给参数增加惩罚项,达到简化假设函数,降低过拟合的目的
\[ J(\theta)=\frac{1}{2 m}\left[\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^{2}+\lambda \sum_{j=1}^{n} \theta_{j}^{2}\right]\tag{5.1} \]
右边加的项称为正则化项,\(\lambda\)称为正则化参数,有两个目标
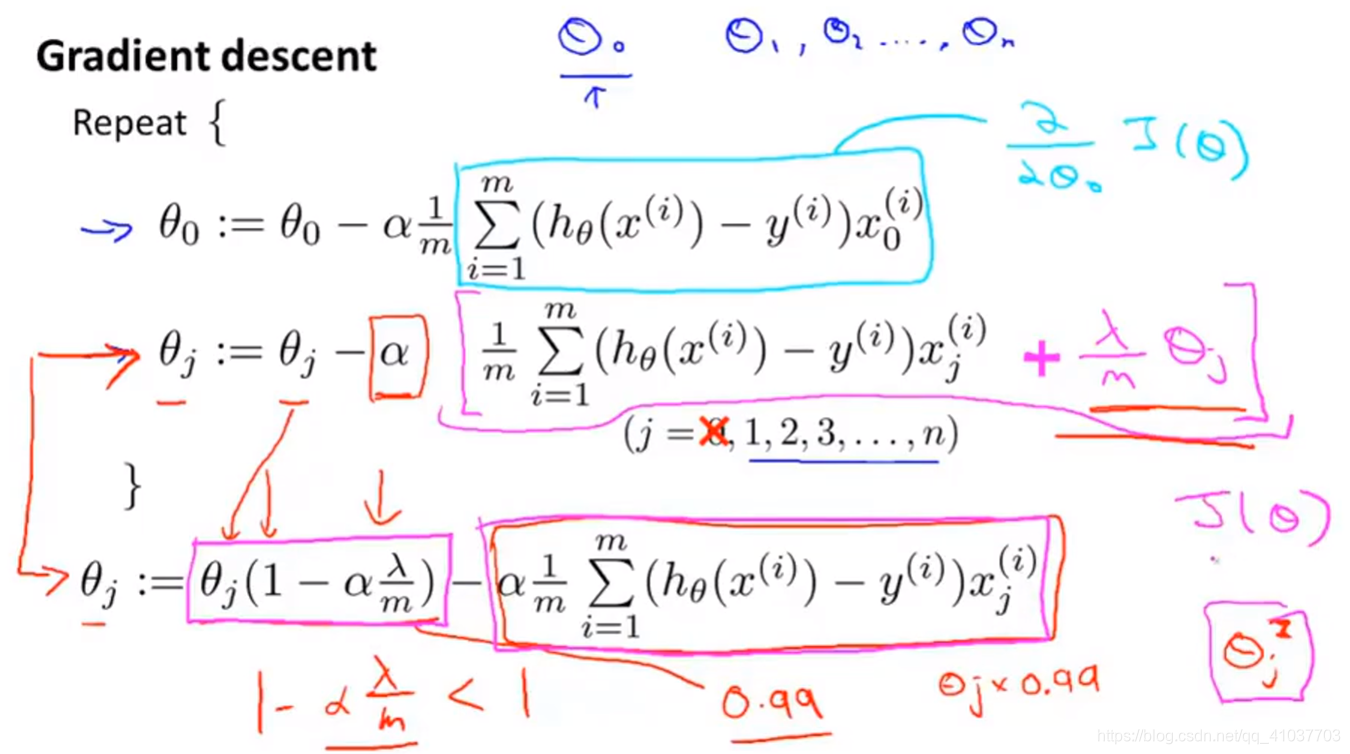
学习率\(\alpha\)很小,样本量m很大,因此正则化即每次将参数向0方向缩小一点
\[ \theta=\left(X^{T} X+\lambda\left[\begin{array}{cccc}{0} \\ {} & {1} \\ {} & {} & {1} \\ {} & {} & {} & {\ddots} \\ {} & {} & {} & {1}\end{array}\right]\right)^{-1} X^{T} y\tag{5.2} \]
其中加入的矩阵为(n+1)×(n+1)维
\[ \begin{aligned} J(\theta)=-[\frac{1}{m}\sum_{i=1}^{m} y^{(i)} \log h_{\theta}(x^{(i)})+(1-y^{(i)}) \log (1-h_{\theta}(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^{n}\theta_j^2 \end{aligned}\tag{5.3} \]


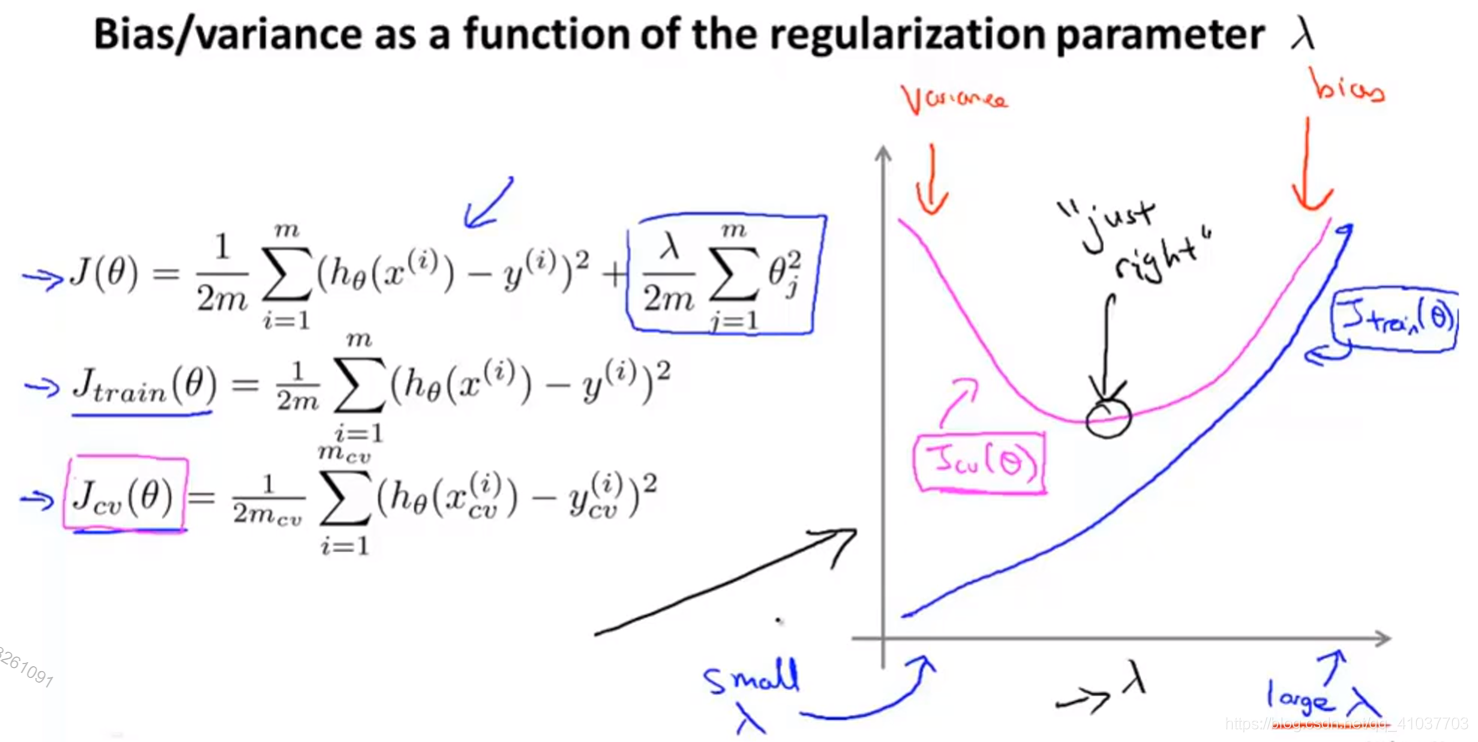
\(\lambda\)越大,训练集和验证集的偏差越大,\(\lambda\)越小,训练集的误差越小,验证集的方差越大
原文:https://www.cnblogs.com/jestland/p/11548491.html