都是用继承的方法实现的,那么每一种组合都需要一种类,这样就会造成大量性能重复的类出现。而如果采用装饰模式,那么类的数目就会大大减少,性能的重复也可以减至最小。因此装饰模式是JAVA I/O库的基本模式
19.Java里IO输入流,如文件输入流,buffer输入流是什么
20.适配器模式是什么
适配器模式将某个类的接口转换成客户端期望的另一个接口表示,主的目的是兼容性,让原本因接口不匹配不能一起工作的两个类可以协同工作。其别名为包装器(Wrapper)。
主要分三类:类适配器模式,对象的适配器模式,接口的适配器模式
使用场景:
1.系统需要使用现有的类,而这些类的接口不符合系统的需要
2.想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作。
3.需要一个统一的输出接口,而输入端的类型不可预知
21.delete truncate drop的区别
(1)DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。
TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2)表和索引所占空间。
当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小,
DELETE操作不会减少表或索引所占用的空间。
drop语句将表所占用的空间全释放掉。
(3)一般而言,drop > truncate > delete
(4)应用范围。
TRUNCATE 只能对TABLE; DELETE可以是table和view
(5)TRUNCATE 和DELETE只删除数据, DROP则删除整个表(结构和数据)。
(6)truncate与不带where的delete :只删除数据,而不删除表的结构(定义)drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
(7)delete语句为DML(data maintain Language),这个操作会被放到 rollback segment中,事务提交后才生效。如果有相应的 tigger,执行的时候将被触发。
(8)truncate、drop是DLL(data define language),操作立即生效,原数据不放到 rollback segment中,不能回滚
(9)在没有备份情况下,谨慎使用 drop 与 truncate。要删除部分数据行采用delete且注意结合where来约束影响范围。回滚段要足够大。要删除表用drop;若想保留表而将表中数据删除,如果于事务无关,用truncate即可实现。如果和事务有关,或老师想触发trigger,还是用delete。
(10) Truncate table 表名 速度快,而且效率高,因为:
truncate table 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
(11) TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
(12) 对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
22.数据库连接中各种连接的意思
1.内连接
结果: 从左表中取出每一条记录,去右表中与所有的记录进行匹配; 匹配必须是某个条件是左表中与右表中相同,才会保留结果,否则不保留;
1.等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
2.不等值连接:在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值
基本语法:左表 [inner] join 右表 on 左表.字段 = 右表.字段
2. 外连接
结果:以某张表为主,取出里面的所有记录, 然后每条与另外一张表进行连接, 不管能不能匹配上条件,最终都会保留, 能匹配,正确保留; 不能匹配其他表的字段都置空null
1.左联接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL
2.右连接:是以右表为基准,将a.stuid = b.stuid的数据进行连接,然以将右表没有的对应项显示,左表的列为NULL
基本语法:左表 left/right join 右表 on 左表.字段 = 右表.字段;‘
3. 交叉连接
结果:交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
4. 自然连接
结果:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。
23.数据库调优
24.数据库索引类型
index ----普通的索引,数据可以重复
fulltext----全文索引,用来对大表的文本域(char,varchar,text)进行索引。语法和普通索引一样。
unique ----唯一索引,唯一索引,要求所有记录都唯一
primary key ----主键索引,也就是在唯一索引的基础上相应的列必须为主键
25.ACID的含义
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
ACID是Atomic(原子性)
Consistency(一致性)
Isolation(隔离性)
Durability(持久性)
Atomic(原子性):指整个数据库事务是不可分割的工作单位。只有使据库中所有的操作执行成功,才算整个事务成功;事务中任何一个SQL语句执行失败,那么已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。
Consistency(一致性):指数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。例如对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNTS表中Tom和Jack的存款总额为2000元。
Isolation(隔离性):指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。
Durability(持久性):指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
26.悲观锁乐观锁的实现
一、乐观锁
总是认为不会产生并发问题,每次去取数据的时候总认为不会有其他线程对数据进行修改,因此不会上锁,但是在更新时会判断其他线程在这之前有没有对数据进行修改,一般会使用版本号机制或CAS操作实现。
version方式:一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
CAS操作方式:即compare and swap 或者 compare and set,涉及到三个操作数,数据所在的内存值,预期值,新值。当需要更新时,判断当前内存值与之前取到的值是否相等,若相等,则用新值更新,若失败则重试,一般情况下是一个自旋操作,即不断的重试。
一、悲观锁
总是假设最坏的情况,每次取数据时都认为其他线程会修改,所以都会加锁(读锁、写锁、行锁等),当其他线程想要访问数据时,都需要阻塞挂起。可以依靠数据库实现,如行锁、读锁和写锁等,都是在操作之前加锁,在Java中,synchronized的思想也是悲观锁。
27.死锁的条件
死锁产生的4个必要条件
1、互斥:某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。
2、占有且等待:一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源。
3、不可抢占:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
4、循环等待:存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
当以上四个条件均满足,必然会造成死锁,发生死锁的进程无法进行下去,它们所持有的资源也无法释放。这样会导致CPU的吞吐量下降。所以死锁情况是会浪费系统资源和影响计算机的使用性能的。那么,解决死锁问题就是相当有必要的了。
原文:https://www.cnblogs.com/ashin1997/p/11560286.html