\begin{aligned}
P(C|F)=\frac{P(F|C)P(C)}{\sum_iF_i}=\frac{\prod_iP(F_i|C)P(C)}{\sum_iF_i}
\end{aligned}
选择最优的划分特征。每次划分后的分支节点所包含的样本尽可能的属于同一类别,也就是节点中所包含的样本纯度越来越高。
如何评判纯度?
如何衡量\(H(x)\)的大小
需要构造一个关于\(H(x)\)的函数满足上述关系:\(H(x)=log \frac{1}{P(x)}=-logP(x)\)
熵求的是\(H(x)\)在\(P(x)\)分布下的数学期望,代表一个系统的不确定性,信息熵越大,不确定性越大。
\begin{aligned}
Entropy(x) = E_x[H(x)]=-\sum_xP(x)logP(x)
\end{aligned}
Information Gain(IG)
\begin{aligned}
IG=OriginalEntropy - \sum_i \frac{A_i}{|A|}Entropy(A_i)
\end{aligned}
信息熵是系统的不确定度,信息增益代表划分后系统的不确定度减少的程度。
每次划分希望信息增益越大越好。
采用 Information Gain 作为纯度的度量,算每一个特征的信息增益,选择使得信息增益最大的特征进行划分。
贝叶斯分类模型适用离散无序类型(discrete)的特征
除了熵,还有其他方式来指导决策树划分。
\begin{aligned}
GINI(t)=1-\sum_jP(j|t)^2
\end{aligned}
\(P(j|t)\):每个状态\(t\)里每个class\(j\)的频率
比较容易算,不用计算log。
划分\(k\)个分区,计算各个分区的加权 GINI 指数
对应信息增益
\begin{aligned}
GINI_{split}=\sum_{i=1}^k\frac{n_i}{n}GINI(i)
\end{aligned}
GINI划分越小越好
错分率
\begin{aligned}
Error(t)=1-max_iP(i|t)
\end{aligned}
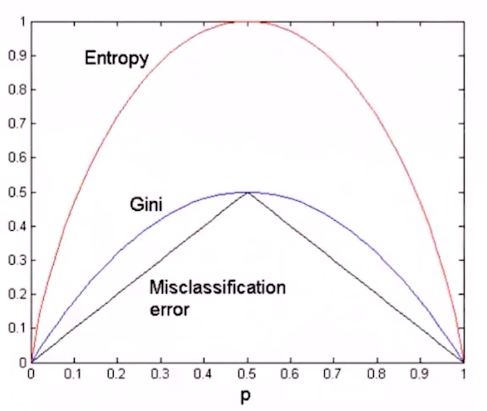
训练决策树时什么时候该停止,停止过早,没有很好学习数据性能,停止过晚,过拟合现象。
Tree Ensemble 集成学习
numbers of nodes: complexity of model
预测回归连续型数据。
给定训练数据 \(D={(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(N)},y^{(N)})}\),希望学习一个CART树来最小化损失函数
\begin{aligned}
Loss = min_{j,s}[min_{C_1}L(y^i,C_1)+min_{C_2}L(y^i,C_2)] \newline
where \quad C_m=ave(y_i|x_i \in R_m)
\end{aligned}
很好做并行
Bagging 算法可与其他分类、回归算法结合,提高准确率、稳定性的同时,通过降低结果的方差,避免过拟合的发生。
Bootstrap 是统计学里一种采样方法。自身有放回式采样。
对CART树使用 Bagging 算法,生成的许多树组成随机森林。
给出训练数据\(D={(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(N)},y^{(N)})}\),\(x^{(i)}\in R^n\),\(y \in \left\{ +1,-1 \right\}\)。对每一个\(x^{(i)}\),有一个相应的权重\(w^{(i)} \in R\)(标量)
\begin{aligned}
w=(w^{(1)},w^{(2)},...,w^{(N)})\newline w^{(i)}=\frac{1}{N},\quad i=1,2,...,N
\end{aligned}
\(G_k(x)\)是一个弱分类器(朴素贝叶斯、决策树)
\begin{aligned}
e_k=P(G_k(x^{(i)})不等于 y^{(i)})\newline =\sum_iw^{(i)}I (G_k(x^{(i)}不等于 y^{(i)} )
\end{aligned}
Boosting需要逐个训练弱分类器,1)数据权重初始化 。2)根据每一个弱分类器的误差来算数据的新权重,分错了权重增加,分对了权重减少。3)将要分类的数据输入到每一个弱分类器,由每一个若分类器的加权结果得出最终结果。
boosting的思想:分类器对分对了的保留,分错了的在下一个分类器加强学习。每次都在调整残差。
Gradient Boosting: 每一次建立模型是在之前建立模型损失函数的梯度下降方向.
有损失函数就会有梯度
在函数空间求梯度
\begin{aligned}
F_{m+1}(x) = F_{m}(x)+h(x)
\end{aligned}
我们的目标是学习一个\(h(x^{(i)})\):
\begin{aligned}
F_{m+1}(x^{(i)})=F_{m}(x^{(i)})+h(x^{(i)})=y^{(i)}
\end{aligned}
\begin{aligned}
\widehat F(x)=argminE_{x,y}[L(y,F(x))]
\newline
F(x)=\sum_{i=1}^M \alpha_ih_i(x)
\newline
F_0(x)=argmin_C\sum_{i=1}^NL(y^{(i)},C)
\newline
F_m(x)=F_{m-1}(x)+argmin\sum_{i=1}^N[L(y^{(i)},F_{m-1}(x^{(i)})+h_m(x^{(i)}))
\end{aligned}
\begin{aligned}
r_m^{(i)}=-[\frac{\partial L(y^{(i)},F(x^{(i)}))}{\partial F(x^{(i)})}]
\end{aligned}
原文:https://www.cnblogs.com/ColleenHe/p/11564768.html