- scrapy,pyspider
- 什么是框架?如何学习框架?
- 就是一个集成了各种功能且具有很强通用性(可以被应用在各种不同的需求中)的一个项目模板.
- 我们只需要学习框架中封装好的相关功能的使用即可
- scrapy集成了哪些功能:
- 高性能的数据解析操作,持久化存储操作,高性能的数据下载的操作.....
Linux安装:
pip3 install scrapy
- whindows环境的安装:
a. pip3 install wheel

b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

c. 进入下载目录,执行 pip3 install Twisted?17.1.0?cp35?cp35m?win_amd64.whl #.whl文件安装需要wheel工具,所以要下载wheel。.whl文件在b哪个网址中
d. pip3 install pywin32
e. pip3 install scrapy
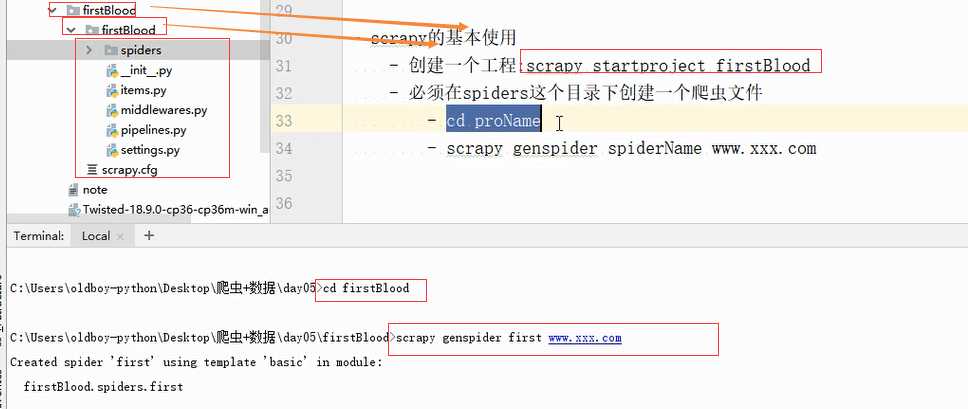
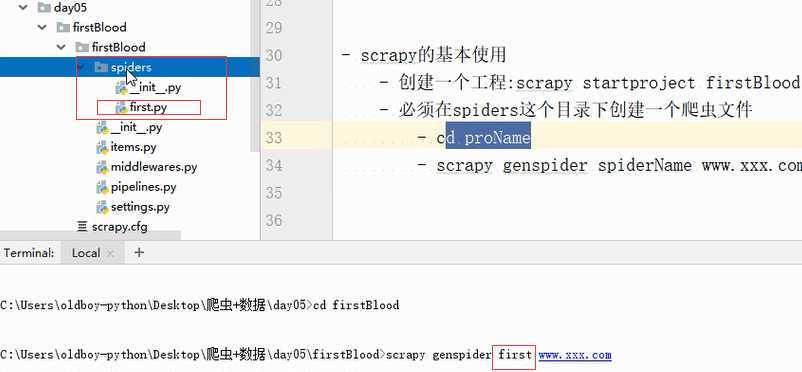
生成指定名字爬虫文件
它给我们创建的爬虫文件,里面创建了一个类,文件名加spider为类名。继承的是模块点爬虫类
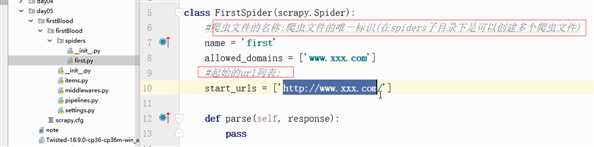
开始urls可以放多个url,允许的域名做了限定那么只能访问这个域名下的。因为我们做的是爬虫,爬取很多链接,通常都专属允许的域名。下面还有个解析方法

- 执行工程:scrapy crawl spiderName
对两个url分别进行请求,每次请求都会调用parse方法,请求的响应数据在response里面。

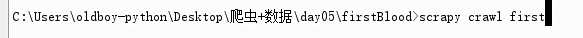
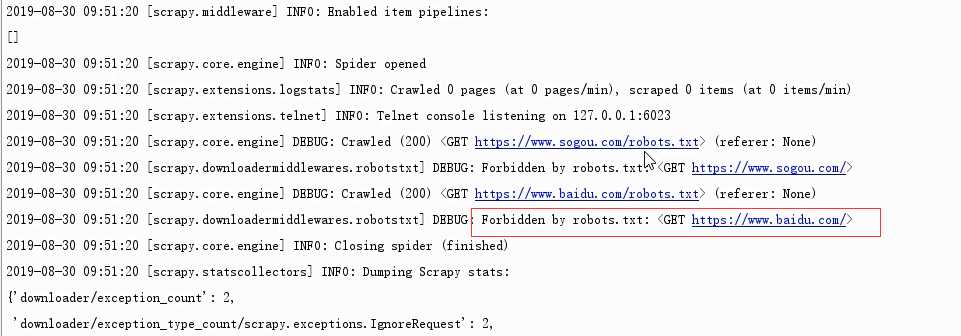
爬取之前先请求这个文件,看我们是否有权限爬取
原文:https://www.cnblogs.com/machangwei-8/p/11502604.html