在使用SQL时,大都会遇到这样的问题,你Update一条记录时,需要通过Select来检索出其值或条件,然后在通过这个值来执行修改操作。
但当以上操作放到多线程中并发处理时会出现问题:某线程select了一条记录但还没来得及update时,另一个线程仍然可能会进来select到同一条记录。
一般解决办法就是使用锁和事物的联合机制:
如:
1. 把select放在事务中, 否则select完成, 锁就释放了
2. 要阻止另一个select , 则要手工加锁, select 默认是共享锁, select之间的共享锁是不冲突的, 所以, 如果只是共享锁, 即使锁没有释放, 另一个select一样可以下共享锁, 从而select出数据
BEGIN TRAN
SELECT * FROM table WITH(TABLOCKX)
或者 SELECT * FROM table WITH(UPDLOCK, READPAST) 具体情况而定。
UPDATE ....
COMMIT TRAN
锁描述:
HOLDLOCK:将共享锁保留到事务完成,而不是在相应的表、行或数据页不再需要时就立即释放锁。HOLDLOCK 等同于 SERIALIZABLE。
NOLOCK 不要发出共享锁,并且不要提供排它锁。当此选项生效时,可能会读取未提交的事务或一组在读取中间回滚的页面。有可能发生脏读。仅应用于 SELECT 语句。
PAGLOCK:在通常使用单个表锁的地方采用页锁。
READCOMMITTED:用与运行在提交读隔离级别的事务相同的锁语义执行扫描。默认情况下,SQL Server 2000 在此隔离级别上操作。
READPAST:跳过锁定行。此选项导致事务跳过由其它事务锁定的行(这些行平常会显示在结果集内),而不是阻塞该事务,使其等待其它事务释放在这些行上的锁。 READPAST 锁提示仅适用于运行在提交读隔离级别的事务,并且只在行级锁之后读取。仅适用于 SELECT 语句。
READUNCOMMITTED:等同于 NOLOCK。
REPEATABLEREAD:用与运行在可重复读隔离级别的事务相同的锁语义执行扫描。
ROWLOCK:使用行级锁,而不使用粒度更粗的页级锁和表级锁。
SERIALIZABLE:用与运行在可串行读隔离级别的事务相同的锁语义执行扫描。等同于 HOLDLOCK。
TABLOCK:使用表锁代替粒度更细的行级锁或页级锁。在语句结束前,SQL Server 一直持有该锁。但是,如果同时指定 HOLDLOCK,那么在事务结束之前,锁将被一直持有。
TABLOCKX 使用表的排它锁。该锁可以防止其它事务读取或更新表,并在语句或事务结束前一直持有。
UPDLOCK:读取表时使用更新锁,而不使用共享锁,并将锁一直保留到语句或事务的结束。UPDLOCK:的优点是允许您读取数据(不阻塞其它事务)并在以后更新数据,同时确保自从上次读取数据后数据没有被更改。
XLOCK:使用排它锁并一直保持到由语句处理的所有数据上的事务结束时。可以使用 PAGLOCK 或 TABLOCK 指定该锁,这种情况下排它锁适用于适当级别的粒度。
————————————————
跟我对锁的疑惑差不多,就是,如何锁定一条记录,防止并发
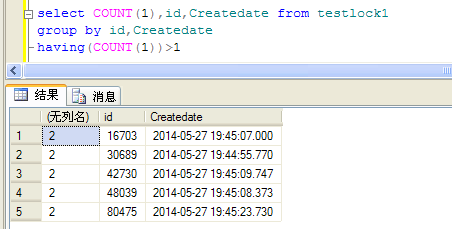
说是存储过程插入了两条相同的记录,
存储过程的脚本如下:
ALTER PROC [dbo].[Insert] @Tid IntASBEGIN IF NOT EXISTS(SELECT 1 FROM Table WHERE TId = @Tid) BEGIN INSERT INTO Table (INSERTDATE,TID ) VALUES (GETDATE(), @Tid); ENDENDif exists(select 1 from sys.objects where type=‘U‘ and name =‘testlock1‘) drop table testlock1--建表create table testlock1( id int, Createdate datetime,)--建立索引create index index_1 on testlock1(id)--建立存储过程插入数据create proc ups_TestLock@i intasbegin begin try begin tran if not exists(select 1 from t where id=@i ) begin insert into testlock1 values (@i,GETDATE()); end commit end try begin catch rollback end catchend|
1
2
3
|
declare @i intset @i=cast( rand()*100000 as int)--生成一个100000以内的随机数exec test_p @i |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
alter proc ups_TestLock@i intasbegin begin try begin tran if not exists(select 1 from t with(xlock,rowlock) where id=@i )--注意这里加上<span style="font-family: Arial, Helvetica, sans-serif;">xlock,rowlock,行级排它锁</span> begin insert into testlock1 values (@i,GETDATE()); end commit end try begin catch rollback end catchend |
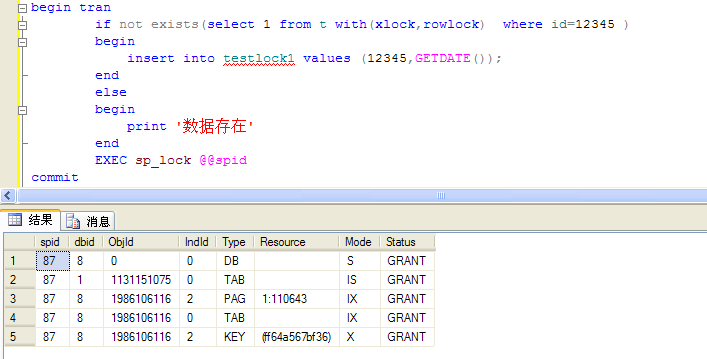
|
1
2
|
drop index index_1 on testlock1create unique index index_1 on testlock1(id) |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
if exists(select 1 from sys.objects where type=‘U‘ and name =‘testlock1‘) drop table testlock1--建表create table testlock1( id int, Createdate datetime, SessionID varchar(50))--建立索引create index index_1 on testlock1(id)alter proc ups_TestLock@i intasbegin begin try begin tran if not exists(select 1 from testlock1 with(xlock,rowlock) where id=@i ) begin insert into testlock1 values (@i,GETDATE(),@@spid);--这里插入一列回话ID end commit end try begin catch rollback end catchend |
|
1
2
3
|
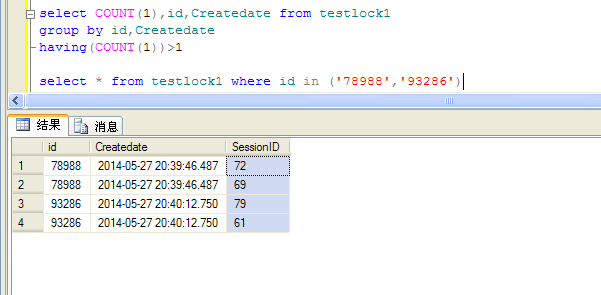
select COUNT(1),id,Createdate from testlock1group by id,Createdatehaving(COUNT(1))>1 |
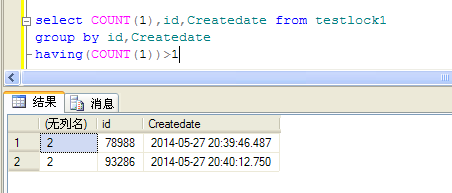
原文:https://www.cnblogs.com/Alex80/p/11505722.html