本文采用clouderaManage安装了kafka、flume、和kudu。注意:在安装kudu的时候一定需要时间同步。具体的时间同步设置方法请参照:https://blog.csdn.net/u014516601/article/details/81433594。
本文kafka、flume和kudu的版本分别如下:
<flume.version>1.6.0</flume.version>
<kudu.version>1.7.0</kudu.version>
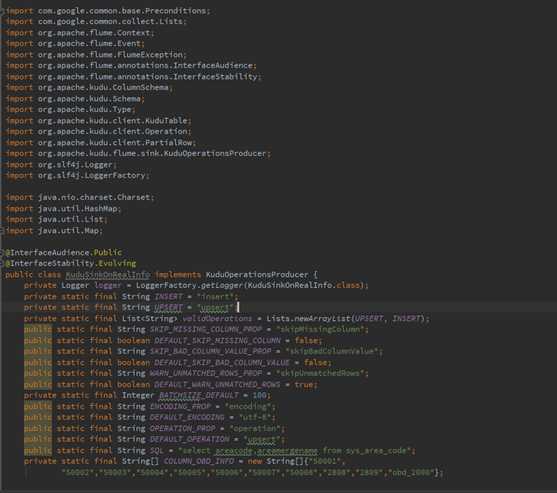
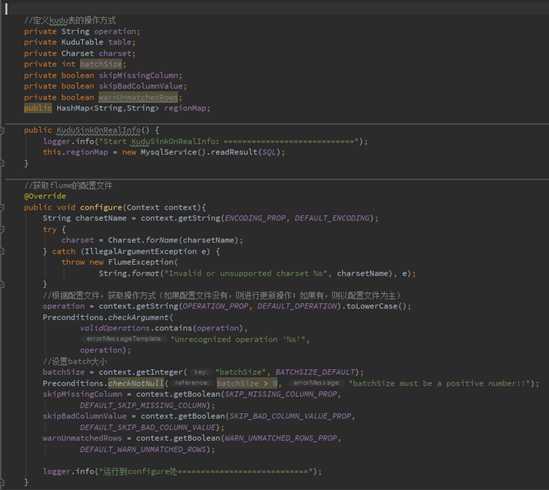
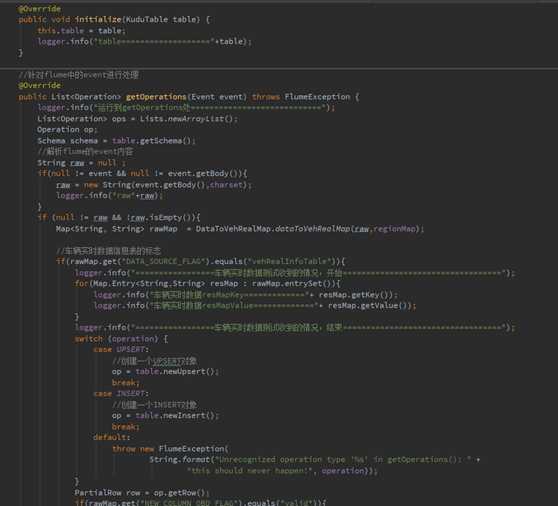
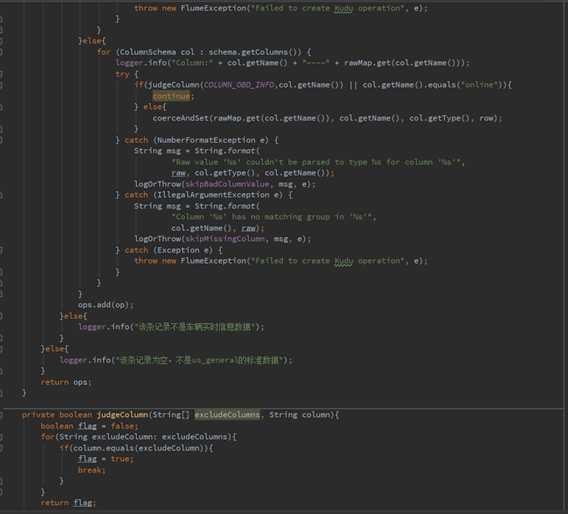

三 .编辑flume的agent文件
kafka.sources = kafkasource
kafka.sinks = kudusink1 kudusink2
kafka.channels = flumechannel1 flumechannel2
?
kafka.sources.kafkasource.type = org.apache.flume.source.kafka.KafkaSource
kafka.sources.kafkasource.zookeeperConnect = zookeeper地址:2182
kafka.sources.kafkasource.topic = us_general
kafka.sources.kafkasource.kafka.consumer.timeout.ms = 100
kafka.sources.kafkasource.kafka.consumer.group.id = flume-kudu
kafka.sources.kafkasource.selector.type = replicating //本次采用多路复用
kafka.sources.kafkasource.channels = flumechannel1 flumechannel2
?
kafka.channels.flumechannel1.type = memory
kafka.channels.flumechannel1.capacity = 10000
kafka.channels.flumechannel1.transactionCapacity = 100
?
kafka.channels.flumechannel2.type = memory
kafka.channels.flumechannel2.capacity = 10000
kafka.channels.flumechannel2.transactionCapacity = 100
?
?
kafka.sinks.kudusink1.type = org.apache.kudu.flume.sink.KuduSink
kafka.sinks.kudusink1.masterAddresses = kuduMaster的地址:7051
kafka.sinks.kudusink1.tableName = impala::kududb.hisrealinfo1
kafka.sinks.kudusink1.operation = insert
kafka.sinks.kudusink1.batchSize = 50
kafka.sinks.kudusink1.producer = KuduSinkjar包
kafka.sinks.kudusink1.channel = flumechannel1
?
kafka.sinks.kudusink2.type = org.apache.kudu.flume.sink.KuduSink
kafka.sinks.kudusink2.masterAddresses = kuduMaster的地址:7051
kafka.sinks.kudusink2.tableName = impala::kududb.realinfo1
kafka.sinks.kudusink2.operation = insert
kafka.sinks.kudusink2.batchSize = 50
kafka.sinks.kudusink2.producer = KuduSinkjar包
kafka.sinks.kudusink2.channel = flumechannel2
四.执行flume_ng命令模式
flume-ng agent --conf ./flumekudu/ --conf-file $FLUME_USGENERAL_CONFIG --name kafka -Dflume.root.logger=INFO,console
注意:
基于命令模式的执行flume_ng,可能出现内存溢出的错误。这是,需要调节jdk的堆内存大小。
Kafka+flume+kudu——kafka的数据通过flume加载到kudu中
原文:https://www.cnblogs.com/tomorrow-hope/p/11492562.html